大数据 - Hive
Posted 程序员OfHome
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 - Hive相关的知识,希望对你有一定的参考价值。
构建在Hadoop之上的数据仓库,数据计算使用MR,数据存储使用HDFS
因为数据计算使用mapreduce,因此通常用于进行离线数据处理
Hive 定义了一种类 SQL 查询语言——HQL
类似SQL,但不完全相同
可认为是一个HQL-->MR的语言翻译器。
简单,容易上手
有了Hive,还需要自己写MR程序吗?
Hive的HQL表达的能力有限
迭代式算法无法表达
有些复杂运算用HQL不易表达
Hive效率较低
Hive自动生成MapReduce作业,通常不够智能;
HQL调优困难,粒度较粗
可控性差
Hive各模块组成
用户接口
包括 CLI,JDBC/ODBC,WebUI
元数据存储(metastore)
默认存储在自带的数据库derby中,线上使用时一般换为mysql
驱动器(Driver)
解释器、编译器、优化器、执行器
Hadoop
用 MapReduce 进行计算,用 HDFS 进行存储
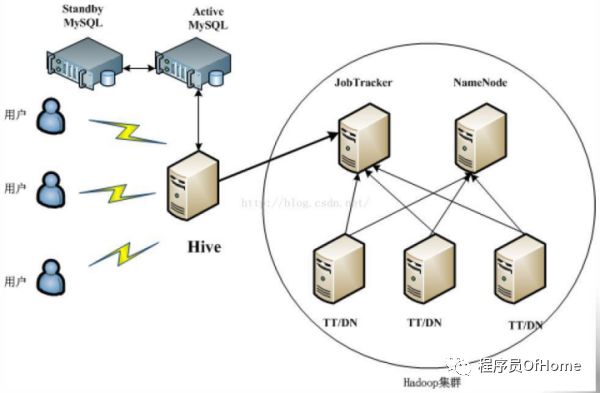
Hive部署架构-实验环境
Hive部署架构-生产环境
数据模型
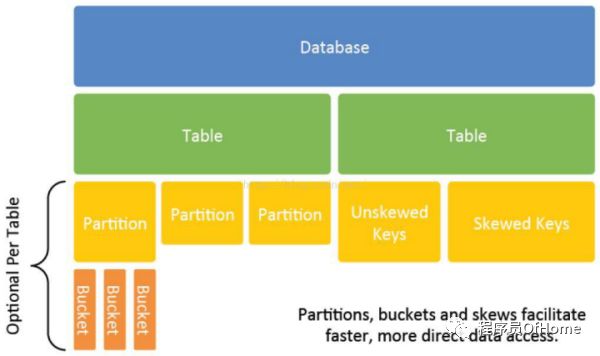
Partition 和Bucket
Partition
为减少不必要的暴力数据扫描,可以对表进行分区
为避免产生过多小文件,建议只对离散字段进行分区
Bucket
对于值较多的字段,可将其分成若干个Bucket
可结合Partition与Bucket使用
select语句
不支持having和exist in操作, 可转换为LEFT SEMI JOIN操作
Join(仅支持等值连接),不支持非等值的连接
Order by和Sort by
Order by
启动一个reduce task
数据全局有序
速度可能会非常慢
Strict模式下,必须与limit连用
Sort by
可以有多个reduce task
每个Reduce Task内部数据有序,但全局无序
通常与distribute by
Distribute by与Cluster by
distribute by
相当于MapReduce中的paritioner,默认是基于hash实现的;
与sort by连用,可发挥很好的作用
cluster by
当distribute by与sort by(降序)连用,且跟随的字段 相同时,可使用cluster by简写;
用户自定义函数UDF:扩展HQL能力的一种方式
HQL支持索引吗?
HQL执行过程主要是并行地暴力扫描。目前Hive仅支持单表索引,但提供了索引创建接口和调用方法,可由用户根据需要实现索引结构;
HQL支持update操作吗?
不支持。Hive底层是HDFS,HDFS仅支持追加操作,不支持随机写;
Skew Data处理机制?
指定skew 列:CREATE TABLE list_bucket_single (key STRING, value STRING) SKEWED BY (key) ON (1,5,6);
为skew task分配更多资源(TODO)
将skew task分解成多个task,再合并结果(TODO)
Hive On HBase
使用HQL处理HBase中的数据
比直接通过HBase API存取数据方便;
但性能更低,相当于把在线处理转为批处理
存在问题
不够成熟;
不能按时间戳获取数据,默认总是取最新的数据
Hive的类似系统
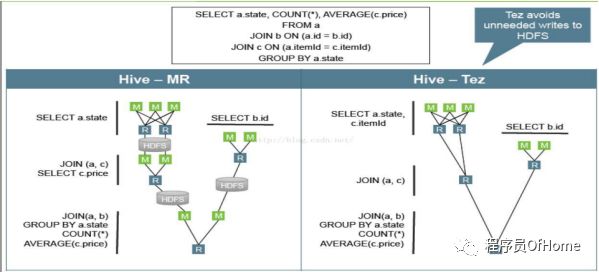
Stinger
下一代Hive被称为“Stinger”,其底层的计算引擎将由Tez替换MapReduce;
Tez相比于MapReduce具有众多优势:
提供了多种算子(比如Map、Shuffle等)供用户使用;
将多个作业合并成一个作业,减少磁盘读写IO;
充分利用内存资源。
Shark
Hive On Spark(http://spark.incubator.apache.org/);
Spark是一个内存计算框架,相比于MapReduce,效率更加高效(部分测试表明,速度快100x);
Shark完全兼容Hive,底层计算引擎采用Spark。
Impala
底层计算引擎不再采用MR,而是使用与商用并行关系数据库类似的分布式查询引擎;
性能比较大
文末福利
将来自己,一定会感谢现在自己的,现在不努力,将来只会后悔。我们不做后悔的哪个,只做最好的自己。
想从事以上工作或者往大数据方向发展的朋友,可以点击联系我们,获取大数据相关资料和高清学习线路图,希望在你发展的道路上有所帮助。
程序员OfHome交流群:610535338
以上是关于大数据 - Hive的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_18_大数据离线平台_04_数据分析 + Hive 之 hourly 分析 + 常用 Maven 仓库地址
2021年大数据Flink(三十八):Table与SQL 案例五 FlinkSQL整合Hive