Hive UDF开发
Posted 一木呈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive UDF开发相关的知识,希望对你有一定的参考价值。
1 概述
用户自定义函数(UDF) 是一个允许用户扩展HiveQL 的强大的功能。正如我们将看到的,用户使用Java 进行编码。一旦将用户自定义函数加人到用户会话中(交互式的或者通过脚本执行的),它们就将和内置的函数一样使用,甚至可以提供联机帮助。 Hive 具有多种类型的用户自定义函数,每一种都会针对输人数据执行特定“一类”的转换过程。
2 自定义函数编写
编写一个UDF,需要继承UDF 类并实现evaluate()函数。在查询执行过程中,查询中对应的每个应用到这个函数的地方都会对这个类进行实例化。对于每行输人都会调用到evaluate()函数。而evaluate()处理后的值会返回给Hive。同时用户是可以重载evaluate方法的。Hive 会像Java 的方法重载一样,自动选择匹配的方法。
2.1 pom依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
2.2 UDF编写
必须是org.apache.hadoop.hive.ql.exec.UDF的子类;
必须实现evaluate()方法;
evaluate()不是接口;该方法的参数个数类型、返回值类型都是不确定的。
@Description...表示的是Java 总的注解,是可选的。注解中注明了关于这个函数的文档说明,用户需要通过这个注解来阐明自定义的UDF 的使用方法和例子。这样当用户通过DESCRIBE FUNCTION...命令查看该函数时,注解中的_FUNC_字符串将会被替换为用户为这个函数定义的“临时”函数名称
package bonc.com.hive.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
@Description(name = "hello", value = "_FUNC_(x) - returna string concat hello",
extended = "Example: hello(\"me\") ")
public class MyUDF extends UDF{
public String evaluate(String str){
if ( str != null) {
return "hello"+str;
} else {
return null;
}
}
}打包编译
file-->project-structure-->artifacts-->+-->jar-->frommoduls with …--> 去掉不必要的依赖
编译:Build-->Build Artifacts

3 函数注册
3.1 临时注册
add jar /home/hadoop/jar/udf.jar; #添加jar文件
create temporary function hello as 'bonc.com.hive.udf.MyUDF'; #创建临时函数别名临时注册只能只当前连接下有效,任何库下都可以使用,没有向元数据库注册,hive Cli和Beeline都可以使用该方式注册。
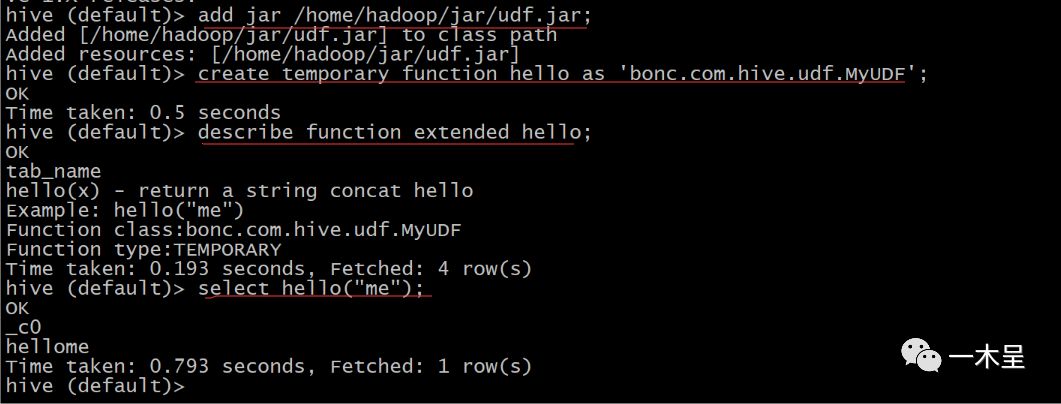
退出连接函数失效:
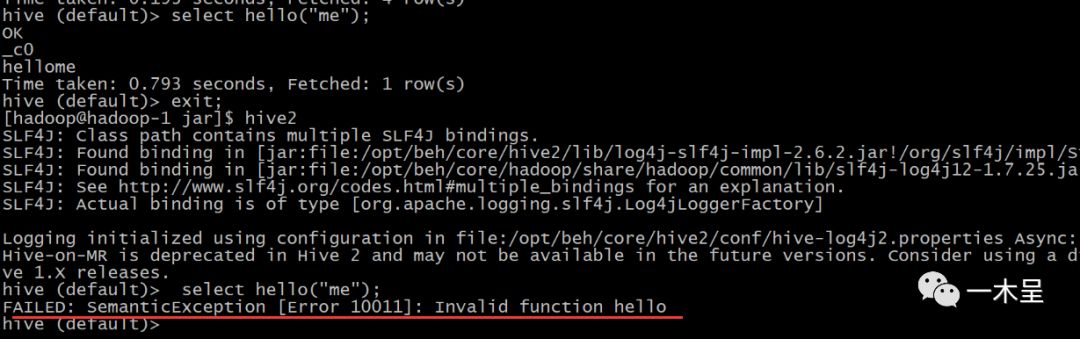
3.2 永久注册
3.2.1 Hive Cli
将udf.jar放到hive的CLASS_PATH路径下,一般$HIVE_HOME/lib下面,或者配置HIVE_AUX_JARS_PATH放在额外jar包路径下。
执行:
cp udf.jar $HIVE_HOME/lib
create function hello as 'bonc.com.hive.udf.MyUDF';
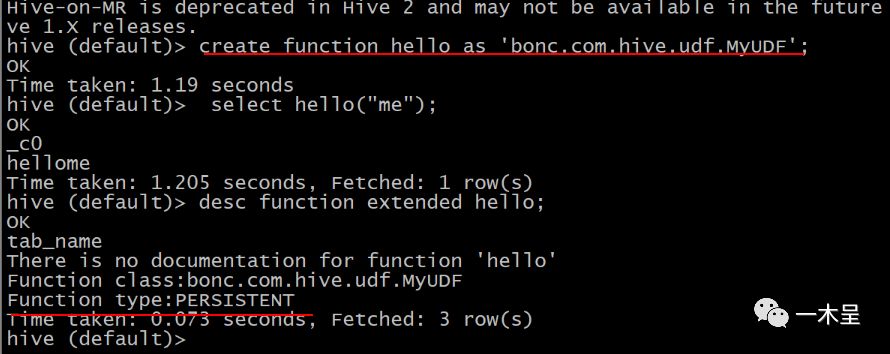
实际实在元数据库上注册该函数:

局限性:只能在注册的库下使用该函数,此函数只在default库下有效。经测试Beeline模式下不可使用。
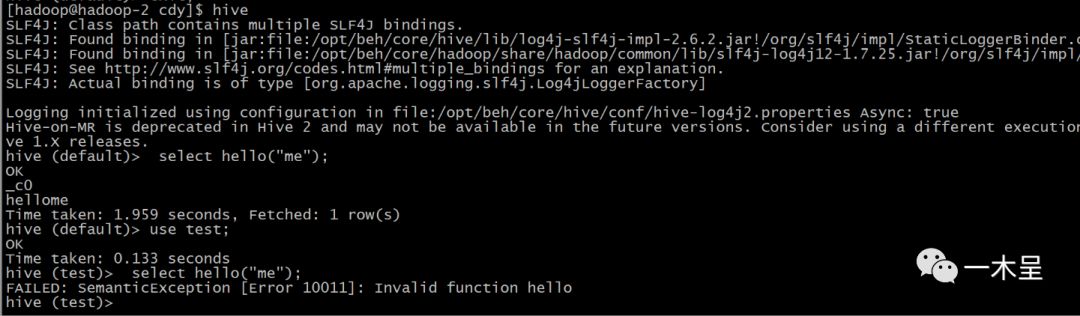
如果接口机使用该函数,需要把jar包拷贝进CLASS_PATH路径下。
3.2.2 Beeline
上述过程注册的函数在beeline下是不可使用的,我们指定jar路径注册。
CREATE FUNCTION[db_name.]function_name AS class_name [USING JAR|FILE|ARCHIVE 'file_uri' [,JAR|FILE|ARCHIVE 'file_uri'] ];
将jar包上传到hdfs上
hadoop fs –put udf.jar /jar
create function hello as "bonc.com.hive.udf.MyUDF" usingjar "hdfs://beh/jar/udf.jar";

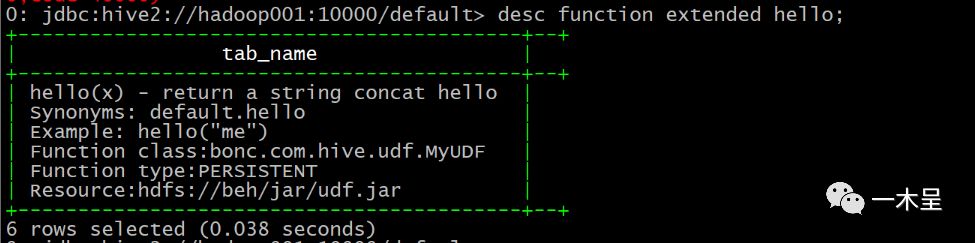
此注册方式,beeline和hiveCli模式下均可使用,但是仍然局限在库,最好在默认库下配置。
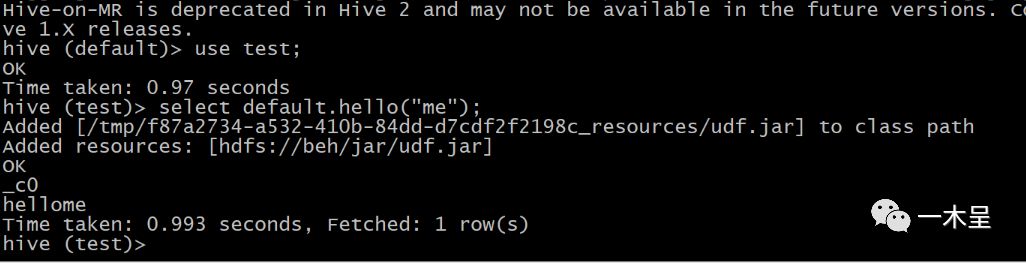
如果无法避免切库使用,采用库名.方法使用:
4 UDAF函数编写
UDAF要结合Mapper、Combiner与Reducer来帮助我们理解。用户聚合计算允许数据划分任意多个部分进行计算儿不会影响计算结果。大体上来说,UDAF函数读取数据(mapper),聚集一堆mapper输出到部分聚集结果(combiner),并且最终创建一个最终的聚集结果(reducer)因为我们跨域多个combiner进行聚集,所以我们关键在于保存部分聚集结果。
聚合过程返回的是GenericUDAFEvaluator子类对象,创建一个GenericUDAF必须先了解以下两个抽象类:
org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver
主要作用是根据输入参数返回对应的GenericUDAFEvaluator子类对象
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
UDAF逻辑处理主要发生在该子类定义的方法中。主要方法:
方法名 |
描述 |
init |
Hive会调用此方法来实例化一个UDAF evaluator类 |
getNewAggregationBuffer |
返回一个存储中间结果的对象 |
iterate |
将一行的新数据载入到聚合buffer中 |
terminatePartial |
以一种持久化的方法返回当前聚合的内容。这里所说的持久化是指返回值只可以使用Java的基本类型和array,以及基本封装类型(例如Double),Hadoop中Writable类、list和map类型,不能使用用户自定义的类(即使实现了java.io.Serializable) |
merge |
将terminatePartial返回的中间结果合并到当前聚合中 |
terminate |
放回最终结果给Hive |
过程图解:
使用UDAF时候注意内存使用问题,通过mapred.child.java.opts调整内存的需求量。
Demo:此UDAF函数返回分组后多列合并为一类,类似collect_set
package bonc.com.hive.udaf;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import java.util.ArrayList;
import java.util.List;
/**
* @ProjectName: javademo
* @Package: bonc.com.hive.udaf
* @ClassName: GroupConcat
* @Description: 返回分组后 多列变一列聚合输出
* @Author: Chendeyong
* @CreateDate: 2018/4/28 11:05
* @Version: 1.0
*/
@Description(name = "groupconcat", value = "_FUNC_(expr) -返回分组后多列转一列")
public class GroupConcat extends AbstractGenericUDAFResolver{
private static final Log LOG = LogFactory.getLog(GroupConcat.class.getName());
@Override
/**
* @Description: 参数校验
* @param info
* @return: org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
*/
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
if (info.length != 1) {
throw new UDFArgumentTypeException(0,
"Exactly oneargument is expected.");
}
ObjectInspector objectInspector =TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(info[0]);
/*ObjectInspector主要作用是解耦数据使用与数据格式
使得数据流在输入输出端切换不同的输入输出格式
不同的操作使用不同的格式*/
if (objectInspector.getCategory()!= ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0,
"Argument must bePRIMITIVE, but "
+objectInspector.getCategory().name()
+ " was passed.");
}
PrimitiveObjectInspectorprimitiveObjectInspector = (PrimitiveObjectInspector) objectInspector;
if (primitiveObjectInspector.getPrimitiveCategory()!= PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentTypeException(0,
"Argument must beString, but "
+primitiveObjectInspector.getPrimitiveCategory().name()
+ " was passed.");
}
return new GroupConcatEvaluator();
//获取解析器
}
public static class GroupConcatEvaluator extends GenericUDAFEvaluator {
//初始输入格式
private PrimitiveObjectInspector inputOI;
//输出格式
private StandardListObjectInspectorloi;
//merge输入格式
private StandardListObjectInspectorinternalMergeOI;
@Override
public ObjectInspector init(Mode m, ObjectInspector[]parameters) throws HiveException {
assert (parameters.length == 1);
super.init(m, parameters);
if (m == Mode.PARTIAL1) {
inputOI =(PrimitiveObjectInspector) parameters[0];
return ObjectInspectorFactory
.getStandardListObjectInspector(
(PrimitiveObjectInspector) ObjectInspectorUtils
.getStandardObjectInspector(inputOI));
} else {
if (!(parameters[0] instanceof StandardListObjectInspector)){
inputOI =(PrimitiveObjectInspector) ObjectInspectorUtils
.getStandardObjectInspector(parameters[0]);
return (StandardListObjectInspector)ObjectInspectorFactory
.getStandardListObjectInspector(inputOI);
} else {
internalMergeOI =(StandardListObjectInspector) parameters[0];
inputOI =(PrimitiveObjectInspector)
internalMergeOI.getListElementObjectInspector();
loi =(StandardListObjectInspector) ObjectInspectorUtils
.getStandardObjectInspector(internalMergeOI);
return loi;
}
}
}
//定义中间存储类
static class MkArrayAggregationBuffer implements AggregationBuffer {
List<Object> container;
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
MkArrayAggregationBuffer ret= new MkArrayAggregationBuffer();
reset(ret);
return ret;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((MkArrayAggregationBuffer)agg).container=
new ArrayList<Object>();
}
private void putIntoList(Object p,MkArrayAggregationBuffermyagg){
Object pCopy =
ObjectInspectorUtils.copyToStandardObject(p,this.inputOI);
myagg.container.add(pCopy);
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
assert (parameters.length ==1 );
Object p = parameters[0];
if ( p != null ) {
MkArrayAggregationBuffermyagg = (MkArrayAggregationBuffer)agg;
putIntoList(p,myagg);
}
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
MkArrayAggregationBuffermyagg = (MkArrayAggregationBuffer)agg;
ArrayList<Object>ret =
new ArrayList<Object>(myagg.container.size()) ;
ret.addAll(myagg.container);
return ret;
}
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
MkArrayAggregationBuffermyagg = (MkArrayAggregationBuffer)agg;
ArrayList<Object>partialResult=
(ArrayList<Object>)internalMergeOI.getList(partial);
for (Object i:partialResult){
putIntoList(i,myagg);
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
MkArrayAggregationBuffermyagg = (MkArrayAggregationBuffer)agg;
ArrayList<Object>ret = new ArrayList<Object>(myagg.container.size());
ret.addAll(myagg.container);
return ret;
}
}
}
以上是关于Hive UDF开发的主要内容,如果未能解决你的问题,请参考以下文章