hive on spark 安装配置
Posted 金融科技探索
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive on spark 安装配置相关的知识,希望对你有一定的参考价值。
需求介绍
最近发现集群上hive的mapreduce计算特别慢,尤其用kettle抽取mysql数据到hive中时候 。尽管用了调优,但是因为硬件资源的限制,效果不明显。于是想把hive的计算引擎换成spark,毕竟总体上来说spark要比MR快得多。今天抽空过来处理一下。
前置条件
在配置之前,先确保安装了Hadoop集群,JDK,Hive,MySQL,Scala。
我的集群配置信息如下:
类型 机器名 IP
主节点 master 196.128.18.20
从节点 slave1 196.128.18.21
从节点 slave2 196.128.18.22
从节点 slave3 196.128.18.23
从节点 slave4 196.128.18.24
说明
Hive on Spark 在官网的介绍是:“Hive on Spark provides Hive with the ability to utilize Apache Spark as its execution engine.” ,也就是用Spark作为hive的执行引擎。
Hive默认是用MR(MapReduce)做计算引擎的,它也可以用Tez和Spark做计算引擎,与MR把中间结果存入文件系统不同,Spark全部在内存执行,所以总体上Spark要比MR开很多。
Spark集群需要用到hdfs系统,所以安装Spark需要先安装好hadoop集群,同时hive用MySQL作为元数据存储数据库,所以需要先安装好MySQL。另外编译spark需要安装maven和Scala。
一、环境说明
本机器软件环境如下:
操作系统:CentOS 6.6
Hadoop 2.6.5
Hive 2.3.3
Spark 2.1.0
MySQL 5.6
JDK 1.7
Maven 3.5.3
Scala 2.10
二、编译和安装Spark(Spark on YARN)
2.1 编译Spark源码
Hive 和 Spark 是有兼容行问题,所以需要用对应的Hive和Spark,下面是官网提供的兼容版本:
在Spark官网上下载编译过的版本是带了hive的jar包的,而要用 spark on hive , 官网介绍是:
“Note that you must have a version of Spark which does not include the Hive jars”
也就是要不包含 Hive jars包的,所以我们需要下载源码重新编译,并且编译的时候不能指定hive。
我们去官网 https://spark.apache.org/downloads.html 下载 spark2.1.0的源码:

下载解压到 /home/hadoop 下:
hadoop 用户执行: sudo tar -zxf spark-2.1.0.tgz -C /home/hadoop
注意:编译前请确保已经安装JDK、Maven和Scala,并在/etc/profile里配置环境变量。
开始编译
cd /home/hadoop/spark-2.1.0/dev
执行:
./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"
编译过程需要在线下载Maven依赖的jar包,所以需要确保能联网,这个步骤时间可能比较长,取决于你的网速本次是大约花费二三十分钟。看网上说可能需要好几个小时。刚开始打印信息如下:
[hadoop@master dev]$ ./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"
-bash: ./dev/make-distribution.sh: No such file or directory
[hadoop@mini1 dev]$ ./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided" +++ dirname ./make-distribution.sh
++ cd ./..
++ pwd
+ SPARK_HOME=/home/hadoop/instSoft/spark-2.1.0
+ DISTDIR=/home/hadoop/instSoft/spark-2.1.0/dist
+ MAKE_TGZ=false
+ MAKE_PIP=false
+ MAKE_R=false
+ NAME=none
+ MVN=/home/hadoop/instSoft/spark-2.1.0/build/mvn
+ (( 4 ))
+ case $1 in
+ NAME=hadoop2-without-hive
+ shift
+ shift
+ (( 2 ))
+ case $1 in
+ MAKE_TGZ=true
+ shift
+ (( 1 ))
+ case $1 in
+ break
+ '[' -z /usr/lib/jvm/jre-1.7.0-openjdk.x86_64 ']'
+ '[' -z /usr/lib/jvm/jre-1.7.0-openjdk.x86_64 ']'
++ command -v git
过程会看到很多下载信息,如:
Downloaded from central: https://repo1.maven.org/maven2/junit/junit/4.12/junit-4.12.jar (315 kB at 135 kB/s)
Downloading from central: https://repo1.maven.org/maven2/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar
Downloaded from central: https://repo1.maven.org/maven2/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar (45 kB at 16 kB/s)
Downloading from central: https://repo1.maven.org/maven2/com/novocode/junit-interface/0.11/junit-interface-0.11.jar
Downloaded from central: https://repo1.maven.org/maven2/com/novocode/junit-interface/0.11/junit-interface-0.11.jar (30 kB at 9.0 kB/s)
Downloading from central: https://repo1.maven.org/maven2/org/scala-sbt/test-interface/1.0/test-interface-1.0.jar
Downloaded from central: https://repo1.maven.org/maven2/org/scala-lang/modules/scala-xml_2.11/1.0.2/scala-xml_2.11-1.0.2.jar (649 kB at 177 kB/s)
Downloaded from central: https://repo1.maven.org/maven2/org/scala-sbt/test-interface/1.0/test-interface-1.0.jar (15 kB at 3.8 kB/s)
编译完成如下图:
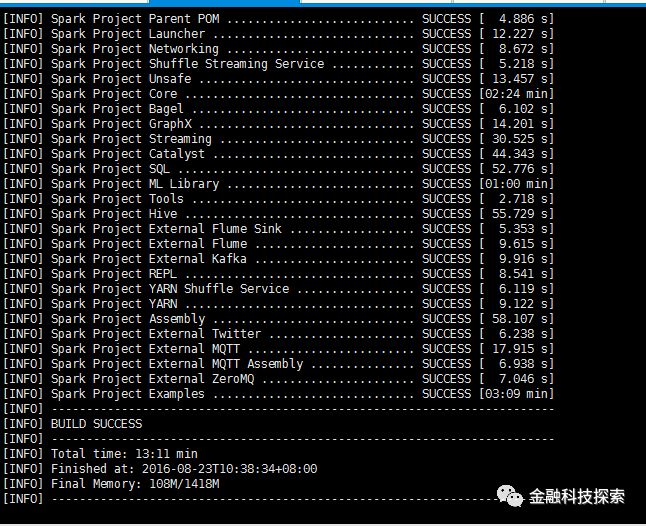
编译成功后,在spark-2.1.0目录下会多一个文件:spark-1.5.0-cdh5.5.1-bin-hadoop2-without-hive.tgz , 如下图(红色):
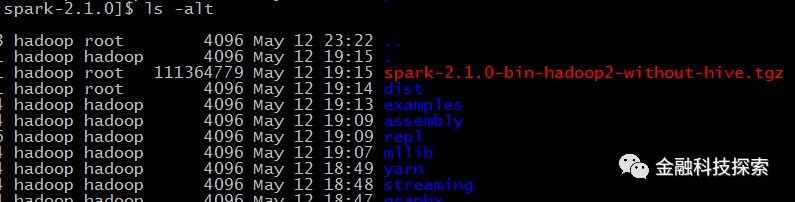
把改文件解压到 /usr/local 目录下:
sudo tar -zxf spark-1.5.0-cdh5.5.1-bin-hadoop2-without-hive.tgz -C /usr/local
修改权限并重命名:
cd /usr/local
sudo chown -R hadoop:hadoop spark-2.1.0
sudo mv spark-2.1.0 spark
2.2 配置Spark
配置环境变量
sudo vi /etc/profile
在最后添加:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
配置spark变量
cd /usr/local/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加以下代码:
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
保存退出
三、下载安装配置HIVE
官网下载 hive 2.3.3
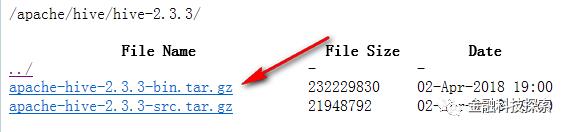
2. 解压并重命名
hadoop用户执行:
sudo tar -zxf apache-hive-2.3.3-bin.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop hive-2.3.3
sudo mv hive-2.3.3 hive
3. 把spark的必要jar放入hive
cp /usr/local/spark/jars/scala-library-2.11.8.jar /usr/local/hive/lib
cp /usr/local/spark/jars/spark-network-common_2.11-2.1.1.jar /usr/local/hive/lib
cp /usr/local/spark/jars/spark-core_2.11-2.1.1.jar /usr/local/hive/lib
4. 下载MySQL的jdbc驱动并放到hive中
注意该驱动需要另外下载:
cp mysql-connector-java-5.1.44-bin.jar /usr/local/hive/lib
5. 配置 hive-site.xml
cd /usr/local/hive/conf
新建hive-site.xml文件:
vi hive-site.xml
添加以下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- Hive Execution Parameters -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<property>
<name>spark.master</name>
<value>yarn-cluster</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>3</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>4</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>2048m</value>
</property>
<property>
<name>spark.driver.cores</name>
<value>2</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>1024m</value>
</property>
<property>
<name>spark.yarn.queue</name>
<value>default</value>
</property>
<property>
<name>spark.app.name</name>
<value>myInceptor</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>spark.executor.extraJavaOptions</name>
<value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
</configuration>
保存退出。
说明一下,文件开始是hive连接MySQL元数据库hive的信息:
用户名为 root ,密码为 password,数据库名称是 hive ,驱动为jdbc,端口是3306 , 连接串如下:
mysql -plocalhost -uroot -ppassword
对于不熟悉MySQL的同学,需要注意一下连接权限。
第二部分是把hive的执行引擎配置为spar
第三部分是一些spark的性能参数配置以及其他一些配置,需要根据系统自身硬件配置。
6. 配置 hive-env.xml
cp hive-env.xml.template hive-env.xml
vi hive-env.xml
在最后加入一下内容:
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms1024m -Xms10m -XX:MaxPermSize=256m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
export HADOOP_HEAPSIZE=4096
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
保存退出。
五、HIVE初始化
执行:
/usr/local/hive/bin/schematool -initSchema -dbType mysql
我刚开始报错:
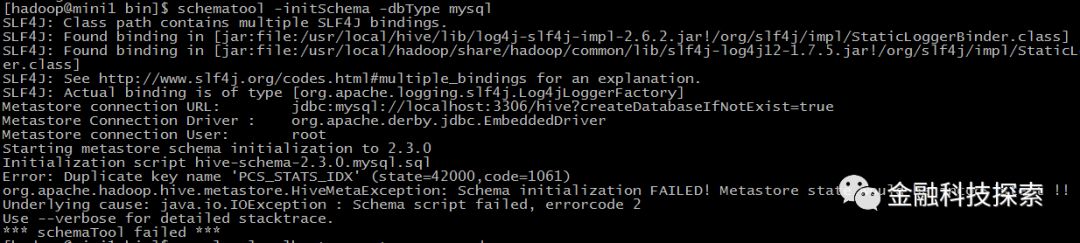
原因是我原来安装了hive,在mysql中已经创建了hive数据库并保存了元数据,所以我先drop掉hive数据库,再次初始化,成功!
五、验证是否安装配置成功
1.准备数据
(1)进入hive,创建外表用户信息表
hive>use default;
hive>CREATE EXTERNAL TABLE user_info (id int,name string,age int,salary decimal(8,2))
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/data/logdata/';
(2)手工造10万条记录,分隔符是逗号,并传到hdfs的/data/logdata下面(该目录下面只有这个
文件)
hadoop fs -put ./user_info.txt /data/logdata/
(3) 检查能否读到数据
hive>select * from user_info;
(4)创建另一张目标表
hive>create table user_info_t(id int, name string, age int, salary decimal(8,2));
(5)把user_info中的10万条记录插入到user_info_t表中
hive>insert into user_info_t select id,name,age,salary from user_info;
(6)查看是否用spark计算和时间:
可以看到任务确实用spark作为计算引擎,耗时45秒,因为受硬件设备限制,较之前用mapreduce耗时数分钟设置十几分钟已经是大大提升了效率!
结论:配置成功!
总结:以上是今天花了半天时间弄出来的,看似简单,实际是踩坑无数,边踩边填,总算磕磕碰碰弄出来了,还算顺利,花一大晚上整理总结一些小经验,希望能给大家一点参考意义。时间匆忙,以及经验不足,这里面肯定还有不少遗漏甚至错误的地方,欢迎大家指出批评,谢谢!
以上是关于hive on spark 安装配置的主要内容,如果未能解决你的问题,请参考以下文章