Python连接Hive操作数据库
Posted 加米谷学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python连接Hive操作数据库相关的知识,希望对你有一定的参考价值。
客户端连接Hive需要使用HiveServer2。HiveServer2是HiveServer的重写版本,HiveServer不支持多个客户端的并发请求。当前HiveServer2是基于Thrift RPC实现的。它被设计用于为像JDBC、ODBC这样的开发API客户端提供更好的支持。Hive 0.11版本引入的HiveServer2。
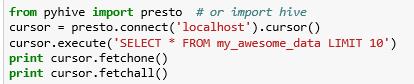
python中用于连接HiveServer2的客户端有3个:pyhs2,pyhive,impyla。官网的示例采用的是pyhs2,但pyhs2的官网已声明不再提供支持,建议使用impyla和pyhive。
在Python代码
conn = mysqldb.Connect(host='localhost', user='root', passwd='root', db='python') 中加一个属性:
改为:
conn = MySQLdb.Connect(host='localhost', user='root', passwd='root', db='python',charset='utf8')
charset是要跟你数据库的编码一样,如果是数据库是gb2312 ,则写charset='gb2312'。

然后,这个连接对象也提供了对事务操作的支持,标准的方法
commit() 提交;
rollback() 回滚;
cursor用来执行命令的方法:
callproc(self, procname, args):用来执行存储过程,接收的参数为存储过程名和参数列表,返回值为受影响的行数;
execute(self, query, args):执行单条sql语句,接收的参数为sql语句本身和使用的参数列表,返回值为受影响的行数;
executemany(self, query, args):执行单挑sql语句,但是重复执行参数列表里的参数,返回值为受影响的行数;
nextset(self):移动到下一个结果集;
cursor用来接收返回值的方法:
fetchall(self):接收全部的返回结果行;
fetchmany(self, size=None):接收size条返回结果行.如果size的值大于返回的结果行的数量,则会返回cursor.arraysize条数据;
fetchone(self):返回一条结果行;
scroll(self, value, mode='relative'):移动指针到某一行.如果mode='relative',则表示从当前所在行移动value条,如果 mode='absolute',则表示从结果集的第一行移动value条。

成都加米谷大数据科技有限公司是一家专注于大数据人才培养的机构。由来自阿里、华为、京东、星环等国内知名企业的多位技术大牛联合创办,技术底蕴丰厚,勤奋创新,精通主流前沿大数据及人工智能相关技术。
以国家规划大数据产业发展战略为指引,以全国大数据技术和大数据分析人才的培养为使命,以提升就业能力、强化职业技术为目标。面向社会提供大数据、人工智能等前沿技术的培训业务。
以上是关于Python连接Hive操作数据库的主要内容,如果未能解决你的问题,请参考以下文章
本地Spark连接远程集群Hive(Scala/Python)