详解Hive框架基础
Posted 程序员干货站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解Hive框架基础相关的知识,希望对你有一定的参考价值。
一句话:学习Hive有毛用?
那么解释一下 毛用:
操作接口采用类SQL语法,提供快速开发的能力(不会Java也可以玩运算)
避免了去写MapReduce,减少开发人员的学习成本(MapReduce运算写断手)
扩展功能很方便
数据库不等同于数据仓库
数据库有很多,例如:mysql、oracle、DB2、sqlserver,但hive并不是数据库。
Hive是FaceBook的开源项目,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件,映射成一张表,并提供类似SQL查询功能, hive的HQL语言(类似SQL)可以将任务翻译成Java语言并直接在MapReduce上运行,支持Yarn资源调度。hive一般不会直接接入到业务中使用,从某种意义上来讲呢,相当于一个Hadoop的客户端,Hive在集群中并不需要每一台服务器都安装Hive。
Hive的一些重要特性
本质:将HQL转化成MapReduce任务
底层存储使用HDFS
适合离线批量处理,延迟比较大(用于周期性的执行分析),不适合用于在线的需要实时分析结果的场景
Hive体系结构
用户接口: Client
终端命令行CLI --主要的一种使用方式,JDBC的方式一般不使用,比较麻烦。
元数据:metastore
默认apache使用的是derby数据库(只能有一个客户端使用),CDH使用postgreDB
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表),表的数据所在目录等,并没有存储Hive表的真实数据
使用HDFS进行存储
使用MapReduce进行计算
解析器: 解析Hql语句
编译器: 把sql语句翻译成MapReduce程序
优化器: 优化sql语句
执行器: 在yarn平台运行MapReduce程序
Hive在Hadoop中的位置,如图:
Hive部署
安装JDK(此步骤省略,请查看之前内容)
安装Hadoop
此步骤要确保Hadoop可以正常使用,比如上传文件,运行jar任务等等
安装Hive
安装过程涉及命令:
$ tar -zxf apache-hive-0.13.1-bin.tar.gz -C /opt/modules/
进入Hive根目录下的conf目录,进行如下操作,到这个阶段应该无需解释了吧?
$ cp -a hive-env.sh.template hive-env.sh,如图:
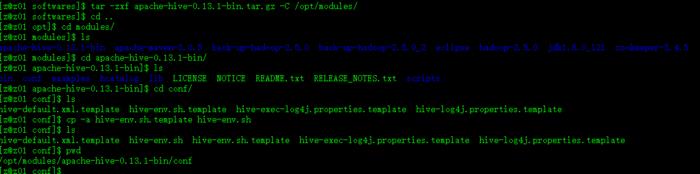
$ cp -a hive-default.xml.template hive-site.xml,如图:

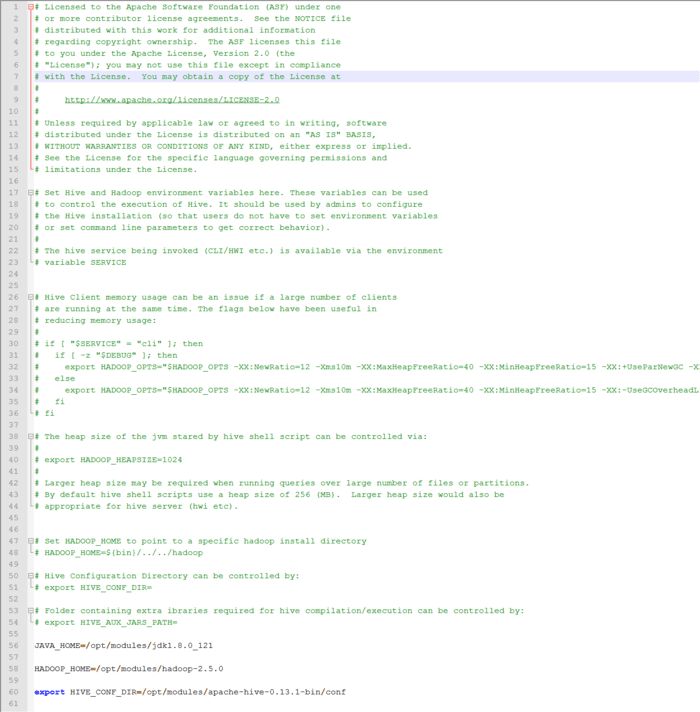
修改hive-env.sh
JAVA_HOME=/opt/modules/jdk1.8.0_121
HADOOP_HOME=/opt/modules/hadoop-2.5.0
export HIVE_CONF_DIR=/opt/modules/apache-hive-0.13.1-bin/conf
如图:
安装mysql,依次涉及命令:
$ su - root
# yum -y install mysql mysql-server mysql-devel
# wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
# rpm -ivh mysql-community-release-el7-5.noarch.rpm
# yum -y install mysql-community-server
成功安装之后启动mysql服务
# systemctl start mysqld.service,centOS7以下版本使用:# service mysqld start
注意,初次安装mysql是root账户是没有密码的
设置密码
方案一:
# mysqladmin -uroot password '123456'
方案二:
# mysql -uroot -p
mysql> update user set password=password("123456") where user='root';
mysql> flush privileges;
mysql> exit;
给用户授权
# mysql -uroot -p
mysql>grant all on *.* to root@'z01' identified by '123456' ;
mysql> flush privileges;
mysql> exit;
注释:
* mysql数据库默认只允许root用户通过localhost/127.0.0.1来登录使用
* 上面带有grant的那条语句中:
all:表示所有权限;
*.*:表示数据库.数据表;
root:表示授权给哪个用户,用户名可以任意指定,如果没有会自动创建;
'z01' :授权给哪台主机
'123456':授权给用户来登录的密码
(尖叫提示:如果你需要让所有的分布式机器都有权限访问mysql,在此例子中,还需要执行grant all on *.* to root@'z02' identified by '123456' ;以及grant all on *.* to root@'z03' identified by '123456' ;留意@符号后边的主机名)
配置hive-site.xml
打开之后,该文件中显示的全部为默认的配置,其中如下4项做出相应修改:

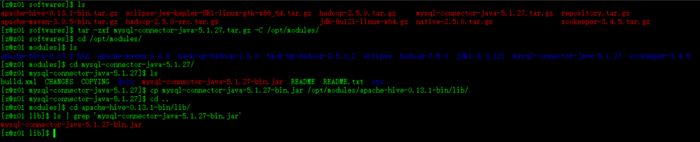
安装驱动包
涉及命令:
$ tar -zxf mysql-connector-java-5.1.27.tar.gz -C /opt/modules
$ cp mysql-connector-java-5.1.27-bin.jar /opt/modules/apache-hive-0.13.1-bin/lib/
操作如图所示:
* 修改目录权限
首先确保HDFS正常运行,之后涉及命令:
$ bin/hadoop fs -chmod g+w /tmp
$ bin/hadoop fs -chmod g+w /user/hive/warehouse
(注意:/tmp存放临时文件;/user/hive/warehouse 具体的Hive仓库目录)

没有对应目录,则创建对应目录
启动Hive客户端
$ bin/hive,如图:

* 中场小结:hive、hadoop的关系、mysql三者之间的关系
* hive数据存储在HDFS的/user/hive/warehouse目录中,我们通过查看hive-site.xml中的hive.metastore.warehouse.dir属性即可发现如图:

Hive基本操作
* 显示所有数据库
hive> show databases;
* 创建数据库
语法:
hive (default)> create database 数据库名称 ;
例如:
创建一个数据库d1:
hive> create databases d1;
* 删除数据库
hive (default)> drop database 数据库名称 ;
* 进入d1数据库
hive> use d1;
* 创建表
语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type ...)]
[PARTITIONED BY (col_name data_type , ...)]
[ROW FORMAT row_format]
[LOCATION hdfs_path]
[AS select_statement];
例如:
在当前数据库中创建表staff,其中包含字段:id,name,sex
hive> create table staff(id int, name string, sex string) row format delimited fields terminated by '\t';
(注意:最后那一句英文表明数据字段之间用table制表符分割)
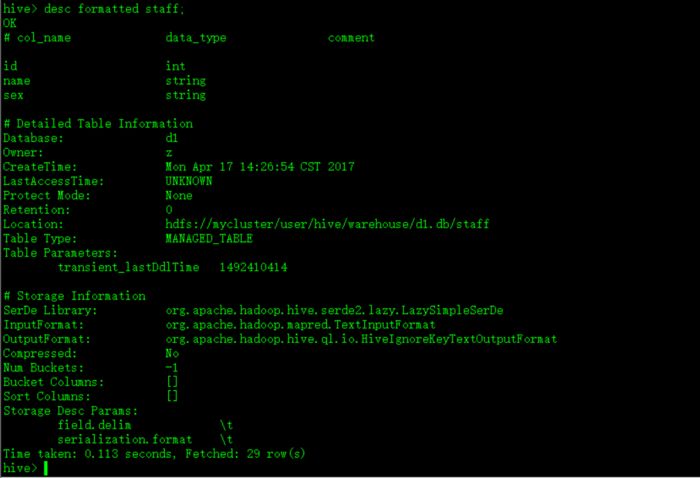
* 格式化输出表staff的结构
hive> desc formatted staff;
如图:
* 向表中插入数据
语法:
load data local inpath '文件路径' [overwrite] into table 数据库名.表名 ;
解释:
** local 表示加载本地文件
** 文件加载模式:append 追加(默认使用)或 overwrite 覆盖
** load data加载只是进行了简单的位置转移(如果load一个HDFS上的数据,比如从HDFS中的一个位置移动到HDFS中的另一个位置,会发生数据转移,转移之后,原来目录的数据就没有了,如果是从local到HDFS,则不会删除原来的数据)
** 加载数据过程中不会去判断字段分隔符是否正确,只有在用户查询数据的时候,会发现错误
例如:
首先,在hive的本地安装目录下,创建文件staff.txt,该文件内容如下:

接着,将本地文件中的数据导入到table中,使用命令:
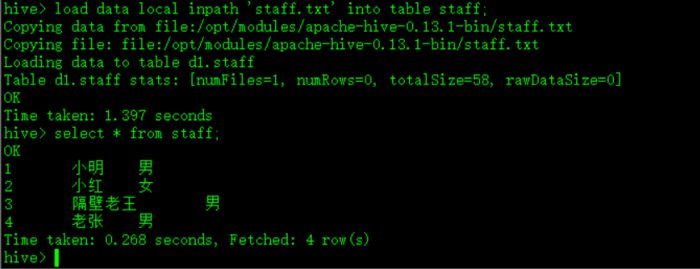
hive> load data local inpath 'staff.txt' into table staff;
最后查看导入后的效果
hive> select * from staff;
如图:
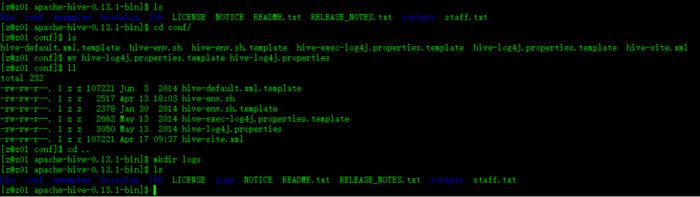
* 修改Hive日志信息
** 重命名配置文件
$ mv hive-log4j.properties.template hive-log4j.properties
** 创建文件夹
$ mkdir logs
** 编辑hive-log4j.properties文件,并修改日志存储目录
hive.log.dir=/opt/modules/apache-hive-0.13.1-bin/logs
如图:

* 设置hive在操作时是否显示数据库名称和列名
如图:
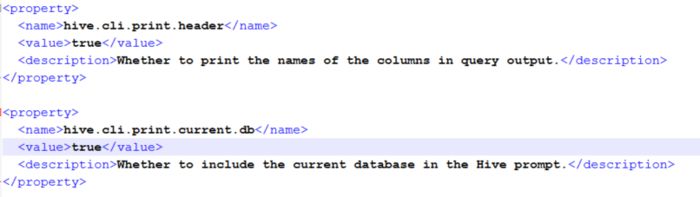
改为true即可
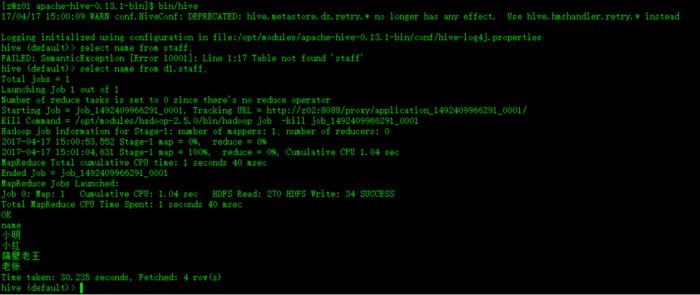
* Hive任务
hive任务有两种:
走mapreduce:
hive (default)> select name from d1.staff;
如图:
不走mapreduce:
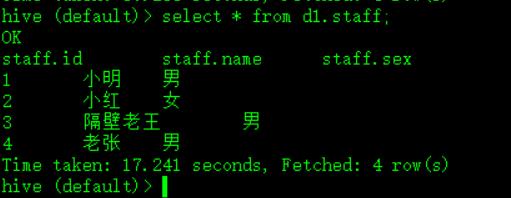
hive (default)> select * from d1.staff;
如图:
* Hive的调试
在调试Hive任务时,一般会加入如下参数:
$ bin/hive --hiveconf hive.root.logger=DEBUG,console
* mysql数据库备份与还原
备份与还原的数据库名称均为:metastore,如图:
** 备份:
$ mysqldump -uroot -p metastore > metastore.sql
如图:

** 还原:
方案1:
$ mysql -uroot -p metastore < metastore.sql
如图:

方案2:
$ mysql -uroot -p
mysql> source /path/metastore.sql ;
* 拓展:mysql存储中innodb和MYISAM区别
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能。
** innodb
新版本5.5+中默认使用;
.frm 结构文件;
.ibdata1 数据文件;
** MYISAM
/var/lib/mysql;
.frm 结构文件;
.MYI 索引文件;
.MYD 数据文件;
* Hive命令两个重要参数
执行sql语句:-e
$ bin/hive -e "select * from d1.staff",如图:

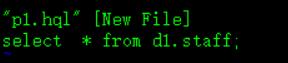
执行sql语句文件:-f
首先创建一个带有sql语句的文件p1.hql,如图:
$ bin/hive -f p1.hql,如图:

* Hive 历史命令的存放
存放位置:~/.hivehistory
查看该文件,如图:
* Hive中临时设置配置并生效
例如:hive > set hive.cli.print.current.db=true;
(注意,此方式为临时生效)
* 总结
本节主要讲解如何配置并使用Hive,并观察hive任务在mapreduce中的运行以及结果的输出。
(原文:https://www.jianshu.com/p/76c0897cbd09)
以上是关于详解Hive框架基础的主要内容,如果未能解决你的问题,请参考以下文章