Hive入门级介绍
Posted Qtest之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive入门级介绍相关的知识,希望对你有一定的参考价值。
之前工作过程中接触到了hive,因此对hive做了一点小总结,在此给大家做个简单介绍。
在介绍hive前,先说说几个名词。
Hadoop:分布式系统基础架构,核心设计是HDFS和MapReduce。
HDFS:Hadoop Distributed File System(分布式文件系统),用于存储和处理数据集。
MapReduce:用于大规模数据集并行运算的编程模型。
hive是什么
hive是基于Hadoop的一个数据仓库工具。
02
hive产生的背景
Facebook在使用基于mysql的数据仓库进行报表分析时,传统数据库难以负荷不断攀升的数据量,于是他们选择将数据存储到Hadoop上,然而想要从HDFS中查询数据,必须要跑MapReduce任务,这对于使用人员来说,成本过高,于是就有人开发了一套框架,用sql来做HDFS的查询,用户输入sql,框架内部把sql转成MapReduce任务。
至此hive诞生了。
03
hive解决的问题
将结构化的数据文件映射为一张数据库表,并定义了简单的类 SQL 查询语言,完成对HDFS数据的查询。
Hive和Hadoop交互方式如图所示:
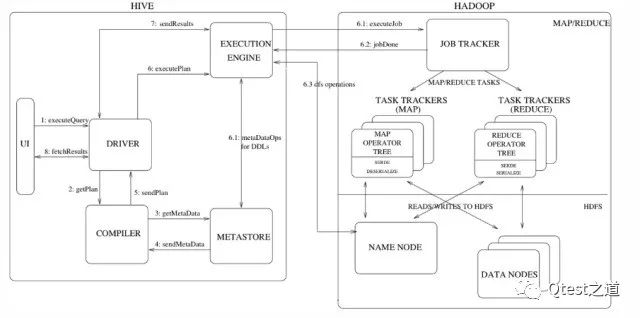
Step 1(excuteQuery):Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
Step 2(getPlan):在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
Step 3(getMetadata):编译器发送元数据请求到Metastore(数据库)。
Step 4(sendMetadata):Metastore发送元数据,以编译器的响应。
Step 5(sendPlan):编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
Step 6(excutePlan):驱动程序发送待执行计划到执行引擎。
excuteJob:内部执行MapReduce。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
metadataOps:在excuteJob执行时,执行引擎可以通过Metastore执行元数据操作。
jobDone:执行引擎接收来自数据节点的结果。
Step 7(sendResults):执行引擎发送这些结果值给驱动程序。
Step 8(fetchResults):驱动程序将结果发送给Hive接口。
04
hive的存储
Hive本身是不进行数据存储的,数据都是存储在hdfs中的,如果没有特殊的声明,会以文本的形式存储,即不会再存储前做任何操作。
05
hive的优缺点
1) 简单易上手
2) 扩展能力较好
3) 统一的元数据管理
4) 由于是从HDFS中读取数据,所以决定了hive不支持局部的修改和删除,只能整体的覆盖、删除。
06
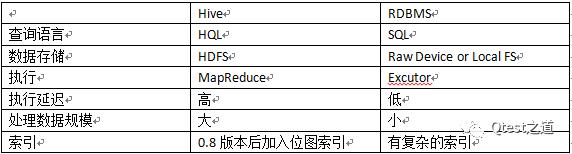
与传统数据库对比
感谢大家百忙之中花时间阅读这篇文章!~
由于作者了解的也比较浅显,在此关于hive的介绍就写这么多,希望后期可以和大家多交流,互相充电~
——作者案
Qtest是360旗下的专业测试团队!
是WEB平台部测试技术平台化、效率化的先锋力量!
陪伴是最长情的告白
每日为你推送最in的测试技术
以上是关于Hive入门级介绍的主要内容,如果未能解决你的问题,请参考以下文章