Hive Join 分析和优化
Posted 数据与算法联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive Join 分析和优化相关的知识,希望对你有一定的参考价值。
文来自实战
1 ·. 背景
Sku对应品牌进行关联,大表对应非大表(这里的非大表并不能用小表来定义)
2 ·. 问题分析
进行表左关联时,最后一个reduce任务卡到99%,运行时间很长,发生了严重的数据倾斜。
什么是数据倾斜?数据倾斜主要表现在,map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完。
3 ·. Hive join
MapReduce流程图
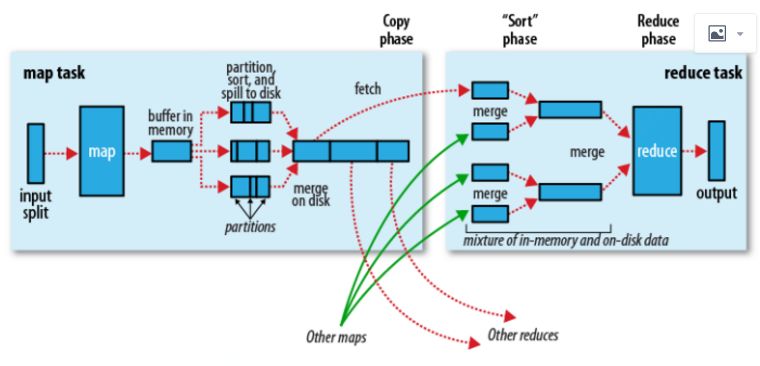
Join流程
HQL:SELECT a.id, a.dept, b.age FROM a join b ON a.id = b.id
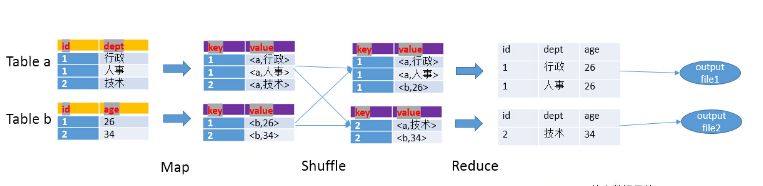
Map阶段
1:读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
2:Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
3:按照key进行排序;
4:map的个数取决于数据量和hdfs的分片大小,比如说hdfs分片配置的是128M(也可能是256M),然后数据目录下有一个文件为300M,那么对于的map个数为3个;如果目录下有三个文件,分别为20M,40M,200M,则对应的map个数为4个。
5:Map个数是不是越多越好?答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
6:是不是保证每个map处理接近128m的文件块,就可以了? 答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
Reduce阶段
1:根据key的值完成join操作,期间通过Tag来识别不同表中的数据
2:reduce的个数在不进行指定的情况下,hive会猜测一个reduce个数,基于以下两个设定:

计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务
3:reduce个数设置
1) 调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
2) set mapred.reduce.tasks = 15;
4:reduce个数是不是越多越好?同map一样,启动和初始化reduce也会消耗时间和资源; 另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
Hive Join类型
参考:http://lxw1234.com/archives/2015/06/315.htm
4 ·. 优化
1:hive启动的set设置
set hive.exec.compress.output = true;
-- map/reduce 输出压缩(一般采用序列化文件存储)
set mapred.output.compression.codec = com.hadoop.compression.lzo.LzopCodec;
-- 压缩文件格式为 lzo
set hive.map.aggr = true;
-- map端是否聚合
set hive.merge.mapfiles = true;
-- map输出是否合并
set hive.merge.mapredfiles = true;
-- reduce输出是否合并
set hive.merge.size.per.task = 256000000;
-- 设置的合并文件的大小
set hive.merge.smallfiles.avgsize = 134000000;
-- 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
set hive.groupby.mapaggr.checkinterval = 100000;
--这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.groupby.skewindata = true;
-- 数据倾斜优化,为true时,查询计划生产两个mapreduce,第一个mr随机处理,第二个按照业务主键聚合
set hive.optimize.skewjoin = true;
-- 如果是join 过程出现倾斜 应该设置为true
set hive.skewjoin.key = 100000;
--这个是join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.exec.parallel = true;
-- 同一个sql中的不同的job是否可以同时运行
set mapred.reduce.tasks = 2000设置reduce 个数
set mapred.max.split.size = 100000000;
-- 一个split 最大的大小
set mapred.min.split.size.per.node = 100000000;
-- 一个节点上(datanode)split至少的大小
set mapred.min.split.size.per.rack = 100000000;
-- 同一个交换机(rack locality)下split至少的大小
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
-- 执行Map前进行小文件合并
set mapred.queue.names = xxxxxxxx
-- 设置队列2:HQL本身注意事项
1):大小表 内关联时,小表放前,加载到内存中
2):两表join的key,做空值、不需要的值,不合格的值过滤,然后用hash 或者随机数 结合case when then else进行处理
eg:需要关联的key 为 brand_id,然后表中大部分brand_id ='0',这是时候在关联时就要进行过滤,但仅仅过滤的话,这些为0的brand_id就会分配到一个reduce中,所以还要加个rand函数
on
(
case
when online.brand_code != '0'
then online.brand_code
else cast(ceiling(rand() * - 65535) as string)
end = brand.brand_idcase
)
3):如果关联的某个key是必须的,但是下边又有很多条数据记录,然后导致数据倾斜
hash即可,比如说我要以三级品类和品牌为key进行join,但某个三级品类对于的品牌下的sku个数特别多,就会发生数据倾斜。
5 ·. 参考资料
http://shiyanjun.cn/archives/588.html
https://blog.csdn.net/B11050101/article/details/78754652
◆ ◆ ◆ ◆ ◆
以上是关于Hive Join 分析和优化的主要内容,如果未能解决你的问题,请参考以下文章