Hive Sql 大全
Posted ITPN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive Sql 大全相关的知识,希望对你有一定的参考价值。
目录:
一.hive初始了解 ;
二.Hive Sql 语法详解 创建表 修改表 显示命令 ;
三. Hive常用函数;
一.hive初始了解
1.没有接触,不知道这个事物是什么,所以不会产生任何问题;
2.接触了,但是不知道他是什么,反正我每天都在用;
3.有一定的了解,不够透彻。 那么hive,
1)我们对它了解多少?
2)它到底是什么?
3)hive和hadoop是什么关系?
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的。
4、 那么,到底什么是Hive,我们先看看Hive官网Wiki是如何介绍Hive的(https://cwiki.apache.org/confluence/display/Hive/Home):
The Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Built on top of Apache HadoopTM, it provides:(1)Tools to enable easy data extract/transform/load ;(ETL)(2)A mechanism to impose structure on a variety of data formats;(3)Access to files stored either directly in Apache HDFSTM or in other data storage 、systems such as Apache HBaseTM;(4)Query execution via MapReduce;
上面英文的大致意思是: Apache Hive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在Apache Hadoop之上,主要提供以下功能:
(1)它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);
(2)是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制; (3)查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如 select * from XXX就不需要;
(4)在Hive0.11对类似select a,b from XXX的查询通过配置也可以不通过MapReduce来完成 上面的意思很明白了.
这里再给他提炼一下:
1)Hive 由 Facebook 实现并开源 ;
2)是基于 Hadoop 的一个数据仓库工具 ;
3)可以将结构化的数据映射为一张数据库表 ;
4)并提供 HQL(Hive SQL)查询功能 ;
5)底层数据是存储在 HDFS 上 ;
6)Hive的本质是将 SQL 语句转换为 MapReduce 任务运行 ;
7)使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算;
总结为一句话:hive是基于hadoop的数据仓库。
8、 Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理; (也就是说对存储在HDFS中的数据进行分析和管理,我们不想使用手工,我们建立一个工具吧,那么这个工具就可以是hive);
为什么使用hive 直接使用 MapReduce 所面临的问题:
(1)人员学习成本太高 ;
(2)项目周期要求太短;
(3)MapReduce实现复杂查询逻辑开发难度太大;
为什么要使用 Hive?
(1)更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力 ;
(2)更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本;
(3)更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数;
9、 Hive特点
优点:
(1) 可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模;
(2) 延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数;
(3)良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点:
(1)Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作);
(2)Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中;
(3)Hive 不支持事务;
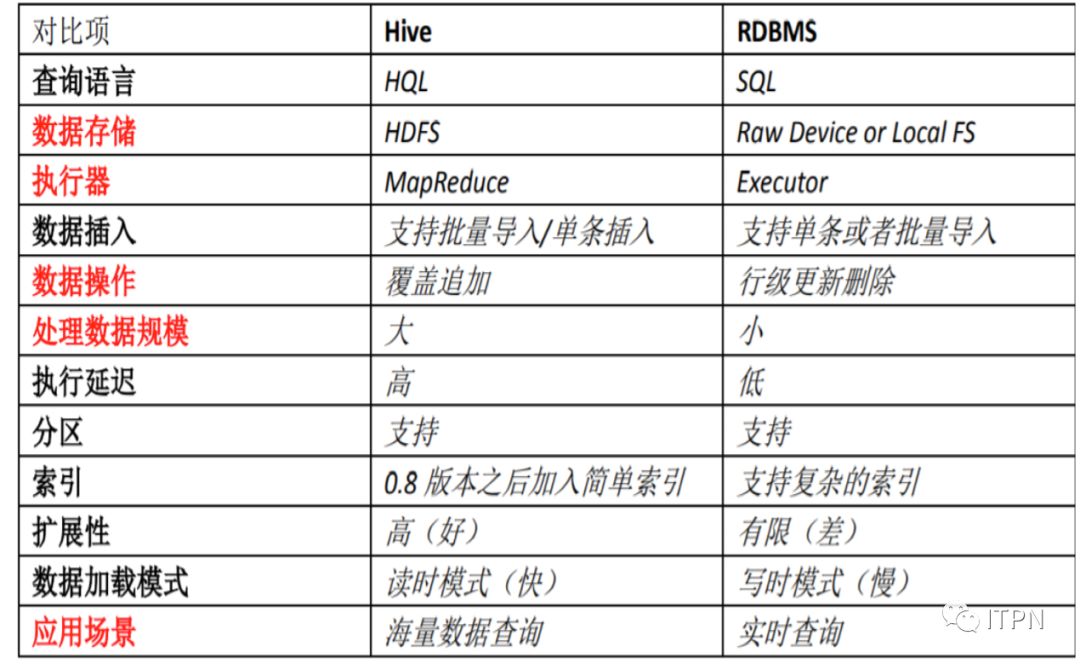
10、Hive和RDBMS的对比:
二.Hive Sql 语法详解
DDL
1.Create命令
1.1操作创建数据库
CREATEDATABASE name;
1.2创建表(分区表)
createtable [if not exists] jikehaohao1234(
cookieid string
,create_time string
,pvint
)comment 'dcx1234表'
partitionedby (etl_tx_dtint) --分区
rowformat delimited fields terminated by ‘\001’
storedas parquet tblproperties('parquet.compression'='SNAPPY');
--如果用户增加上可选项[ifnot exists] ,那么若表已经存在了,Hive就会忽略掉后面的执行语句,而且不会有任何提示。但是如果用户所指定的表的模式和已经存在的这个表的模式不同的话,Hive 不会为此做出提示。如果想要使这个表具有重新指定的那个新的模式的话,那么就需要先删除这个表,再重建表,也可以用altertable来修改表结构。
--字符\001是^A的八进制数,row format delimited fields terminated by‘\001’
这个子句表明Hive 将使用^A字符作为列分隔符
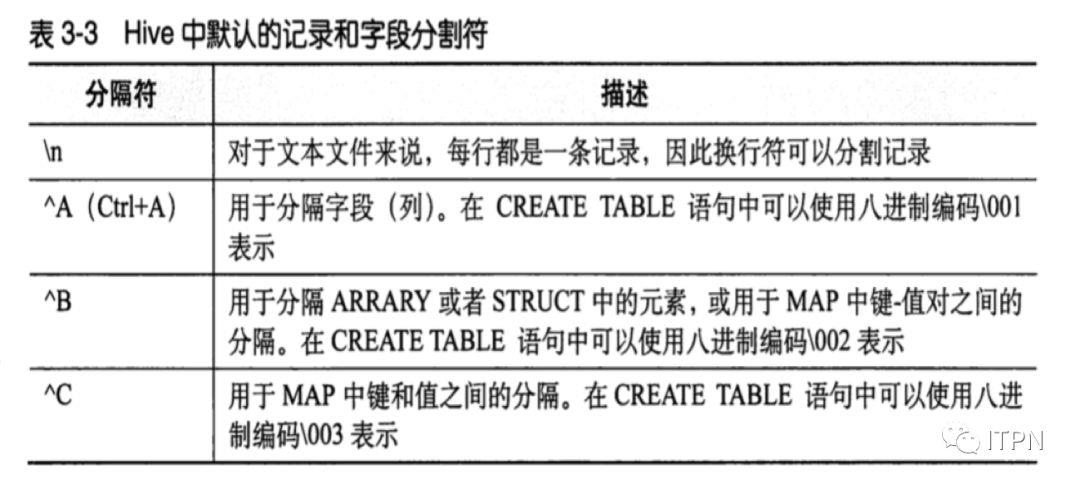
hive中默认的记录和字段分隔符:
例如:
createtable employees(
namestring
,salaryfloat
,employerarray<string>
,taxmap<string,float>
,address struct<street:string,city:string,state:string>
)
Rowformat delimited
Filedsterminated by ‘\001’
Collectionitems terminated by ‘\002’
Mapkeys items terminated by ‘\003’
Linesterminated by ‘\n’
Storedas textfile
;

1.2.1 Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。在HDFS文件系统和Parquet文件中存在如下几个概念:
HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照HDFS的Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
Parquet与ORC:高性能列式存储格式
https://blog.csdn.net/yu616568/article/details/51868447/
1.3复制一个空表
createtable empty_jikehaohao1234 like dcx1234;
2.修改表
2.1添加分区
altertable jikehaohao1234 add [if not exists] partition (dt=‘${bdp.system.bizdate}’);
2.2 删除分区
altertable jikehaohao1234 drop partition (dt='${bdp.system.bizdate}');
2.3 重命名表
altertable jikehaohao1234 rename to new_table_name;
2.4 修改列/属性
alter table jikehaohao1234 change column create_tiemcreate_timestring;
2.5 添加列
altertable jikehaohao1 add columns(create_time_bakstring);
2.6 删除列
(hive中删除列时没有与mysql语句alter table <table> dropcolumn <col>对应的语句)altertable jikehaohao1234 replace columns (create_time_bakstring); --只保留create_time_bak这一列,实现机制是把表中的字段先全部删除,然后在增加create_time_bak这一列;
3.显示命令
3.1显示所有数据库
showdatabases;
3.2显示当前数据库下的所有表名
showtables;
3.3显示hive库中的所有函数
showfunctions ;
3.3显示表结构
descdcx1234 ;
3.4显示建表语句
showcreate table jikehaohao1234 ;
4.插入数据
4.1将查询结果插入hive表
Insertoverwrite table jikehaohao1234 PARTITION(etl_tx_dt= v_tomorrow)
Select….From xxx_table where….
三. Hive常用函数
数值计算
1、取整函数:round
语法: round(double a)返回值:BIGINT说明: 返回double类型的整数值部分 (遵循四舍五入)
selectround(3.1415926) --3
2、指定精度取整函数:round
语法: round(double a, int d)
返回值:DOUBLE
说明: 返回指定精度d的double类型
selectround(3.1415926,4) --3.1416
3、向下取整函数:floor
语法: floor(double a)返回值:BIGINT说明: 返回等于或者小于该double变量的最大的整数
selectfloor(3.1415926) --3
4、向上取整函数:ceil
语法: ceil(double a)返回值:BIGINT说明: 返回等于或者大于该double变量的最小的整数
selectceil(3.1415926) --4
5、取随机数函数:rand
语法: rand(),rand(int seed)返回值:double说明: 返回一个0到1范围内的随机数。如果指定种子seed,则会等到一个稳定的随机数序列
selectrand(); --0.1844563375066739
selectrand(100); --0.7220096548596434
6、negative函数:negative
语法: negative(int a), negative(doublea)
返回值: intdouble
说明: 返回-a
selectnegative(-5) ; -- 5
selectnegative(5) ; -- -5
7、开平方函数:sqrt
语法: sqrt(double a)
返回值:double
说明: 返回a的平方根
selectsqrt(16) ; --4
8、绝对值函数:abs
语法: abs(double a) abs(int a)
返回值:double int
说明: 返回数值a的绝对值
selectabs(-3.9); --3.9
日期函数
1、UNIX时间戳转日期函数:from_unixtime
语法: from_unixtime(bigint unixtime[, stringformat])
返回值:string
说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式
selectfrom_unixtime(1323308943,‘yyyyMMdd’) --20111208
2、日期转UNIX时间戳函数:unix_timestamp
语法: unix_timestamp(string date)
返回值:bigint
说明: 转换格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0。
selectunix_timestamp(‘2011-12-07 13:01:03’) --1323234063
3、日期时间转日期函数:to_date
语法: to_date(string timestamp)
返回值:string
说明: 返回日期时间字段中的日期部分。
selectto_date(‘2011-12-08 10:03:01’) --2011-12-08
4、日期转年函数:year month day hour minute second weekofyear
语法: year(string date)
返回值:int
说明: 返回日期中的年。
selectyear('2011-12-08 10:03:01') --2011
5、日期比较函数:datediff
语法: datediff(string enddate, stringstartdate)
返回值:int
说明: 返回结束日期减去开始日期的天数。
selectdatediff('2018-12-26','2018-12-20') --6
6、日期增加函数:date_add
语法: date_add(string startdate, intdays)
返回值:string
说明: 返回开始日期startdate增加days天后的日期。
selectdate_add('2018-12-24',2) --2018-12-26
7、日期减少函数:date_sub
语法: date_sub (string startdate, intdays)
返回值:string
说明: 返回开始日期startdate减少days天后的日期。
selectdate_sub('2018-12-24',2) --2018-12-22
字符串函数
1、字符串长度函数:length
语法: length(string A)
返回值:int
说明:返回字符串A的长度
selectlength(‘abcedfg’) --7
2、字符串反转函数:reverse
语法: reverse(string A)
返回值:string
说明:返回字符串A的反转结果
select reverse('abcedfg') --gfdecba
3、字符串连接函数:concat
语法: concat(string A, string B…)返回值:string说明:返回输入字符串连接后的结果,支持任意个输入字符串
selectconcat('abc','123','gh') --abc123gh
4、带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, stringB…)
返回值:string
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
selectconcat_ws(',','abc','123','gh') -- abc,123,gh
注意:如果分隔符为null,则结果也为null
selectconcat_ws(null,‘abc’,‘123’,‘gh’) --null
5、字符串截取函数:substr/substring
语法: substr(string A, int start, intlen),substring(string A, int start, int len)
返回值:string
说明:返回字符串A从start位置开始,长度为len的字符串(如若未给出len,则是到结尾)
selectsubstr('abcde',3,2) --cd
selectsubstr(‘abcde’,3) --cde
selectsubstring(‘abcde’,-2,2) --de
6、字符串转大写函数:upper,ucase 字符串转小写函数:lower,lcase
语法: upper(string A) ucase(string A)
返回值:string
说明:返回字符串A的大写格式
selectupper('abSEd’) --ABSED
selectlower('abSEd') --absed
7、去空格函数:trim ltrim rtrim
语法: trim(string A)返回值:string说明:去除字符串两边的空格
selecttrim(' abc ') --abc
8、正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B,string C)
返回值:string
说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符
selectregexp_replace('foobar', 'oo|ar', '') --fb
9、 json解析函数:get_json_object
语法: get_json_object(string json_string,string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
select get_json_object('{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }','$.owner') -- amy
10、重复字符串函数:repeat
语法: repeat(string str, int n)
返回值:string
说明:返回重复n次后的str字符串
selectrepeat('abc',5) --abcabcabcabcabc
11、分割字符串函数:split
语法: split(string str, string pat)
返回值:array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
selectsplit('abtcdtef','t') --["ab","cd","ef"]
12、集合查找函数:find_in_set
语法: find_in_set(string str, stringstrList)
返回值:int
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
selectfind_in_set('ab','ef,ab,de') --2
条件函数
1、 If函数:if
语法: if(booleantestCondition, T valueTrue, T valueFalseOrNull)
返回值:T
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
selectif(1=2,100,200) -- 200
2、非空查找函数:COALESCE
语法: COALESCE(T v1, T v2, …)返回值: T说明: 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
selectCOALESCE(null,'100','50') -- 100
3、条件判断函数:CASE
语法: CASE WHEN a THEN b [WHEN c THEN d]*[ELSE e] END
返回值: T
说明:如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回e
selectcase when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end -- mary
类型转换函数
1、类型转换函数:cast
语法:cast(expr as <type>)
返回值: Expected "=" to follow"type"
说明: 返回转换后的数据类型
selectcast('123' as bigint) --123
hive中的lateralview 与 explode函数的使用
explode:explode就是将hive一行中复杂的array或者map结构拆分成多行。(行转列)
举例:
新建表:
createtable explode_lateral_view
(`area`string
,`goods_id`string
,`sale_info`string)
ROWFORMAT DELIMITED
FIELDSTERMINATED BY '|’
STOREDAS textfile;
往表中插入数据:
insertinto explode_lateral_viewvalues
('a:shandong,b:beijing,c:hebei’
,'1,2,3,4,5,6,7,8,9’
,'[{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]’
);
explode的使用:
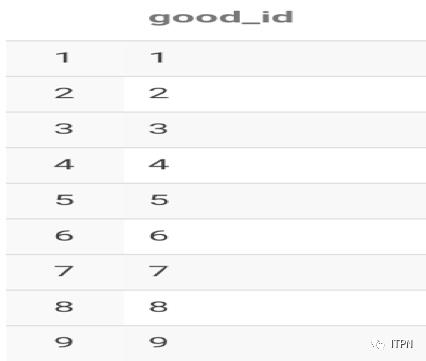
我们只拆解array字段,语句为
selectexplode(split(goods_id,',')) as good_id from explode_lateral_view;
查询结果:
拆解map字段,语句为
selectexplode(split(area,',')) as area from explode_lateral_view;
查询结果:

拆解json字段
这个时候要配合一下get_json_object
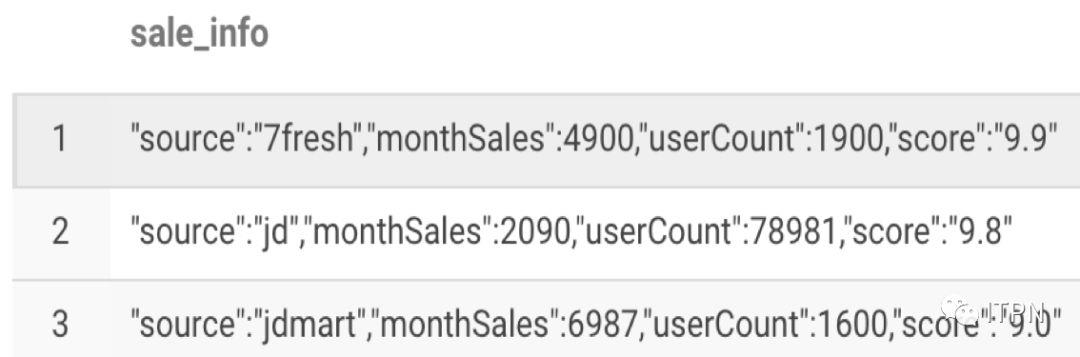
我们想获取所有的monthSales,第一步我们先把这个字段拆成list,并且拆成行展示:
selectexplode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))as sale_info from explode_lateral_view;
结果为:
想用get_json_object来获取key为monthSales的数据:
selectget_json_object(explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{')),'$.monthSales')as sale_info fromexplode_lateral_view;

UDTFexplode不能写在别的函数内
如果你这么写,想查两个字段,
selectexplode(split(area,',')) as area,goods_id fromexplode_lateral_view;

使用UDTF的时候,只支持一个字段,这时候就需要LATERALVIEW出场了.
LATERALVIEW的使用:
LATERALVIEW的使用:侧视图的意义是配合explode(或者其他的UDTF),一个语句生成把单行数据拆解成多行后的数据结果集。
selectgoods_id2,sale_info from explode_lateral_view LATERAL VIEWexplode(split(goods_id,','))goods as goods_id2;
结果为:
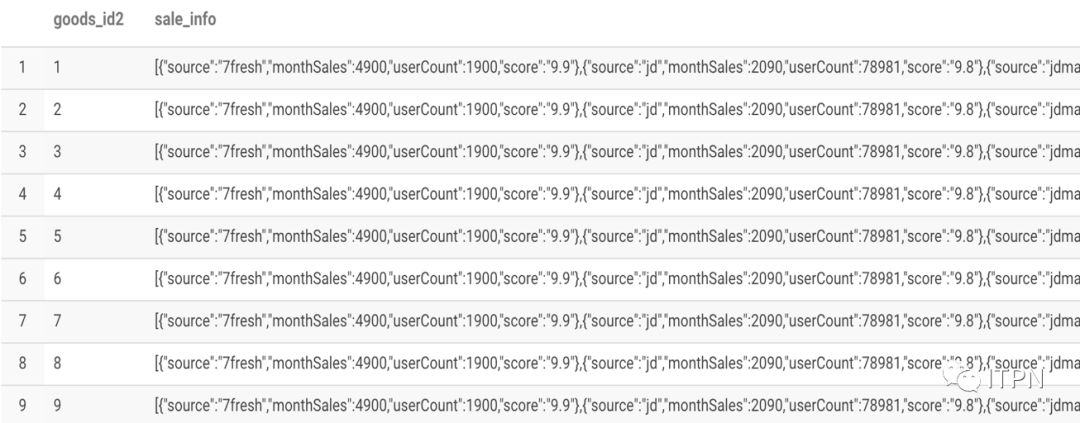
其中LATERAL VIEWexplode(split(goods_id,','))goods相当于一个虚拟表,与原表explode_lateral_view笛卡尔积关联。也可以多重使用
selectgoods_id2,sale_info,area2from explode_lateral_view
LATERALVIEW explode(split(goods_id,','))goods as goods_id2
LATERALVIEW explode(split(area,','))area as area2;
也是三个表笛卡尔积的结果
结果为:
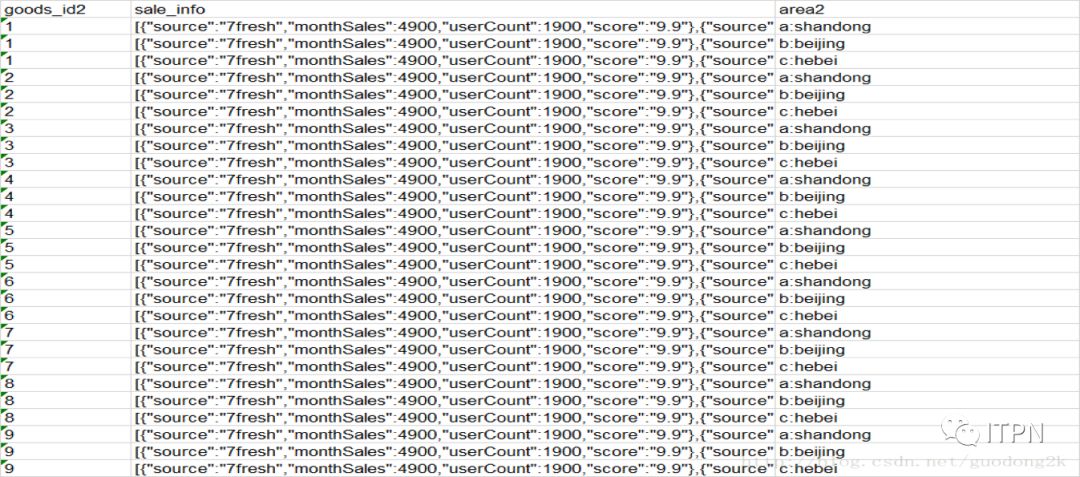
现在我们解决一下上面的问题,从sale_info字段中找出所有的monthSales并且行展示
selectget_json_object(concat(‘{’,sale_info_r,‘}’),‘$.monthSales’) asmonthSales fromexplode_lateral_viewLATERALVIEW explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))sale_info as sale_info_r;
结果为:
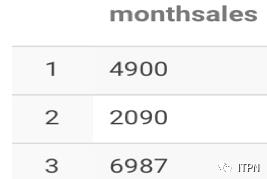
最终,我们可以通过下面的句子,把这个json格式的一行数据,完全转换成二维表的方式展现
selectget_json_object(concat('{',sale_info_1,'}'),'$.source')as source ,get_json_object(concat('{',sale_info_1,'}'),'$.monthSales') asmonthSales ,get_json_object(concat('{',sale_info_1,'}'),'$.userCount') asmonthSales ,get_json_object(concat('{',sale_info_1,'}'),'$.score')as monthSales from explode_lateral_view
LATERALVIEW explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))sale_info assale_info_1;
结果为:

Collect_set()对多行进行合并(列转行)返回值为数组 (去重重复元素)
Collect_list()对多行进行合并(列转行)返回值为数组 (不去重重复元素)
举例数据:

selectid,collect_set(course),collect_list(course)from stu group by id;结果如下:
上面的结果返回的为数组,如果想要返回字符串类型的,还需要借助concat_ws函数实现:
selectid,concat_ws(',',collect_set(course)),concat_ws(',',collect_list(course))from stu group by id;
结果如下:
以上是关于Hive Sql 大全的主要内容,如果未能解决你的问题,请参考以下文章