万字Spring Cloud Gateway2.0,面向未来的技术,了解一下?
Posted 小姐姐味道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字Spring Cloud Gateway2.0,面向未来的技术,了解一下?相关的知识,希望对你有一定的参考价值。
本文将从知识拓扑讲起,谈一下api网关的功能,以及spring cloud gateway的使用方法。文章很长,可以先过一下目录。
一、知识拓扑 (使用和原理)
二、网关的作用
三、Predicate,路由匹配
四、Filter,过滤器编写
五、自定义过滤器
六、常见问题为什么很多人觉得spring cloud gateway难用?因为它的背后用的是webflux,涉及到响应式编程,而不是传统的过程式编程。
我们把背后的技术梳理一下,不难发现,这个晦涩的根源,就来自于project reactor,与spring项目并驾齐驱的,”面向未来”的响应式编程框架。
结果最后的代码,都长的和lambda一样。其背后的思想,是观察者模式和非阻塞杂交的产物,学习曲线相对陡峭。
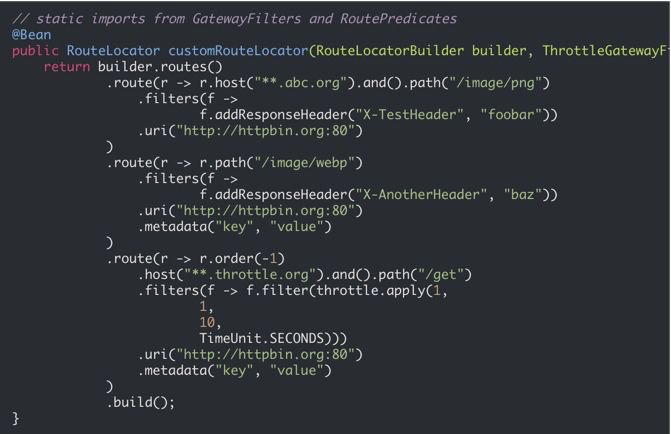
一、知识拓扑
spring cloud gateway涉及到许多比较新的知识和理念,但仅仅对于使用来说,坡度并不是很大。
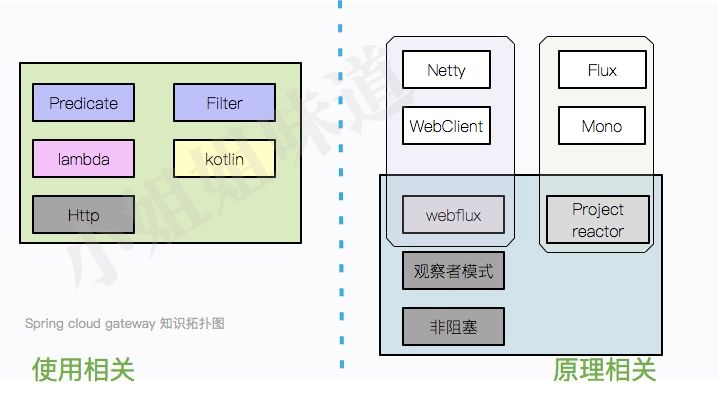
1.1 使用相关
我们可以想象一下一个路由的必要元素:web请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过程的前后,进行一些精细化控制。
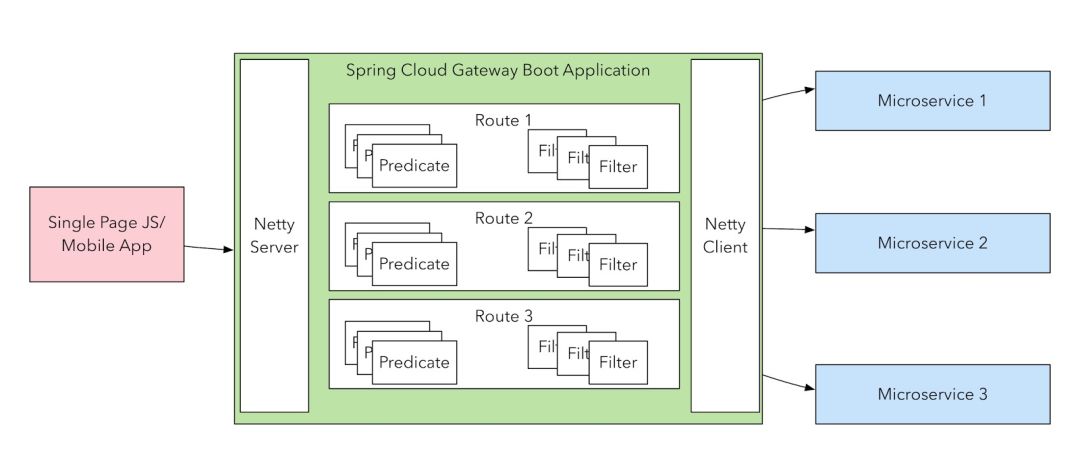
其中,predicate就是我们的匹配条件;而filter,就可以理解为一个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现一个具体的路由了。
由于spring cloud gateway是基于springboot的,所以使用yml进行路由的配置。yml的层次通常比较深,这就造成了配置文件看起来非常的乱。它也可以使用java代码(或者kotlin)进行路由的编写,风格偏向函数编程,所以需要首先了解lambda表达式的写法。
spring cloud gateway大多数时候是作为http服务的网关,可以针对http的报文进行一些细粒度的控制,所以还需要对http协议有较多的理解,才能在使用时游刃有余。
1.2 原理相关
而在原理方面,却复杂的多。由于实践方面的滞后性,现有的组件大多数还没有追上“响应式”这个“超前”的理念,催生了一堆晦涩的组件(主要是专用函数太多)。好在,使用spring cloud gateway并不需要直接接触这些api。
最重要的,就是对webflux框架的封装。webflux是可以替代spring mvc的一套解决方案,可以编写响应式的应用,两者之间的关系可以看下图。它的底层使用的是netty,所以操作是异步非阻塞的。
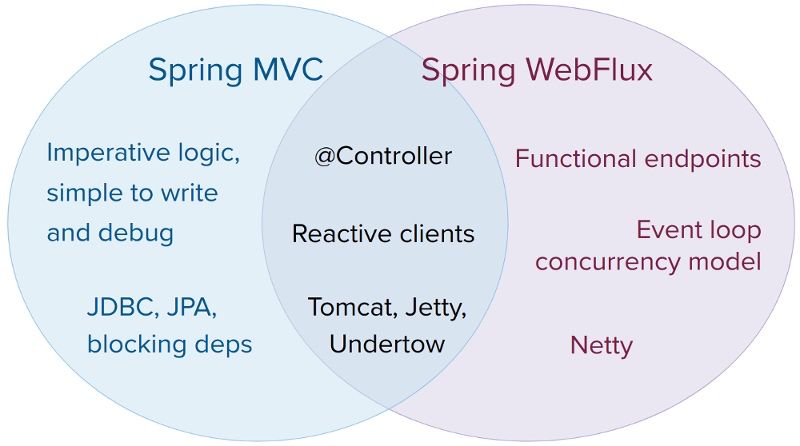
再往下走,webflux是运行在project reactor之上的一个封装,其根本特性是由后者提供的。这个东西和vert.x一样,初次接触使用起来会感觉特别怪异。
reactor是观察者模式的发扬,所以里面有Publisher的概念,其中最主要的实现,就是Flux和Mono。所谓的webflux,取名就在于此。
reactor参考:https://url.cn/5B7f5iY
从传统的开发模式过渡到reactor的开发模式,是有一定成本的。如果有时间可以了解一下背后的原理,对spring cloud gateway的使用,还是有好处的。
二、网关的作用
从名字就可以看到,它是一个网络的关卡,无论后端多么的复杂,这个对外的关卡表现是一致的。
更加重要的是,隐藏在关卡后面的一些通用的事务,都可以抽象出来进行处理。可以把网关,想像成一个类似于海关的东西,你的签证资料准备、安检、调度等,都可以统一进行处理。
api网关就是伴随着微服务概念兴起的一种架构模式,当然也不仅限于微服务。从图中我们可以看到网关的位置。
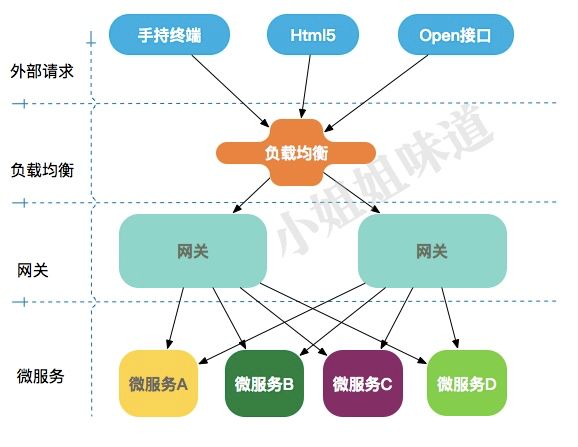
且看下面网关的具体作用。
2.1 反向代理
这个是所有网关,包括nginx的基本功能。除了能够对服务进行整形,网关一个非常重要的附加收益,就是对后端的服务细节进行了屏蔽。
反向代理同时会带有负载均衡的功能,包括带权重的流量分配。
2.2 鉴权
就是权限认证,也就是常说的权限系统。由于鉴权服务有非常高的相似性,就可以进行抽象处理,放在网关层。
比如https协议的统一接入,分布式session的处理问题,新的登录鉴权通道的接入等。
2.3 流量控制
流量控制如果分散到每个服务里去做,就是一种灾难,网关是最适合的地方。
流量控制通常有多种策略,对后端服务进行屏蔽。非正常请求和超出负载能力的请求,都会被快速拦截在外,为系统的稳定性提供了必不可少的支持。
流量控制有单机限流和分布式限流两种方式,后者控制更加精细一些,spring cloud gateway都有提供。
2.4 熔断
熔断与流控的主要区别,在于前者在一段时间内,服务“不可用”,而后者仅概率性失败。
除了服务之间的调用涉及到熔断,在网关层的熔断,作用范围会更大,需要对服务进行准确的分级。
2.5 灰度控制
网关的一个终极功能,就是实现服务的灰度发布。比如常说的AB test,就是一种灰度发布方式。
灰度会进行精细化控制,比如针对一类用户,某个物理区域,特定请求路径,特定模块,随机百分比等方面的一些灰度控制等。
灰度是一个整体架构配合的结果,但协调的入口就是网关,通过对请求头或者参数加入一些特定的标志,就可以对每个请求进行划分,决定是否落入灰度。
2.6 日志监控
网关是最适合进行日志监控的地方。通过对访问日志的精细分析,能够得到很多有价值的数据,进而对后端服务的优化提供决策依据。
比如,某个“业务”的访问趋势,运营数据,QPS峰值,同比、环比等。
三、Predicate,路由匹配
spring cloud gateway的配置方式有Fluent API和yml两种方式,都操蛋的很。
Predicate在英文中是断言的意思。这里我们可以看作是条件匹配,能够根据http头或者http参数进行匹配。
3.1 时间匹配
在某个时间点之前,或者之后的匹配。比如让路由在某个时间段内生效。
配置文件类似于:
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2020-10-20T17:42:47.789-07:00[America/Denver]1.之后
或者翻译成代码方式。
builder.routes().route(
r -> r.after(LocalDateTime.of(2020, 10, 17, 42, 47).atZone(ZoneId.of("America/Denver")))
.uri("https://example.org")
);由于代码大部分类似,下面的篇幅,我们只截取最主要的片段。
2.之前
上面是某个时间点之后,之前的写法,如下:
Before=2017-01-20T17:42:47.789-07:00[America/Denver]
r.before(LocalDateTime.of(2020, 10, 17, 42, 47).atZone(ZoneId.of("America/Denver")))3.之间
还有在某个时间段之内的
Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
r.between(
LocalDateTime.of(2020, 10, 17, 42, 47).atZone(ZoneId.of("America/Denver")),
LocalDateTime.of(2027, 10, 17, 42, 47).atZone(ZoneId.of("America/Denver"))
)3.2 Http信息
我们简单看一下一个http请求的信息,其中,General和Request Headers中的信息,都可以进行匹配控制。对于Cookie、Host等常用的信息,还进行了专门的优化。这其中,最常用的,就是path、cookie、host、query等。
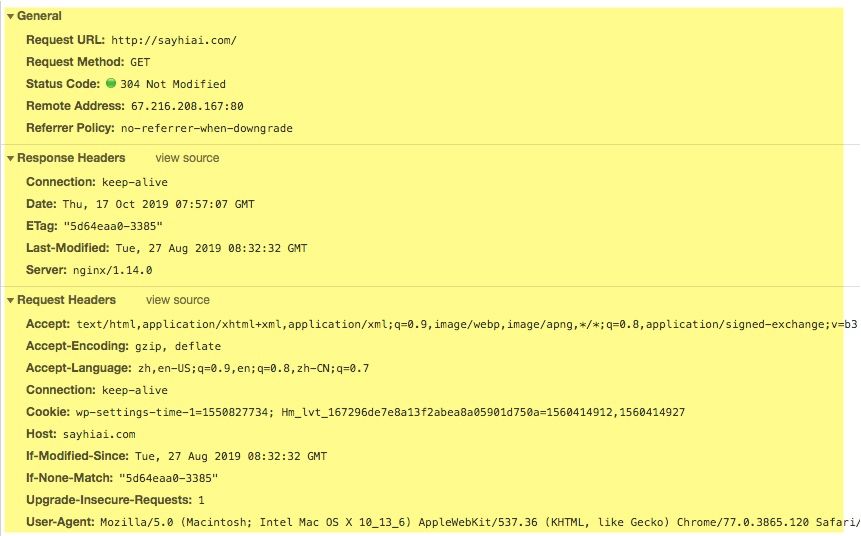
Path
path是最重要的匹配方式,多个path可以使用,分隔。
Path=/foo/{segment},/bar/{segment}
r.path("/foo/{segment}","/bar/{segment}")注意,我们将{segment}使用大括号围了起来,这个值,可以通过代码取出来。
Map<String, String> uriVariables = ServerWebExchangeUtils.getPathPredicateVariables(exchange);
String segment = uriVariables.get("segment");Header头信息
Header=X-Request-Id, \d+
r.header("Header=X-Request-Id", "\\d+")与cookie类似,这里指的是http头方面的匹配,很多灰度信息,或者trace信息,就喜欢放在这里。
Cookie [header]
Cookie=chocolate, ch.p
r.cookie("chocolate","ch.p")http信息中,是否有一个名字叫做chocolate的Cookie,是否与正则ch.p匹配。
Host信息 [header]
虽然host信息也在header信息里,但是由于它太常用了,所以有专门的匹配器。
Host=**.somehost.org,**.anotherhost.org
r.host("Host=**.somehost.org","**.anotherhost.org")注意,这里的匹配字符串,是Ant风格的,更简洁一些,并不是java中的正则表达式。多个host使用,进行分隔。
Request Method
Method=GET
r.method("GET")注意,我在源代码里没有找到大小写转换的代码,所以路由中切记保持大写方式。除了CONNECT,都支持。
Query
这里指的就是url问号后面的一串参数。
Query=baz
r.query("baz")
Query=foo, ba.
r.query("foo","ba.")太简单,都不需要我做过多介绍了。
RemoteAddr
RemoteAddr=192.168.1.1/24
r->r.remoteAddr("192.168.1.1/24")3.3 权重
权重信息的配置,有点2b。比如,我们后面有2台服务器,spring cloud gateway对其做了两个路由,其中链接的枢纽就是一个叫做Weight的group。
spring:
cloud:
gateway:
routes:
- id: weight_high
uri: https://weighthigh.org
predicates:
- Weight=group1, 8
- id: weight_low
uri: https://weightlow.org
predicates:
- Weight=group1, 2同样的代码如下。
builder.routes()
.route("weight_high",r -> r.weight("group1", 8).uri("https://weighthigh.org"))
.route("weight_low",r -> r.weight("group1", 2).uri("https://weightlow.org"));假如服务有100个节点,还有一堆filter,要重复配置100次?不得不说非常的fuck。
四、Filter,过滤器编写
匹配,能够定位到要进行代理的路由。现在,已经进入到了我们的路由内部。上面提到的路由的作用,大部分功能就是在这里进行配置的。
用过zuul网关的可能都知道,在自定义路由时,会有pre和post两个注解控制在代理前后的路由行为。spring cloud gatewa有着同样的功效。
4.1 信息修改
crud不仅仅存在SSM中,路由的配置也是如此。你可能在路由到真正的后端服务之前,对http头或者其他信息修改;或者在代理到相应的链接之后,再进行一些修改。
按照我们的理解,所谓request对应的是pre,而response对应的是post。
AddRequestHeader=X-Request-Foo, Bar
AddRequestParameter=foo, bar
AddResponseHeader=X-Response-Foo, Bar
RemoveRequestHeader=X-Request-Foo
RemoveResponseHeader=X-Response-Foo
RemoveRequestParameter=foo
SetRequestHeader=X-Request-Foo, Bar
SetResponseHeader=X-Response-Foo, Bar
SetStatus=4014.2 Request Body修改
这个就蛋疼了一些,原因还是由webflux引起的,在写法上比较个性一些。
.filters(f -> f.modifyRequestBody(String.class, String.class, MediaType.APPLICATION_JSON_VALUE,
(exchange, s) -> {
return Mono.just(s.toUpperCase());
})上面的代码,将requestBody中的内容,全部转成了大写方式。
相似的,response对应的是modifyResponseBody,写法是类似的。具体的可以参见
ModifyRequestBodyGatewayFilterFactory
的代码。如果没有接触过上面说到的理论部分,读起来还是比较吃力的。
4.3 重定向
RedirectTo=302, https://acme.org
.filters(f -> f.redirect(302,"https://acme.org"))直接重定向。这个比较简单,不做过多介绍。
4.4 去掉前缀
重点。
StripPrefix=2
.filters(f->f.stripPrefix(2))StripPrefix可以接受一个非负整数,用于去掉对应的前缀。比如,外部访问的path是/a/b/c/d
那么,转向后端服务的path,就是/c/d,去掉了/a/b前缀。
这属于路径重写的一种特殊方式,常用在对uri为lb://协议的微服务路径重写。
4.5 路径重写
RewritePath是和nginx的路径重写非常相近的一个东西。
RewritePath=/foo(?<segment>/?.*), $\{segment}
f.rewritePath("/foo(?<segment>/?.*)", "${segment}")官方说说明,由于yml配置文件的缘故。要把$写成$\的方式,但是java代码中并不需要这么做。由于内部使用的还是java的正则,同时用上了group的概念,代码真是脏的可以。
4.6 熔断配置
默认集成的断路器,依然是hystrix。
Hystrix=myCommandName
.filters(f -> f.hystrix(c->c.setName("myCommandName")))另外,熔断还有一个参数叫做fallbackUri,但可惜的是,只支持forward方式。比如:
fallbackUri: forward:/myfallback4.7 重试配置
对于一些对稳定性要求非常高的服务,一个无法回避的问题,就是重试。重试的参数比较多,一个典型的配置如下:
- name: Retry
args:
retries: 3
statuses: BAD_GATEWAY
backoff:
firstBackoff: 10ms
maxBackoff: 50ms
factor: 2
basedOnPreviousValue: false其中,backoff指定了重试的策略和间隔,会按照公式firstBackoff * (factor ^ n)进行增长。
熔断保证了服务的安全性,重试保证了服务的健壮性,要注意甄别使用场景。
4.8 限流
内置的限流器,如果被触发,将返回”HTTP 429 - Too Many Requests”错误。
限流器的参数是一个叫做KeyResolver实现,其中,就有我们上面提到的概念Mono。所以如果你想要扩展这个限流器的话,就需要了解webflux那一套东西。
public interface KeyResolver {
Mono<String> resolve(ServerWebExchange exchange);
}同时,基于redis的令牌桶原理的分布式限流。由于底层使用的是”spring-boot-starter-data-redis-reactive”,所以就拥有了“响应式”的应用特点,支持 WebFlux (Reactor) 的背压(Backpressure)。对于其中的配置,是有些绕的,比如官方的这段配置。
- name: RequestRateLimiter
args:
key-resolver: '#{@ipKeyResolver}'
redis-rate-limiter.replenishRate: 10
redis-rate-limiter.burstCapacity: 20我们就需要定一个名字叫做ipKeyResolver的bean。
限流的维度很多,需要自行开发管理后台。由于篇幅原因,我们不做展开讨论。
五、自定义过滤器
spring cloud gateway的过滤器,有全局过滤器和局部过滤器之分,对应的接口为GatewayFilter和GlobalFilter。
如果内置的过滤器不能满足需求,则可通过自定义过滤器解决。通过实现GatewayFilter和Ordered接口,可以进行更加灵活的控制。
可以参考内置过滤器的实现方式。后面的文章,我们将详细介绍这方面的具体代码实现。
六、常见问题
lb://表示什么?
lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri,在某些特殊情况下,可以直接书写。比如,在eureka中的注册名称为pay-rpc,则此时的写法为:
lb://pay-rpc如何修改http内容?比如method?
注意ServerWebExchange这个东西。使用它的
exchange.mutate()函数,可以进入修改模式。比如,把GET转成POST方式:
ServerHttpRequest request = exchange.getRequest();
if (request.getMethod() == HttpMethod.GET) {
exchange = exchange.mutate().request(request.mutate().method(HttpMethod.POST).build()).build();
}如何动态更新路由?
主要是通过actuator管理接口,确保这些内容放在了内网中。
GET /actuator/gateway/routes 路由列表
GET /actuator/gateway/routes/{id} 获取某个路由信息
GET /actuator/gateway/globalfilters 全局过滤器
GET /actuator/gateway/routefilters filter列表
POST /actuator/gateway/refresh 刷新路由
POST /gateway/routes/{id_route_to_create} 创建路由
DELETE /gateway/routes/{id_route_to_delete} 删除某个路由如何做一些数据统计
这个功能简单的很,我们只需要实现一个全局的过滤器,就可以加入任何统计功能。常用的方式有两种:通过日志进行分析;通过应用内聚合进行分析。
这两者都不是很难,主要在于对功能的规划而不是代码。
我有更高级的功能,比如解密数据的需求,该如何做?
这个就要自己实现过滤器了。
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);通过ServerWebExchange,可以控制整个请求过程中的任何一个参数的添加,修改,删除,重写等。在代理方法前后,可以通过
exchange.getAttributes().put();
exchange.getAttribute()这两个函数,进行参数传递
所以,即使官方不编写任何上面提到的filter,我们依然可以用这个基本接口玩的转。
End
随着zuul1的退出和zuul2的难产,亲生的SCG成为了最优的选择。Spring团队很有意思,直接采用了webflux作为后端的技术(改怕了?),这会让很多人痛痛痛:又要学习新技术了。
本文并没有测试SCG的性能,这个已经有很多团队进行验证了,效果都不错。
但现在的spring cloud gateway,问题还很多。好在这个问题是使用问题,并不是功能问题。它已经内置了非常多的Predicate和Filter,但很多时候并不能解决问题,需要使用者自行创建自己的过滤器。好吧,我的大多数过滤器全是自行创建的。
另外吐槽一下Fluent API和yml的配置方式,真是丑的一b,需要开发一个管理后台。还有复杂的java正则的那些东西,都让人抓狂—请看墙上那些深深的爪痕,就是我的杰作。
点个在看,就是对我最大的支持。
近期热门文章
以上是关于万字Spring Cloud Gateway2.0,面向未来的技术,了解一下?的主要内容,如果未能解决你的问题,请参考以下文章
万字长文:SpringCloud gateway入门学习&实践
万字 讲解Spring Cloud Gateway 2.0,面向未来的技术,了解一下?