基于mycat高可用方案——数据库负载
Posted 韩先生写程序
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于mycat高可用方案——数据库负载相关的知识,希望对你有一定的参考价值。
引言
传统企业级应用一般采取单台数据库,吞吐所有应用的读写,随着互联网的高速发展,以及微服务架构越来越普及,往往采用分库分表来支撑高速增长的大量业务数据吞吐。分库分表主要有两种方式:水平分表和垂直分库。
垂直分库即基于业务层面,将不同业务数据存储到不同的数据库中。
水平分表即把一个表的数据按照一定路由规则,路由到不同的数据库,通常采用按照某个字段如ID作为路由因子,路由到不同库。
架构演变
历史架构
我们改造之前,数据库层,基于业务做了垂直分库,某些数据量大的业务比如用户账户、账务、订单和优惠券等数据,都放到了同一个数据库实例并水平将数据拆分为十几个表,通过客户端自定义路由来做读写分离和数据命中。数据库架构如下图。
历史架构
这种架构会有以下问题:
自定义路由策略单一,只能通过某个单一分库因子路由到实际表
自定义路由在当前数据库配置不足以支撑业务需要水平扩展时,需要在重新实现路由规则,并经过严格的业务和性能测试
自定义路由在客户端水平扩展时,数据库连接数量是无法控制的,比如,一个客户端的数据库连接pool设置为100,如果我由两台扩展到4台,那么数据库服务器接入的连接数最大就可能由原来的200增加到400,可能会导致数据库服务器TCP连接数过多而内存不足或则宕机。
演变架构
目前系统采用单台HaProxy负载多台mycat服务器,通过mycat分库分表,读写分离来管理和路由真实的多台mysql数据库RDS。其配置部署图如下:
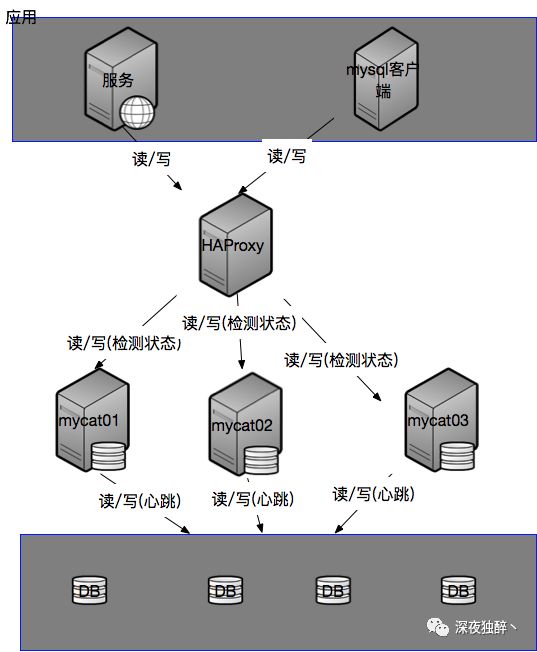
当前架构部署图
下面就讲讲为什么选用当前这种架构部署方案。
Why MyCat
MyCat是一款优秀的开源分布式数据库中间件,架构设计图如下。
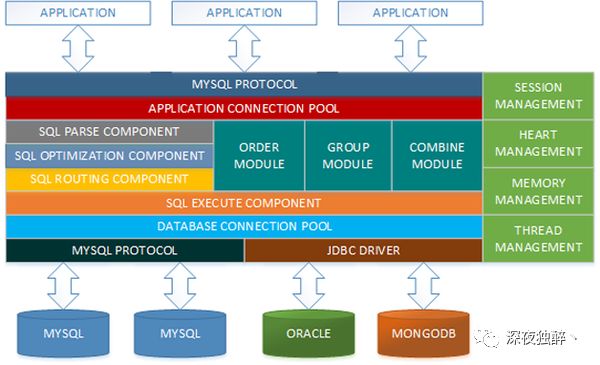
mycat架构设计图
具体实现原理这里就不多做赘述,它解决了哪些问题呢?
连接过多问题,可以通过MyCat统一管理所有的数据源,更灵活的支持客户端水平扩展,通过mycat统一管理连接池连接数量
独创的ER关系分片,解决E-R分片难处理问题,存在关联关系的父子表在数据插入的过程中,子表会被MyCat路由到其相关父表记录的节点上,从而父子表的Join查询可以下推到各个数据库节点上完成,这是最高效的跨节点Join处理技术,也是MyCat首创。
采用全局分片技术,每个节点同时并发插入和更新数据,每个节点都可以读取数据,提升读性能的同时,也解决跨节点Join的效率。
通过人工智能的catlet支持跨分片复杂SQL实现以及存储过程支持等。
MyCat技术原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
Why HaProxy
HAProxy是一个使用C语言编写的自由及开放源代码软件[1],其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。
HaProxy提供了高可用、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机的高效可靠的解决方案,单纯从效率上讲比nginx的负载均衡速度更优秀,关键是能兑Mysql数据库进行负载均衡。
MyCat官方推荐的高可用架构部署方案就是基于HaProxy做的负载均衡。
MyCat官方推荐高可用架构
阿里云SLB碰到的坑
我们在当前架构的实际应用中,踩过了不少的坑,可以说是一路泥泞。
第一个要说的就是我们为什么没采取阿里云的SLB直接代理MyCat集群,刚开始设计架构的时候用的就是基于SLB做负载均衡,在项目运行一段时间后,发现MySql数据库服务器的TCP连接源源不断的增加,并且不会自我释放连接。经过研究发现,MyCat在接收到SLB发送的健康检查心跳的指令时,会把非mysql协议的指令直接发送给真实的mysql服务器,会建立大量MsqlIO连接,而mysql数据库无法识别这些指令就导致数据库连接泄露,这也算是Mycat的一个Bug,目前Mycat还没有解决该问题。
如果谁有好的解决方案,请跟笔者联系。
我们用了MyCat官方推荐的基于多台HaProxy+KeepAlived+MyCat的集群架构,但是阿里云的上ECS服务器跟我们自己的虚拟机不一样,它不支持浮动IP的,所以我们无法使用keepalived方案,虽然现在可以利用阿里云VIP解决这个问题,但是阿里云服务器上keepalived只能设置单播,且要做当主库宕机恢复后,容易出现IP漂移的问题,所以我们也放弃了这个方案。
当前问题和解决方案
基于上述现有数据库部署架构,我们肯定不难发现,如果单点HaProxy宕机,对我们整个生产环境系统来说,就是灾难性的雪崩,我们就做了一下解决方案:
方案一:基于Spring技术,自己开发了一套数据库客户端软负载的中间件,可以在数据库连接池中获取连接时,通过负载均衡器从动态数据源集合对象中后去一个数据源,并在初始化时启动一个线程监控所有mycat连接,定时进行健康检查,并根据结果更新负载均衡数据源集合对象中的数据源,其原理图如下:
自定义数据库软负载原理图
方案二:基于MySql Connector/J java连接器的LoadBalancing协议,进行负载均衡。
下面我们着重介绍Mysql Connector的loadbalancing协议。
Load Balancing协议与Failover协议
介绍loadbalancing协议之前我们先了解下Failover协议,loadbalancing协议就是基于Failover协议。
Failover协议
Failover协议是mysql的失效重连协议,即当客户端链接失效时,会尝试与其他host建立链接。其URL格式如下:
jdbc:mysql://[master-host]:[port],[slaves-host]:[port],.../[database]?[property=<value>]&[property=<value>]
master服务器需要位于hosts列表第一个,当创建一个connection时,mysql connector/J驱动会首先尝试和master host连接,如果出现异常,则依次和slaves中的host建立连接,直到成功为止;;即使与master的连接失效,但是mysql connector/J驱动并不会丢失master的特殊状态:比如它的访问模式、优先级等。当所有host都不可用,那么mysql connector/J驱动会继续轮询,直到次数达到阈值,通过属性retriesAllDown控制,默认120次,达到阈值仍然无法获取连接则跑出SQLException。
当master恢复后,mysql connector/J驱动又能自动的FallBack到master主机,基于这个特性,我们就能做一些故障容灾和自动恢复。
参见源码:(FailoverConnectionProxy)
Load Balancing(LB)协议
由于Failover协议没有load balance的特性,它读/写操作总是只发生在同一个host上,然而我们实际应用中,可能会出现‘replication’,‘多Master’的情况,比如我们mycat部署多台,需要负载均衡保证高可用,load balancing协议就应运而生了。LB协议可以将读/写负载到多个Mysql实例上,这些实例通常是‘replication’架构和集群架构。LB协议基于Failover协议,其URL格式为:
jdbc:mysql:loadbalance://[host]:[port],[host]:[port],...[/database]?[property=<value>]&[property=<value>]
mysql connector/J驱动创建的LoadBalancedConnection是一个逻辑链接,其内部持有一个物理链接列表,即与每个host建立一个Connection。url中的每个host都是平等的主host,当客户端获取连接时会有两种random(默认随机)和bestResponseTime(最小响应时间)两种均衡策略,可以在参数** loadBalanceStrategy**中指定。
(参见源码:LoadBalancedConnectionProxy,BalanceStrategy,LoadBalancedConnection)
当autocommit为false时,在事务的边界方法执行后,比如commit、rollback,将会触发BalanceStrategy从host列表中重新选择新的链接。
当链接上发生Exception时,比如socket异常,将会导致重新选择链接。
当autocommit为true时,当链接上执行“loadBalanceAutoCommitStatementThreshold”个statements后(Queries或者updates等),将会导致重新选择链接,默认为0表示“粘性链接,不重新选择链接”。(这是负载均衡的一种补偿措施)
方案选择
两种方案我们都在开发、测试环境甚至生成环境做过很多对数据库读写的测试操作,对比后做了以下总结:
方案一自定义软负载是自己实现的,功能单一,负载策略只有轮询,而且健康检查在很长一段时间出现连接泄露的问题,稳定性不够好,还需要做一些优化和测试进行打磨;
方案二是基于mysql的java连接驱动做的负载均衡,是官方提供的方案,稳定性和可用性更高,而且我们在经过很长一段时间的压测和容错性测试,发现其性能很优越,负载均衡策略也更丰富,使用过程更简单。
值得注意的是其中的autoReconnect、** autoReconnectForPools**这两个参数参数用于控制“重连”特性,即当一个session或者事务操作过程中,如果链接出现异常,driver不会跑出Exception而是尝试重新连接并继续执行,如果是非事务操作如查询,则该参数不会带来问题;如果是事务操作,在事务多个操作过程中发生重连,就有可能对session状态造成破坏,而导致数据不一致问题,即便开启autocommit=false仍然不能完全避免这个问题,事实上重连之后并不会rollback原来中断的事务,而是继续进行,参见【autoReconnect】。此参数选项将会在未来的版本中被移除,官方也建议禁用此特性。
总结
我们选择了基于msyql connector/J驱动的LB协议的数据库客户端高可用方案,其部署架构图如下:
基于数据库LB协议部署架构图
我建议数据库URL配置为一下格式:
jdbc:mysql:loadbalance://[host]:[port],[host]:[port],...[/database]?useUnicode=true&characterEncoding=utf-8&zerodatetimebehavior=converttonull&allowMultiQueries=true
useUnicode=true&characterEncoding=utf-8:指定字符的编码、解码格式。
zerodatetimebehavior=converttonull:JAVA连接MySQL数据库,在操作各项值均为为0(或者有0不正确的数据)的timestamp等(日期为0000-00-00。。。。)类型时不能正确处理,而是默认抛出一个异常,比如所见的:java.sql.SQLException: Cannot convert value '0000-00-00 00:00:00' from column XX to TIMESTAMP
allowMultiQueries=true:可以允许一次执行多条sql(通过分号分割)
以上是关于基于mycat高可用方案——数据库负载的主要内容,如果未能解决你的问题,请参考以下文章
# IT明星不是梦 #MySQL高可用集群之基于MyCat部署HaProxy实现高可用
mysql+mycat搭建稳定高可用集群,负载均衡,主备复制,读写分离