MyCAT 数据分片入门实战
Posted iitren
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCAT 数据分片入门实战相关的知识,希望对你有一定的参考价值。
等你点蓝字关注都等出蜘蛛网了
近日尝试了关于Mycat分表分库的特性,这里做一些整理,作为入门的参考。
本文不对Mycat配置的每一项都进行详细解释,这些内容在其官方的权威指南中都有介绍,这里阐述部署mycat的实际操作过程,也算是对文档没有交代部分的一个补充吧。
一、方案规划
部署模型如图
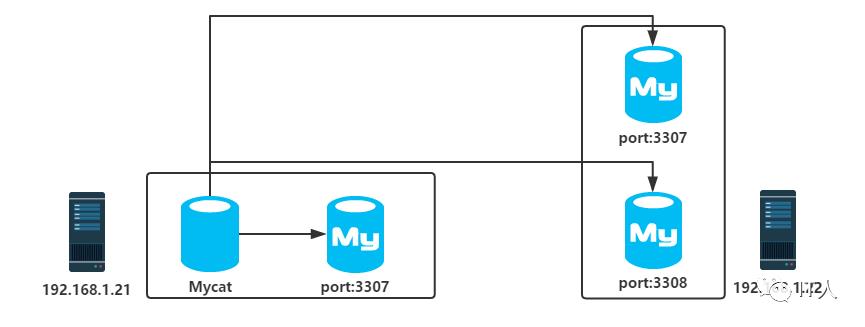
其中,有两台虚拟机:192.168.1.21和192.168.1.22,前者用于部署Mycat-server服务和1个mysql实例,后者部署2个mysql实例,这里为了简化部署模型,未考虑mysql的主从复制,3个实例均独立。
现在假设系统的数据库为messagedb,里面只有2张表,一张表为消息表:message,一张表示消息来源的字典表:source,本案实现的是按自然月分片的规则,因此上述3个mysql实例各自需要创建4个数据库,即:

说明:如果是刚接触Mycat的小伙伴对分片不太理解,简单地说,对于Mycat,一个分片表示某一个MySQL实例上的某一个数据库,即schema@host,于是当我们原先的一张大表需要分片的时候,mycat就会按照我们设定的规则,把这张大表中的数据分散到各个分片上,即所谓的分表分库,因此我们需要在每个对应的分片上创建相同名称的数据库,相同结构的表。
二、环境准备
首先部署mysql实例,假设mysql的安装包已经下载完成,放置在/application/tools目录下,部署的工作用脚本实现:
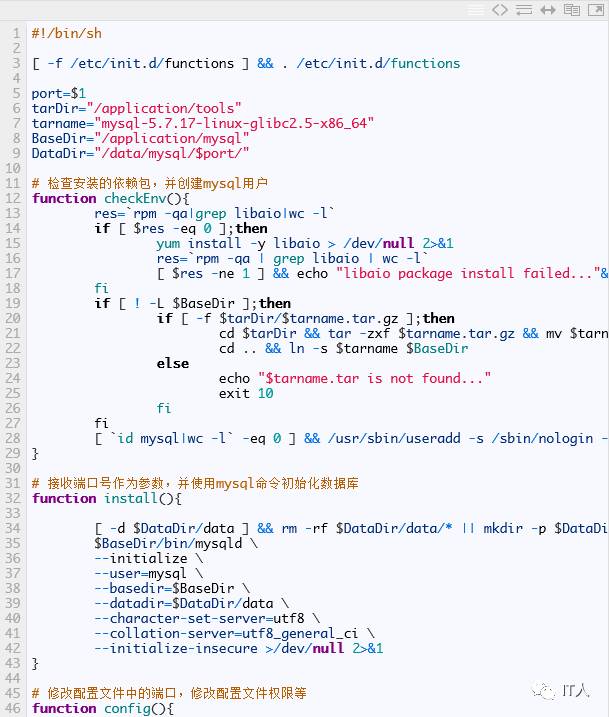
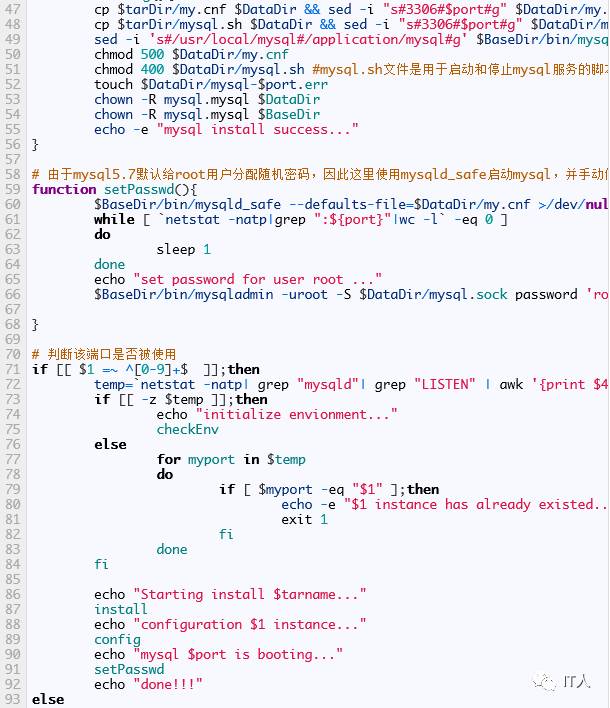

在脚本中,我们为每个mysql实例配置了一个管理脚本:mysql.sh,代码如下:
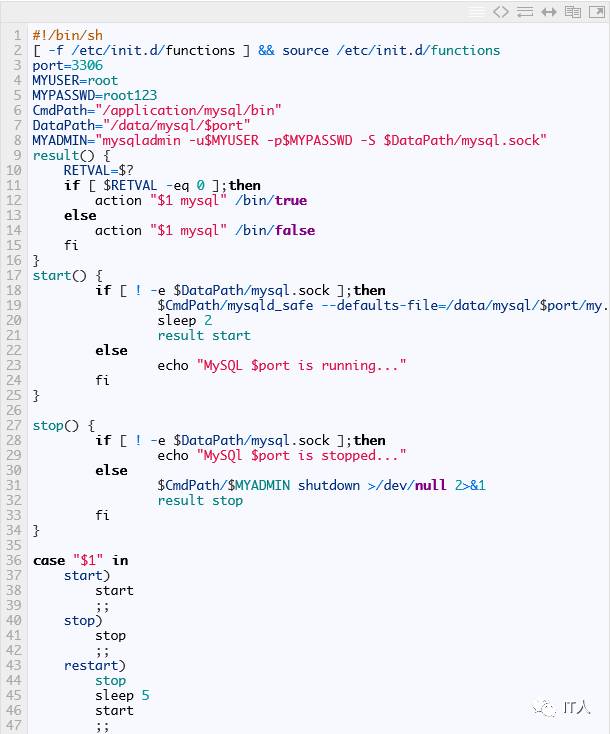

原理很简单,即使用mysqld_safe启动服务,使用mysqladmin停止服务。
将所有实例都启动起来之后,就可以开始创建数据库了,因为都是相同的数据库名和表结构,所以依然用一段脚本来完成工作:
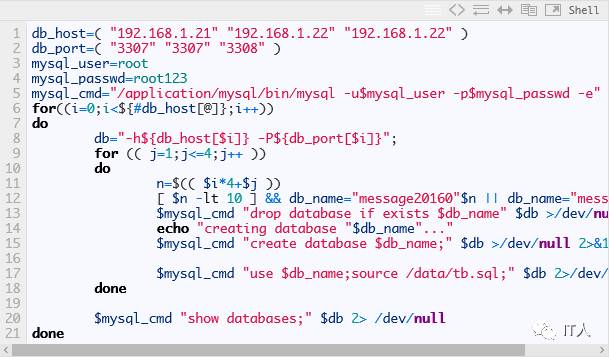
其中tb.sql的内容如下:
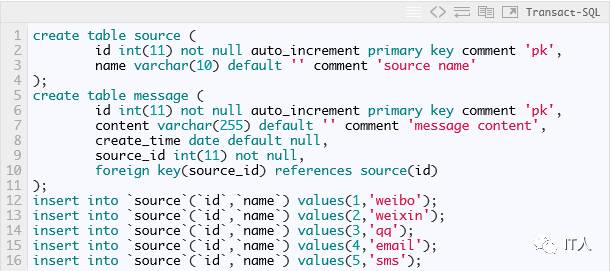
在message表中,总共有4个字段:
id:主键
content:消息的内容
create_time:创建时间,这也是mycat进行分片时的参考字段
source_id:source表的外键
另外,我们在source表插入了5条记录,用于测试。到这里,后端数据库的环境就搭建完成了。
三、安装和配置Mycat
安装完之后,简单地看一下mycat目录结构:
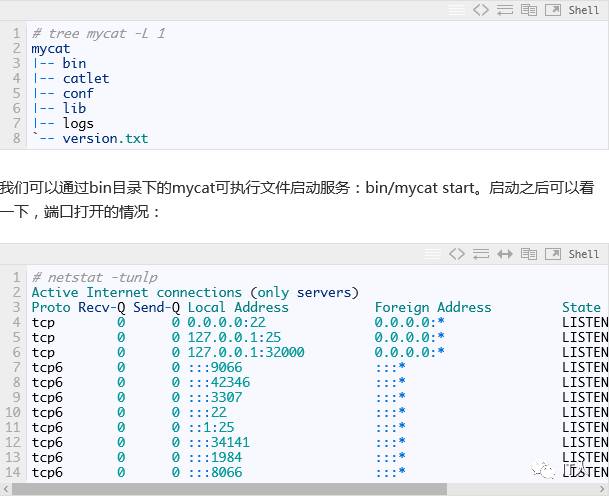
其中,9066端口是管理端口,提供查看当前系统节点的情况,报告心跳状态等相关系统监控的功能,8066是数据端口,相当于数据库的访问端口。我们可以使用mysql命令访问这里两个端口:

那么mycat_user和mycat_passwd是如何配置呢,下面就需要介绍mycat中最主要的3个配置文件:server.xml,schema.xml和rule.xml。
3.1 server.xml
该配置文件是用于配置mycat的系统信息,主要有两个标签:system和user。这里的user就是上述访问mycat服务的用户,不是后端数据库的用户。如果我们使用默认的配置,server.xml大概是这样的:
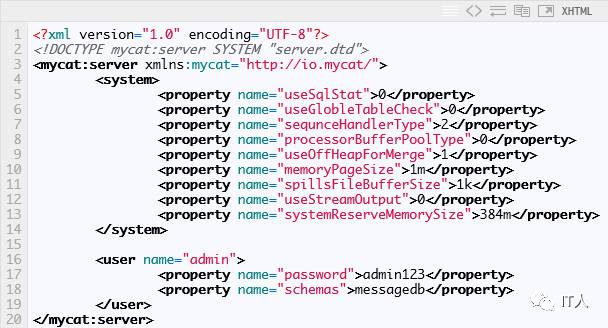
user标签下schemas属性表示该用户可以访问的数据库,可以定义多个数据库,用英文逗号隔开。schemas定义的数据库,一定要配置在后面的schema.xml文件对应的逻辑库,否则会提示无法访问。
system标签暂时使用默认的配置,不做过多的讨论。总之,先让你的猫先跑起来再考虑其他玩法。
3.2 schema.xml
schema配置文件比较复杂,也是最关键的一个配置文件,定义了mycat中的逻辑库、逻辑表,和分片的相关信息。配置如下:

几点要说明一下:
schema标签定义逻辑库,其下table子标签定义逻辑表,datanode属性定义该逻辑表需要分布到哪几个分片上,rule属性表示使用何种分片规则,这里我们选择sharding-by-month,这个规则的名称是自定义的,只要和后面的rule.xml对应起来即可
source表是一张全局表,这里需要使用type=”global”来定义,这样mycat就可以帮我们在指定的分片上克隆相同的数据,这对join查询是非常有好处的。
datanode标签定义了分片,datahost是主机名,对应dataHost标签的name属性值,database定义该主机数据库实例上的具体数据库名。
dataHost标签定义数据库实例,其下heartbeart标签表示心跳检测所使用的方法,writeHost标签定义写数据的实例,另外还有readHost标签可以定义读数据的实例,这里不考虑读写分离,仅使用写实例,因此需要把balance属性设置为0
其他属性可以自行查阅官方权威指南
最后,出于规范和安全考虑,最好不使用数据库的root用户,而是另外再创建一个用于mycat访问的用户。
3.3 rule.xml
rule.xml中定义了很多分片的规则,具体规则的算法可以参考官方权威指南,这里我们直接使用默认的就可以了,其中按自然月的分片规则配置如下:
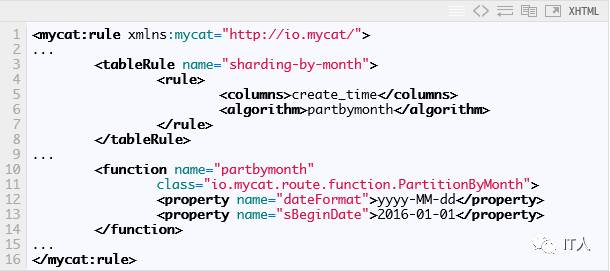
tableRule标签定义分片规则的,其下columns标签表示对数据库表中的哪个字段应用规则,algorithm指定实现算法的名称,对应的是function标签中的name属性值
function标签定义对应的实现类,以及参数,包括dateFormat(日期格式)和sBeginDate(起始日期)
说明:起始日期是用来计算数据所在的分片位置,例如2016年1月的message就会找到第1个分片,即dn1,2016年12月的message就会找到第12个分片,即dn12,但是如果出现了2017年1月的message,mycat就会去找第13个分片,但是配置文件中又没有对应的配置,那么就会抛出无法找到分片的错误。
最后再来总结一下配置文件的关系
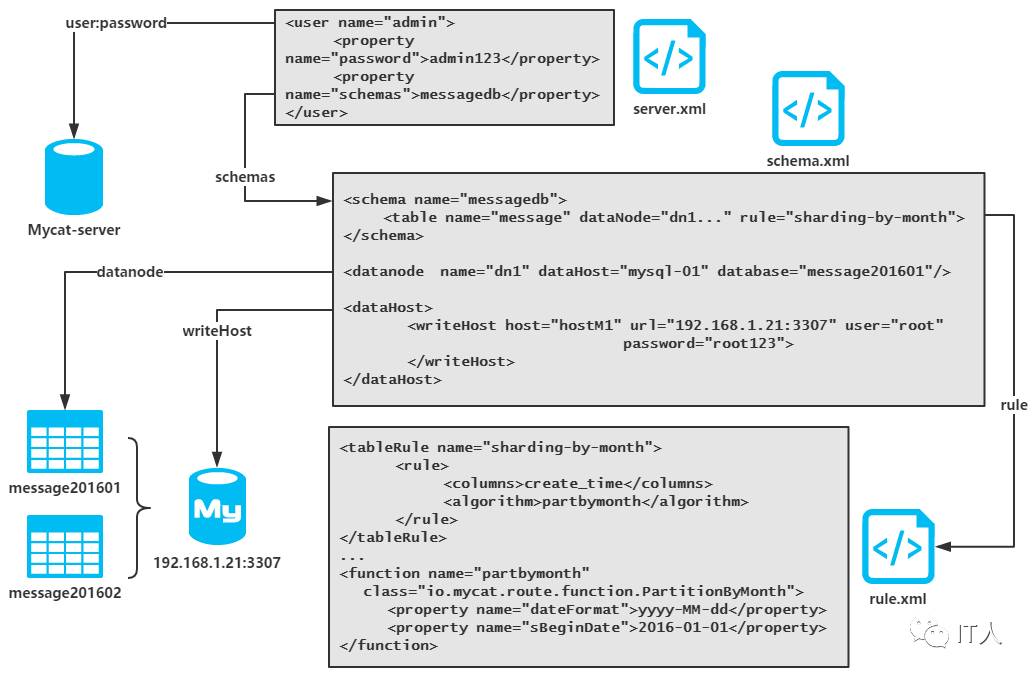
如图所示,server.xml定义了访问mycat服务的用户,以及该用户授权的数据库(逻辑库),schema.xml定义了具体的逻辑库,逻辑表,以及分片和数据库实例的信息,rule.xml分片规则和实现类。
四、测试
到这里已经完成了mycat的配置文件,但先不急着往里面灌数据,我们先访问管理端口9066,看一下运行情况:
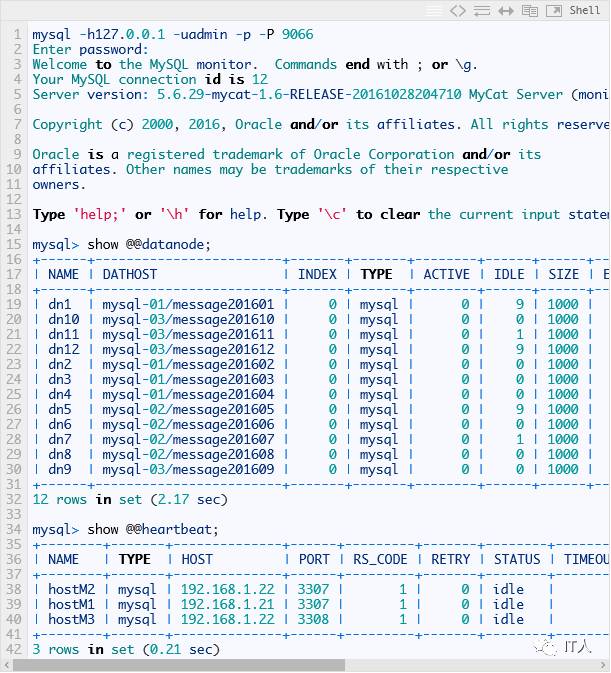
如果看到各个节点都已经出现,并且心跳状态RS_CODE=1,则表示后端数据库连接正常。
现在我们用JDBC的方式批量插入1000万数据:
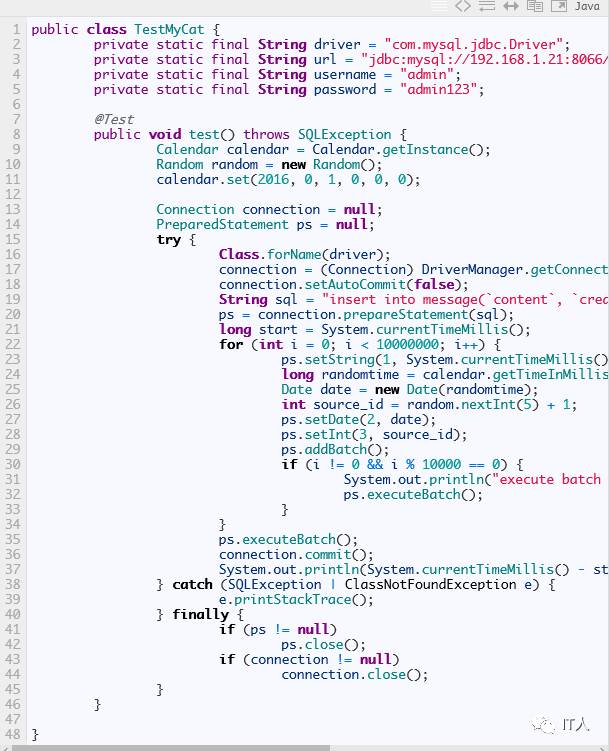
如果运行的时候报错: Multi-statement transaction required more than ‘max_binlog_cache_size’ bytes of storage;,可以适当调大一下my.cnf下的max_binlog_cache_size参数。
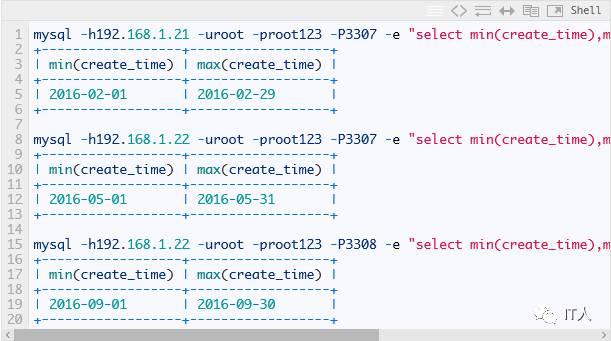
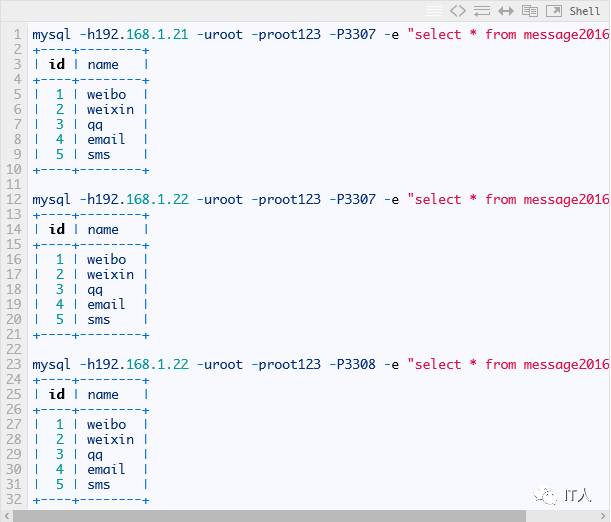
最后我们来检验一下分片的结果,其中message表中的数据根据create_time的值按月进行了分片,而source表作为全局表,则其数据出现在了每个分片上,下面贴出部分结果:
五、总结
本文就mycat分片的特性进行一次实战操作,完成了部署mycat-server以及后端mysql数据库,并以按自然月为分片规则进行了相关的配置,最后做了一个小的测试来验证分片功能的正确性。
mycat还有其他比较强大的特性还有待进一步的研究使用,下一步的工作:
完成读写分离的配置和测试
整合zookeerp实现高可用集群
六、参考资料
周继峰 冯钻优 陈胜尊 左越宗. 分布式数据库架构及企业实践:基于Mycat中间件[M]. 电子工业出版社, 2016.
mycat开源项目组. Mycat权威指南. http://mycat.io/document/Mycat_V1.6.0.pdf

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
加社群小助手申请入群(请注明“php”),专业交流微信群期待你的加入~
以上是关于MyCAT 数据分片入门实战的主要内容,如果未能解决你的问题,请参考以下文章