来测试下,Mycat你懂得多少
Posted 进阶架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了来测试下,Mycat你懂得多少相关的知识,希望对你有一定的参考价值。
前言
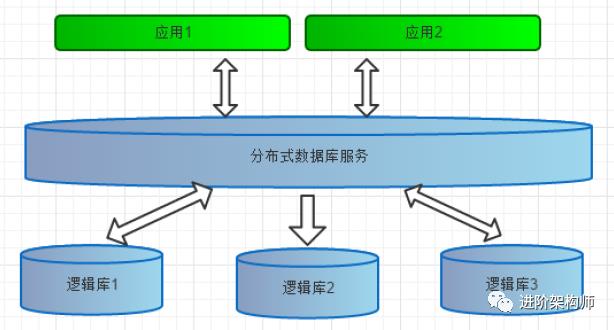
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务。
对数据进行分片处理之后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群,构成了整个完整的数据库存储。
如上图所表示,数据被分到多个分片数据库后,应用如果需要读取数据,就要需要处理多个数据源的数据。
如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处理,
原本该是专注于业务的应用,将会花大量的工作来处理分片后的问题,最重要的是每个应用处理将是完全的重复
造轮子。
所以有了数据库中间件,应用只需要集中与业务处理,大量的通用的数据聚合,事务,数据源切换都由中间
件来处理,中间件的性能与处理能力将直接决定应用的读写性能,所以一款好的数据库中间件至关重要。
逻辑库(schema)
通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道
数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
在云计算时代,数据库中间件可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个独立或者是共享的物理库,常见的如阿里云数据库服务器 RDS。
逻辑表(table)
逻辑表
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表
分片表,是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。
例如在 mycat 配置中的 t_node 就属于分片表,数据按照规则被分到 dn1,dn2 两个分片节点(dataNode)上。
<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1,dn2" rule="rule1" />-
非分片表 一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。 -
ER 表 关系型数据库是基于实体关系模型(Entity-Relationship Model)之上,通过其描述了真实世界中事物与关系,Mycat 中的 ER 表即是来源于此。根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨库操作。 表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
全局表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特性:
•变动不频繁;
•数据量总体变化不大;
•数据规模不大,很少有超过数十万条记录。
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以 Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,
尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule)
一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
全局序列号(sequence)
数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号(sequence)。
以上是关于来测试下,Mycat你懂得多少的主要内容,如果未能解决你的问题,请参考以下文章