腾讯云布道师:一次性能峰值提升10W的DB调优之旅
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯云布道师:一次性能峰值提升10W的DB调优之旅相关的知识,希望对你有一定的参考价值。
腾讯云数据库团队:继承腾讯数据库团队十多年海量存储的内部数据库运营和运维经验,推出一系列高性能关系型、分布式、文档型和缓存类数据库产品,并提供高可用性、自动化运维和易维护的云数据库综合解决方案。
经过周末两天的折腾,在大家的帮助下最终将用户 DB 的性能峰值由最初的不到 7W 的 QPS + TPS 提升至 17W,心情也由最初的忐忑过渡到现在的平静,现在想来,整个的优化过程感觉还是比较好玩的,趁着现在还有些印象,就把整个排查 & 优化过程详细记录下来,以备不时之需,也希望能给其他人一些启发。
上周团队聚餐时,老大说有一个用户使用 DB 的时候遇到了问题,现有的 DB 性能无法满足用户的性能需求。用户在对现有的 DB 进行压力测试时发现 QPS + TPS 小于 7W/S,继续加大压力的时候 Load 上涨、Idle CPU 很低、Thread running 飙升、性能下降,最终导致网站处理并发能力的下降,无法达到预期的吞吐量。
用户在对现有逻辑及吞吐量计算的基础上提出了性能指标,即 DB 的单机性能 QPS + TPS 大于 10W/S, 只有这样才能满足业务要求,否则 DB 就是整个链路的瓶颈。
由于用户的上线时间临近,上线压力比较大,老大说周末尽力搞定,如果搞不定,只能上最好的机器来解决性能问题,这样的话,成本就要上来了。(当时正在吃饭,瞬间感觉压力山大,不能好好吃肉了有木有……)
第二天还没醒就收到老大的 RTX 消息,然后怀着疑惑的心情火速上线,登录到机器上,开始了 DB 性能的调优之旅……
首先,使用 orzdba 监控工具查看了用户实例的性能状态,如下所示:
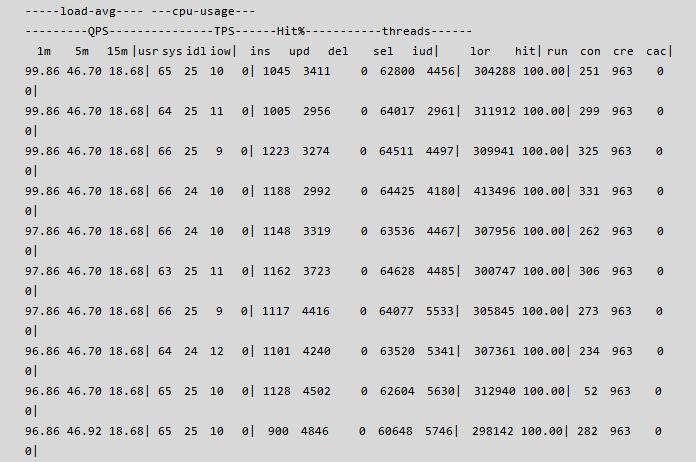
从上面的性能信息可以发现命中率 100%, 即用户基本是全内存操作,thread running 较高,CPU 有少量, thread running 彪升,到底线程在做什么呢?
怀着这样的疑问,然后执行了一下 pstack {pid of mysqld} > pid.info 以获取实例的内部线程信息,然后使用 pt-pmp pid.info 将堆栈信息进行显示,发现了如下的信息:

根据上述的 pt-pmp & pstack 文件相结合,可以看到如下堆栈:
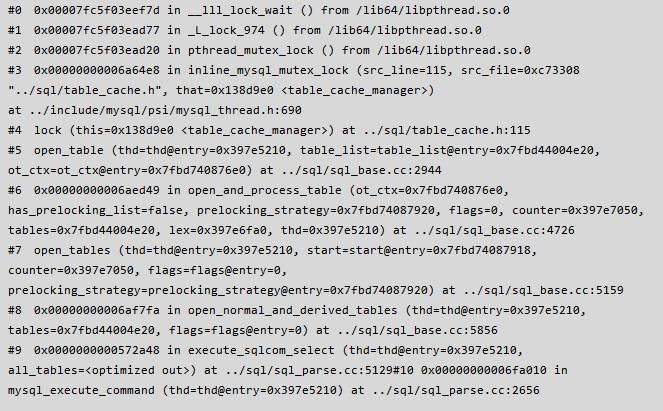
根据上面收集的信息我们可以清楚的得出以下结论:
应用在执行SQL语句的过程中,table_cache_manager 中的锁冲突比较严重;
MySQL Server 层中的 MDL_lock 冲突比较重;
实例开启了 Performance_schema 功能;
经过了上面的分析,我们需要着重查看上述问题的相关变量,变量设置的情况会对性能造成直接的影响,执行结果如下:
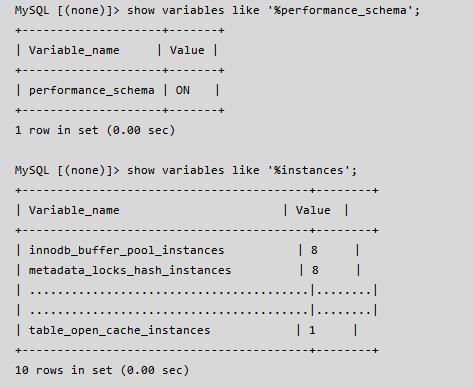
这里我们先来介绍一下上述参数在 MySQL 中的作用 & 含义:
table_open_cache_instances 简介
table_open_cache_instances 指的是 MySQL 缓存 table 句柄的分区的个数,而每一个 cache_instance 可以包含不超过table_open_cache/table_open_cache_instances 的table_cache_element,MySQL 打开表的过程可以简单的概括为:
根据线程的 thread_id 确定线程将要使用的 table_cache,即 thread_id % table_cache_instances;
从该 tabel_cache 元素中查找相关系连的 table_cache_element,如果存在转 3,如果不存在转 4;
从 2 中查找的table_cache_element 的 free_tables 中出取一个并返回,并调整 table_cache_element 中的 free_tables & used_tables 元素;
如果 2 中不存在,则重新创建一个 table, 并加入对应的 table_cache_element 的 used_tables的列表;
从以上过程可以看出,MySQL 在打开表的过程中会首先从 table_cache 中进行查找有没有可以直接使用的表句柄,有则直接使用,没有则会创建并加入到对应的 table_cache 中对应的 table_cache_element 中,从刚才提取的现场信息来看,有大量的线程在查找 table_cache 的过程中阻塞着了,而 table_open_cache_instances 的个数为 1, 因此,此参数的设置需要调整,由于 table_open_cache_instances 的大小和 线程 ID & 并发 有关系,考虑当前的并发是1000左右,于是将该植设置为 32;
MySQL 中不同的线程虽然使用各自的 table 句柄,但是共享着同一个table_share,如果想从源码上了解 table & table_share 以及 两者之间的相互,可以从变量 table_open_cache, table_open_cache_instances,table_definition_cache 入手,阅读 Table_cache_manager, Table_cache, Table_cache::get_table 等相关代码,由于篇幅限制,在此不在详述。
在 5.1 中有一个 binlog log 乱序的问题,详情及复现方法可以参考这篇文章:《alter table rename 操作导致复制中断》(http://mysqllover.com/?p=93),MDL_LOCK 就是为了解决上述问题而在 5.5 中引入的。
简单来说 MDL Lock 是 MySQL Server 层中的表锁,主要是为了控制 Server 层 DDL & DML 的并发而设计的, 但是 5.5 的设计中只有一把大锁,所以到5.6中添加了参数 metadata_locks_hash_instances 来控制分区的数量,进而实现大锁的拆分,虽然锁的拆分提高了并发的性能,但是仍然存在着不少的性能问题,所以在 5.7.4 中 MDL Lock 的实现方式采用了 lock free 算法,彻底的解决了 Server 层表锁的性能问题,而参数 metadata_locks_hash_instances 也将会在之后的某个版本中被删除掉。
参考文档:metadata_locks_hash_instances(http://dev.mysql.com/doc/refman/5.6/en/server-system-variables.html#sysvar_metadata_locks_hash_instances)
由于实例中的表的数目比较多,而 metadata_locks_hash_instances 的参数设置仅为8,因此,为了将底锁的冲突的可能性,我们将此值设置为 32。
通俗来说,performance schema 是 MySQL 的内部诊断器,用于记录 MySQL 在运行期间的各种信息,如表锁情况、mutex 竟争情况、执行语句的情况等,和 Information Schema 类似的是拥用的信息都是内存信息,而不是存在磁盘上的,但和 information_schema 有以下不同点:
information_schema 中的信息都是从 MySQL 的内存对象中读出来的,只有在需要的时候才会读取这些信息,如 processlist, profile, innodb_trx 等,不需要额外的存储或者函数调用,而 performance schema 则是通过一系列的回调函数来将这些信息额外的存储起来,使用的时候进行显示,因此 performance schema 消耗更多的 CPU & memory 资源;
Information_schema 中的表是没有表定义文件的,表结构是在内存中写死的,而 performation_schema 中的表是有表定义文件的;
实现方式不同,Information_schema 只是对内存的 traverse copy, 而 performance_schema 则使用固定的接口来进行实现;
作用不同,Information_schema 主要是轻量级的使用,即使在使用的时候也很少会有性能影响,performance_schema 则是 MySQL 的内部监控系统,可以很好的定位性能问题,但也很影响性能;
由以上的分析不难看出,在性能要求比较高的情况下,关闭 performance_schema 是一个不错的选择,因此将 performance_schema 关闭。另外关闭 performance_schema 的一个原因则是因为它本身的稳定性,因为之前在使用 performance_schema 的过程中遇到了不稳定的问题,当然,遇到一个问题我们就会修复一个,只是考虑到性能问题,我们暂时将其关闭。
Performance_schema 的详细使用说明可以参考:
performance_schema 中文文档
(http://keithlan.github.io/2015/07/17/22_performance_schema/)
MySQL_Performance_Schema 官方文档
(https://dev.mysql.com/doc/refman/5.6/en/performance-schema.html)
经过上面的分析和判断,我们对参数做了如下的调整:
table_open_cache_instances=32
metadata_locks_hash_instances=32
performance_schema=OFF
innodb_purge_threads=4
调整了以上参数后,我们重启实例,然后要求客户做新一轮的压力测试,测试部分数据如下:
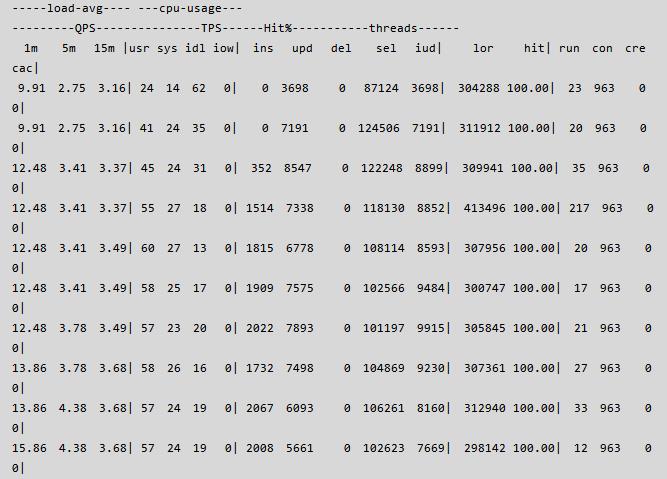
从以上的测试数据来看, QPS + TPS > 10W 已经满足要求,通过 perf top -p {pidof mysqld} 命令查看了一下系统负载,发现了一处比较吃 CPU 的地方 ut_delay,详情如下:
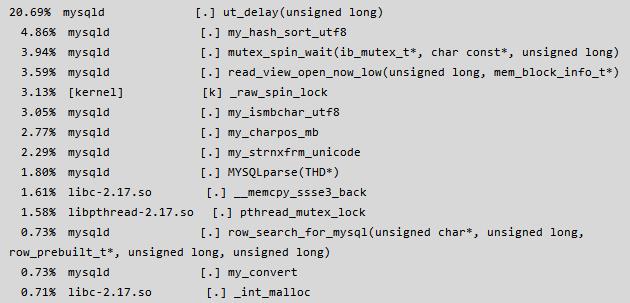
使用 perf record & perf report 进行分析,发现调用比较多的地方是:
mutex_spin_wait,于是断定 Innodb 底层资源冲突比较严重,根据以往的经验执行如下命令:
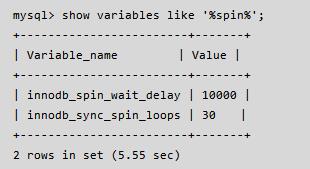
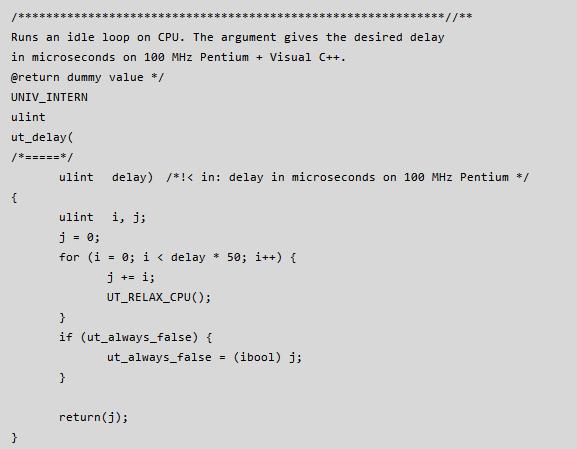
在 MySQL 内部,当 innodb 线程获取 mutex 资源而得不到满足时,会最多进行 innodb_sync_spin_loops 次尝试获取 mutex 资源,每次失败后会调用 ut_delay(ut_rnd_interval(0, srv_spin_wait_delay),导致 ut_delay 占用了过多的 CPU, 其中 ut_delay 的定义如下:
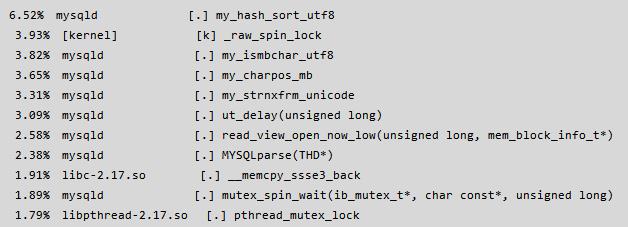
由于这两个值的设定取决于实例的负载以及资源的竟争情况,所以不断的尝试设置这两个参数的值,经过多次的尝试最终将这两个参数分别设置为:
innodb_spin_wait_delay = 6, innodb_sync_spin_loops = 20 (请注意这两个值不是推荐值!!) 才将 ut_delay 的占用资源降下来,最终降低了不必要的 CPU 消耗的同时 idle cpu 也稳定在了 20+,具体资源占用详情如下:
优化到这个地步似乎达到了客户要求的性能,即 DB 单机性能为 QPS + TPS > 10W,可是如果并发量在加大,我们的 DB 能扛住更高的压力吗?
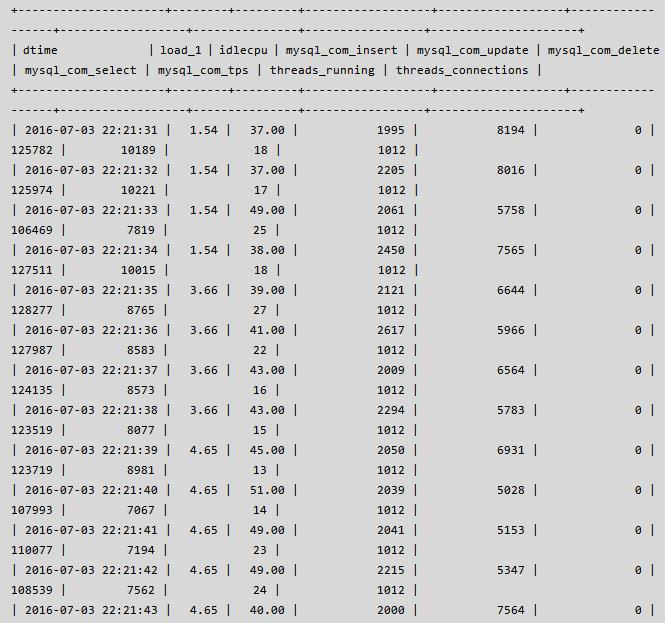
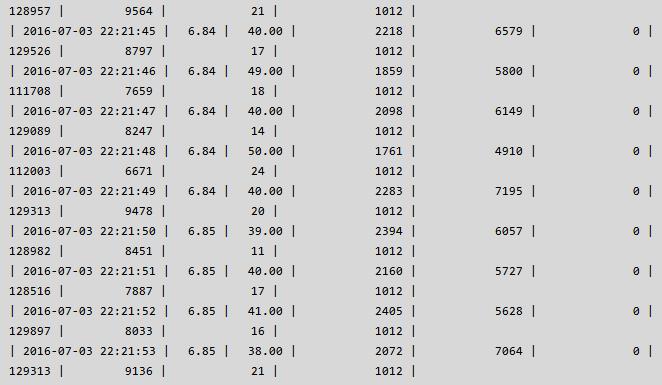
经过上面参数的调整,DB 已经不是性能的瓶颈,应用的吞吐量由之前的 1100 -> 1400+,但是离 2000 的吞吐量还比较远,瓶颈出现在了应用端,为了增加吞吐量,客户又增加了几台客户端机器,连接数也由之前的 900+ 上升到 1000+,此时发现 DB 虽然能够响应,但偶尔会出现 thread running 飙高的情况,具体运行状态如下,其中 mysql_com_tps = (mysql_com_insert + mysql_com_update + mysql_com_delete):
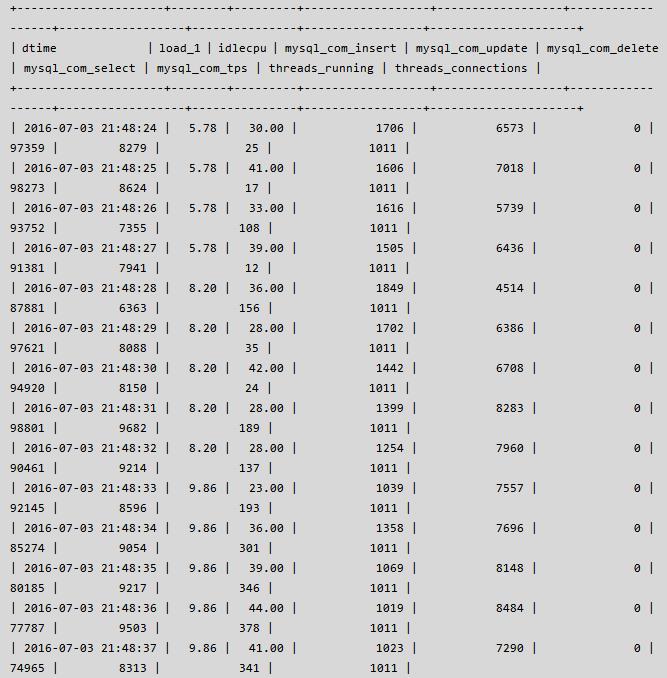
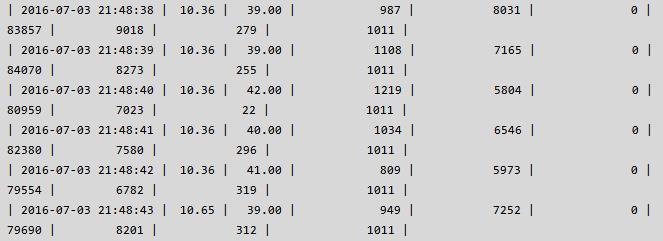
Thread running 的偶尔飙升引起了我的注意,说明内部必然有冲突,随着压力和并发量的不断增大,应用可能会受到类似之前的影响,因此很有必要查看其中的原因并尽最大的努力解决之。通过仔细观察 thread running & mysql com 信息,当 thread running 较高 & com 信息较低的时候,执行了 pt-pmp -p {pid of mysqld},抓到了以下信息:

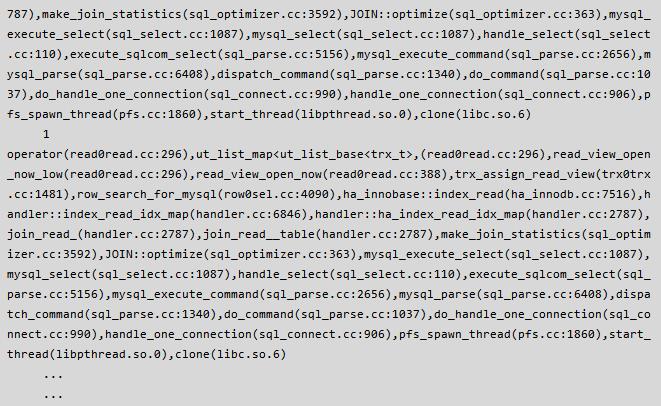
从上面的现场信息不难看出有很大一部分线程是在执行 read_view 的相关操作中被阻塞着了,那么什么是 read view,它的作用是什么,为什么会有大量的线程执行这个操作的时候被阻塞呢?
read view 又称读视图,用于存储事务创建时的活跃事务集合。当事务创建时,线程会对 trx_sys 上全局锁,然后遍历当前活跃事务列表,将当前活跃事务的ID存储在数组中的同时,记录最大事务 low_limit_id & 最小事务 high_limit_id & 最小序列化事务 low_limit_no。
InnoDB record 格式包含 {记录头,主建,Trx_id,roll_ptr, extra_column} 等信息。
当事务执行时,凡是大于low_limit_id 的数据对于事务是不可见的,凡是事务小于 high_limit_id 的数据都是可见的,事务 ID 是 read_view 数组中的某一个时也是不可见的,Purge thread 在执行 Purge 操作时,凡是小于 low_limit_no 的数据,都是可以被 Purge 的,因此, read view 是 MySQL MVCC 实现的基础。
事务创建时的步骤如下:
对 trx_sys->mutex 全局上锁;
顺序扫描 trx_sys->rw_trx_list,对 read_view 中的元素分配内存并进行赋值,主要包括活跃事务ID的集合的创建,low_limit_id , high_limit_id, low_limit_no 等;
将该 read_view 添加到有序列表 trx_sys->view_list中;
释放 trx_sys->mutex 锁;
由于read_view 的创建和销毁都需要获取 trx_sys->mutex, 当并发量很大的时候,事务链表会比较长,又由于遍历本身也是一个费时的工作,所以此处便成为了瓶颈,既然我们遇到了这个问题,那么社区应该也有类似的问题。
首先,我们看一下bug#49169(https://bugs.mysql.com/bug.php?id=49169),read_view_open_now is inefficient with many concurrent sessions, 即当并发量很大时 read_view_open_now 效率低下的问题,问题的原因主要有以下几个:
整个创建过程一直持有 trx_sys->mutex 锁;
read_view 的内存在每次创建中被分配,事务提交后被释放;
需要遍历 trx_sys->trx_list (5.5) 或 trx_sys->rw_list (5.6);
并发较大,活跃事务链表过长时,会在 trx_sys->mutex 上有较大的消耗;
该 bug 从 MySQL 5.1 的时候被 mrak 大神提出以来,一直到 MySQL 5.7 才被官方完整的解决,其中的解决过程也挺曲折的,另外 Percona 在 5.5 的时候就也推出了解决问题的办法,实现也相对简单好多,但没有 MySQL 5.7 方法的彻底,咱们分别看一下这两种解决方法以及 CDB 内核在这方面的改动。
Percona 为了解决上述描述的问题,对trx_sys做了以下修改:
在 trx_sys下维护一个全局的事务ID的有序集合,事务的 创建 & 销毁 的同时将事务的 ID 从这个集合中移除;
在 trx_sys下维护一个有序的已分配序列号的事务列表,已记录拥有最小序列号的事务,供 purge 时使用;
减少不必要的内存分配,为每一个 trx_t 缓存一个 read_view,read_view 数组的大小根据创建时的活跃全局事务 ID 集合做必要的调整;
做了上面的调整后,事务在创建过程中则不需要遍历 trx_sys->trx_list(version 5.5),直接使用 memcpy 即可获得活跃事务的ID,并且缓存的使用也大大减少了内存的不必要分配;
更详细的信息及源码可以参考 Alexey (sysbench owner, MySQL 另一大神)提交的代码,commit message 详情如下:
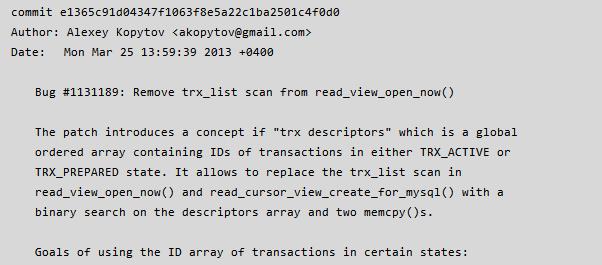
为了解决 read view 问题,5.6 做了以下几件事情:
将 5.5 的 trx_list 拆分为 ro_trx_list & rw_trx_list, 由于只读事务不会对数据进行修改,所以在创建视图的同时就只需要扫描 rw_trx_list 即可;
auto-commit-non-locking-ro transactions 的特殊优化;
添加语法 START TRANSACTION READ ONLY 用于声名事务是只读事务;
经过上面的修改,似乎解决了 read view 的问题,但实际却不然,因为他只是解决了事务链表的长度,创建时遍历&内存消耗的开销是没有解决的,并且使用上述特性需要修改应用程序,这一点是比较困难的,因此,5.7为了彻底的解决 read view 的性能问题,做了以下事情:
Refactor the MVCC code
Reuse read views for AC-NL-RO selects
Use a pool of read views
Add MVCC class
Use a trx_id to trx_t* map
Keep the active trx_id_ts in a vector.
Pre-allocate a small cache of record and table locks
Avoid extra work when a transaction is tagged as read-only (during commit).
General code cleanup
Get rid of trx_sys_t::ro_trx_list. Adding and removing a transaction from the ro_trx_list is very costly.
经过了上面的代码重构,5.7 中很少看到 trx_sys->mutex 的性能瓶颈,有想更详细了解的同学可以看一下这些内容:
为了解决 Read view 的性能问题,简单的说 CDB 内核团队对于Read view 主要做了以下事情:
backport percona 的 read view 相关修改到 CDB MySQL中;
参照 5.7 的实现,在 5.6 中将 ro_trx_list 移除;
经过上面的修改彻底的解决了 read_view 的性能问题,在经历了大量 稳定性测试 & 性能测试 后,目前灰度发布中。
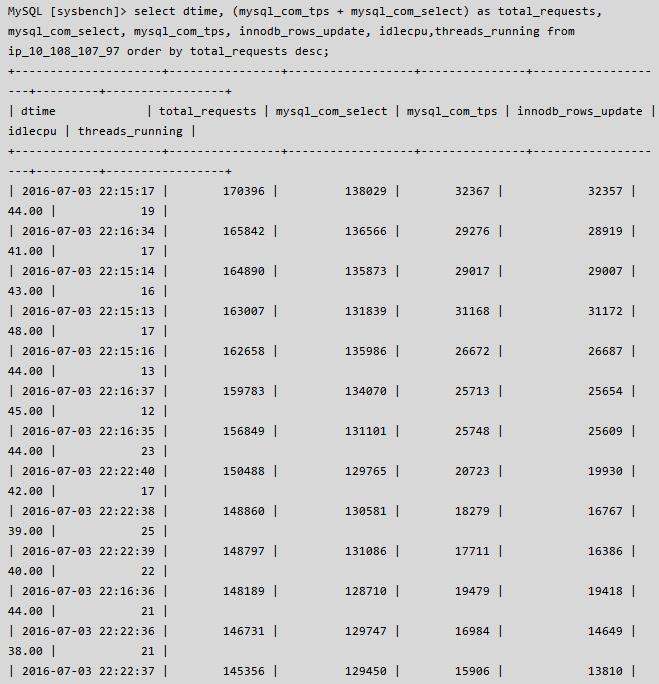
鉴于当前存在的问题,为了解决客户的燃眉之急,决定上一个新版本,和客户联系后,可以重启实例,然后进行了替换操作,替换后的性能效果如下,可以看到 cpu 使用率、load、thread running 降低的同时 QPS + TPS 性能上升,至此问题真正觉得问题应该解决了,余下的就是等客户的反馈了。
将监控数据入库,查看峰值 & 当时的负载情况,详情如下:
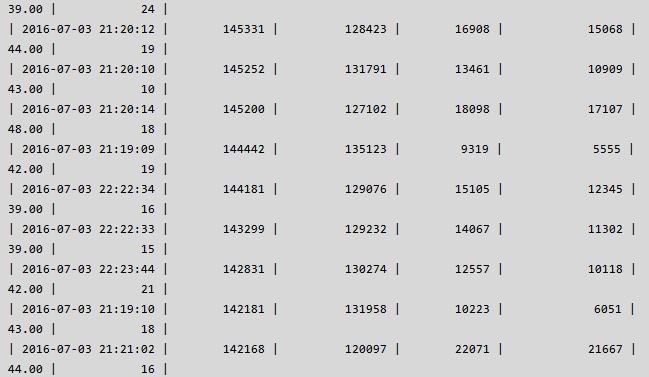
真的完美了吗,其实不是这样的,我们还有很多的事情要做,因为在解决问题的过程中,我们通过 pstack & pt-pmp 抓到了很多有用的信息,有一些是暂时没有解决的,如:
InnoDB内部表锁冲突严重;
MDL Lock 即使扩大也存在着不小的影响;
内存分配也有一些需要优化的地方;
执行计划的计算代价比较高;
thread running 彪高时没有可以控制的方法;
….
由于时间问题我们暂时将遇到的问题一一记下,一个一个解决,我们相信 CDB 的内核会越来越强大,在提升性能的同时也不断的提升稳定性,我们一步一步踏在当下,努力变得更好!
相关专题:
◆ 近期热文 ◆
◆ 专家专栏 ◆
丨丨丨丨丨
丨丨丨丨丨丨
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会上海站
峰会官网:www.gdevops.com
以上是关于腾讯云布道师:一次性能峰值提升10W的DB调优之旅的主要内容,如果未能解决你的问题,请参考以下文章
如何正确使用云计算?腾讯云布道师的答案是Cloud Native