腾讯云数据库智能化海量运维的建设与实践(附PPT)
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯云数据库智能化海量运维的建设与实践(附PPT)相关的知识,希望对你有一定的参考价值。
本文根据鲁越老师在〖Gdevops 2018全球敏捷运维峰会成都站〗现场演讲整理而成。

(点击“阅读原文”获取鲁越演讲完整PPT)
讲师介绍
鲁越,腾讯云数据库架构师团队负责人,主要负责mysql、Redis等数据库售前架构、运维、调优等工作,曾就职于网易和尼比鲁。
大家好,今天很高兴能和大家分享一下我们腾讯云数据库海量运维的经验,主要分为以下三部分:
数据库架构师团队的组建
自动化运维平台的建设
智能海量运维的实践


由于数据库产品的特殊性和复杂性,我们在平时服务客户的过程中常遇到一些问题,例如:分布在各行各业的客户,他们会有不同的场景需求,这对于数据库的应用来说存在有非常大的差别。而我们的售前架构师可能没办法对各行各业在数据库方面的应用、对不同客户需求的架构都做到非常精通,因此无法推荐出最优的架构。
另一方面,我们的客户非常多,但可能我们的一些售后服务工程师对于这么复杂的数据库产品并不是非常精通,对于难度较大的问题不能做到完全覆盖,或是与客户交流不够平滑等,所以服务质量亟需提高。
基于以上两大原因,我们组建了数据库架构师团队。
架构师团队组建起来后,我们整个数据库产品的服务体系就变成了以下这样一个三层架构:第一层是运维,负责处理平台稳定性相关的工作;第二层是架构师,负责在中间督促重难点的攻坚,包括数据库的建设、运维工具的建设等等;第三层是一线服务工程师,负责处理主要的咨询类、流程类的问题。
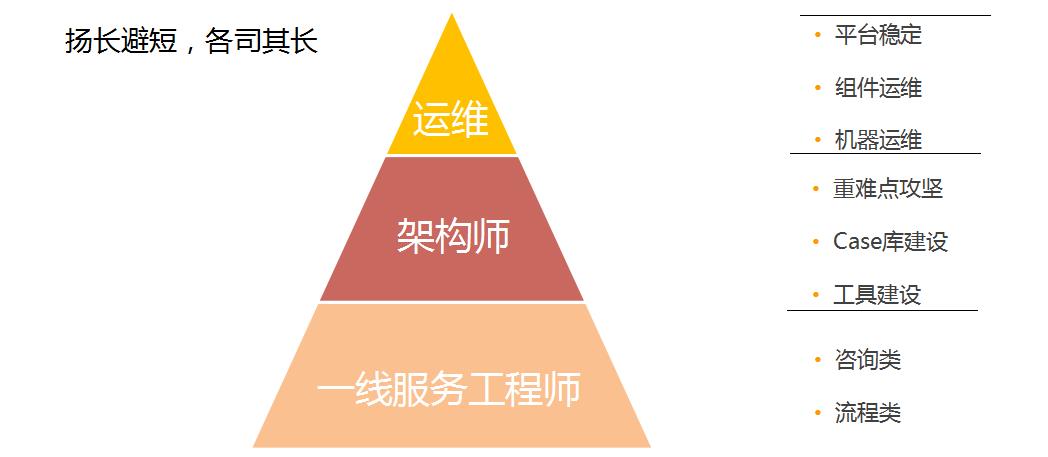
目前整个架构师团队的工作包括四方面:
客户运营:在进行数据运营的同时,与客户做更多沟通,包括跟进客户在使用数据库时遇到的各种难题;
解决方案:包括基础解决方案和行业解决方案;
服务体系:包括平台运维和基础产品运维;
平台建设:包括客户运营平台、解决方案出口、支撑服务体系。
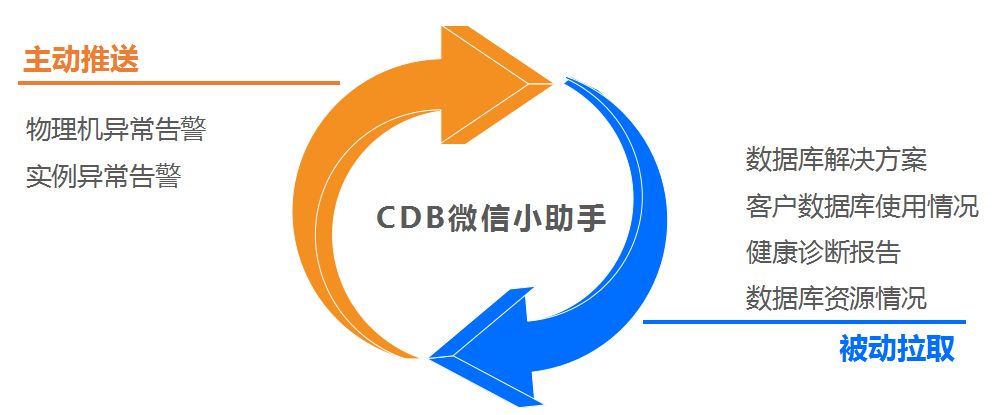
其中,在运营平台建设方面,我们做了一个CDB微信小助手,可以实现主动推送和被动拉取,帮助我们的一线同事更好地服务客户。
要更好地服务客户、提高服务质量,光有数据库架构师团队和售后服务体系是不够的,我们还要有一个非常稳定的自动化运维平台来支持环境。因此,为什么需要自动化运维平台,这个问题的答案是显而易见的。到目前为止,我们一共有10W+的实例、2W+的物理机,对于平台的稳定性要求肯定是非常高。
资源管理:包括实例的象限上限、物理机的管理和部署等;
运维操作:包括升级、上限等功能;
监控:一方面是数据库性能方面的监控,包括QPS、CPU相关的性能监控;二是可用性方面的监控。
自愈:自动发现数据库的一些常见问题,比如发现了复制异常,平台会主动对它进行恢复。
自动化运维平台的整体架构从下往上共分为三层,其中最底层是APP的入口,即我们的客户端;中间层是客户入口;最上层是平台后端。
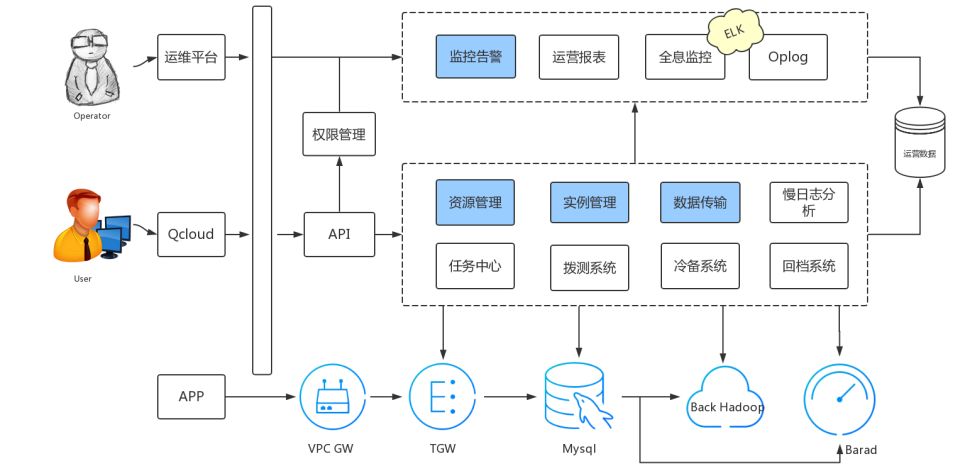
从客户端连接到APP这一层,需要经过两个架构,我们MySQL的备份会存储到集群,而性能监控的数据会上传到一个模块来实时展示我们的监控。在客户端这一层,可以通过官网或者API的入口进入到我们的自动化运维管理平台,可以进行资源管理、实例管理、数据传输等系统性的操作。我们的运维平台,除了可以进行这样的一些操作以外,还可以进行监控告警、运营报表、全息监控等操作。我们整个平台的任何一个操作的数据,都会汇总到运营数据库里,去支持我们的后端做一些包括大数据方面的分析。
整个自动化运维平台的模块是非常多的,在此我将重点分享一下监控模块。前面也提及到了,我们的监控模块分为两个部分,第一部分是性能方面的监控,第二部分是可用性方面的监控。
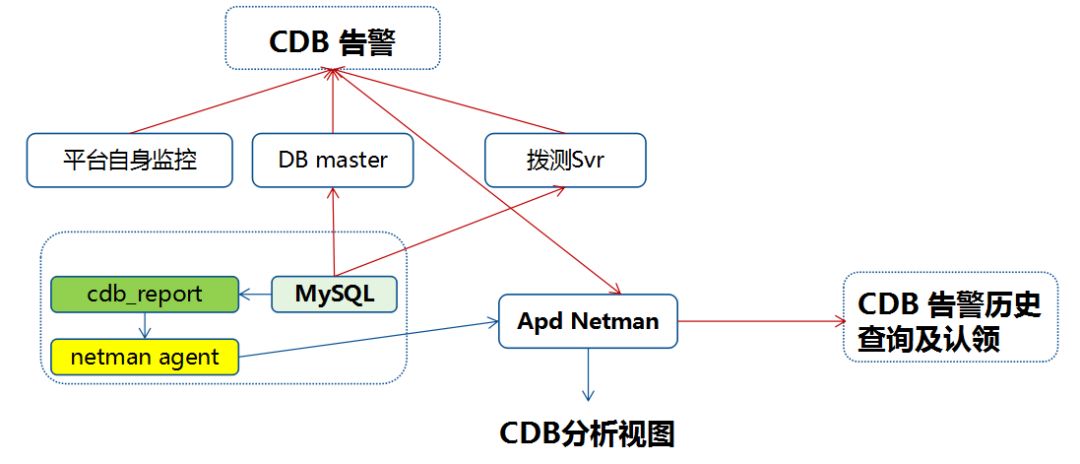
如上图所示,我们的监控模块主要是通过两面两个主线组成,一个是DB master,一个是拨测Svr。如果监测到有异常的话,会把这个信息发送到DB master,收到反馈的实例异常的信息之后,会通过长链接,再去验证是否真的异常。
CDB实例方面的性能监控,主要是通过cdb_report这个模块去监控的,会实时拉取性能方面的监控,将数据、包括CDB告警都汇总到我们的Apd Netman模块,这是比较重要的一个组件。
在一个普通场景下,拨测Svr的操作比较简单,但这样的场景在海量实例的架构下,可能会有什么问题?主要包括两点,第一点是拨测Svr的性能问题,也就是每一次在有这么多实例的情况下,拨测请求是否能够成功发出、按时发出;如果这个拨测Svr的性能不太好,会直接影响到每一次拨测Svr的时间间隔。如果拨测Svr性能不好,只能被迫地去把拨测Svr的时间间隔调大,这样对我们发现实例的问题可能是不及时的。第二点是拨测Svr自身的问题,如果拨测Svr是一个单点的话,万一它挂掉了,整个实例的状态对于我们来说都是不可知的,将会是非常危险的状态。
基于以上两点原因,我们在海量场景下的拨测Svr设计会考虑到以下三点优化目标:
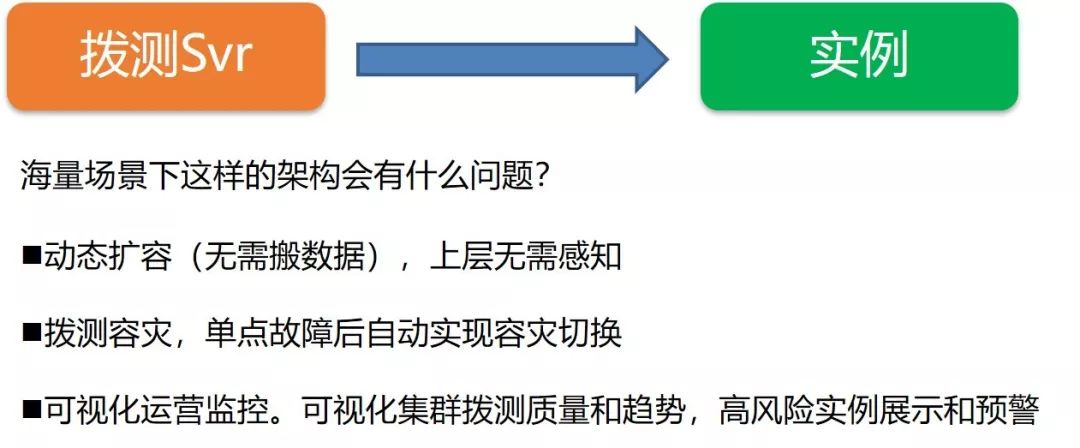
根据这三点优化目标,我们做出了如下图所示的拨测Svr架构。这个节点又会将这些实例发射到后面的pingSvr的节点,是实际去进行拨测操作的节点,这个节点在执行了拨测操作之后,会将拨测失败结果存入DB中,会有一个alarmChecker去实时读取,然后进行告警。不管是成功还是失败的请求,全部都会写进去,会有模块去拉取,并实时地存入数据库中。在这些节点中,其实都有一个灾备的部署。
经过实践和思考,发现在海量数据运维中,我们的自动化运维平台还不能解决以下这些问题:
定制化服务。不同行业的场景对于数据库的应用有着非常大差异,其实我们可以根据不同的使用场景为数据库实现定制化和优化的服务。
数据库问题自动诊断和调优。
因此,腾讯内部目前正在研发一个智能化的产品,可以通过包括数据挖掘,或是架构师与客户沟通等方式,对客户的数据库应用场景进行画像,从而实现定制化服务。
从数据挖掘的结果以及平常与客户的一些沟通来看,我们把一些比较特殊的使用方法总结为以下四种类型:
计算型应用:比如一个报表类的应用,可能会需要在一段时间内,频繁地去获取计算资源;
存储型应用:比如一个历史数据存储的应用;
流量型应用:会拉取大量的数据;
热点型应用:比如一个新闻类或红包类的应用,可能在低峰和高峰的界限会非常明显。
针对这四种特殊的使用方法,我们其实可以做一些定制化的服务,如下图所示:
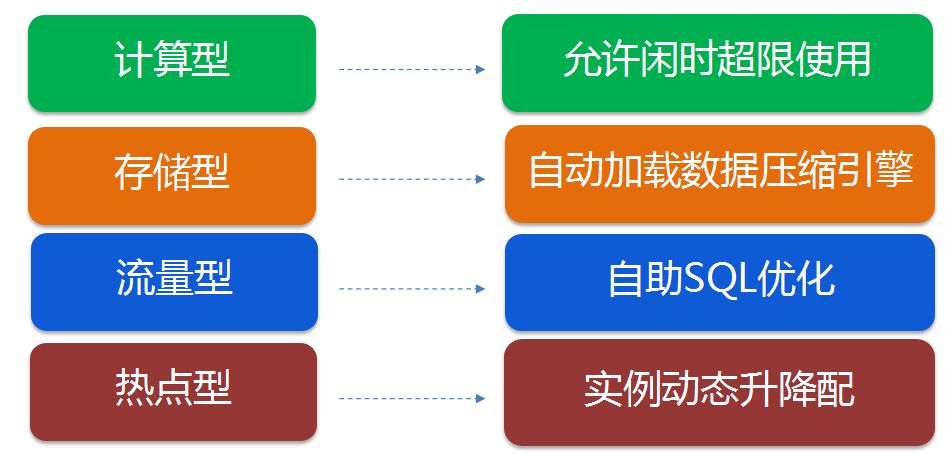
对于计算型应用,如BI报表类,它的业务特点是凌晨才执行,而整个机器在凌晨这个时间段内是比较空闲的,所以我们就可以针对这样的计算型场景,进行一些允许闲时超用的优化。
对于存储型应用,客户可能比较关心的是整个容量的使用情况,那么我们就可以相应地提供自动加载、数据压缩的压缩引擎。
对于流量型应用,可能会对SQL的要求非常高,如果中间有一两个性能不是特别好的SQL,就可能会影响到整个数据库。所以对于这种应用,我们可以给客户提供一个类似自助SQL优化的工具,帮助客户把SQL做一定的优化。
对于热点型应用,我们可以提供一个实例动态升降配的功能,在业务高峰前,快速地将这个实例升到一个较高的配置。
针对前文提到的数据库自动调优的问题,我们可以做一个实时分析和预测分析的工作,来分析实例的质量得分。
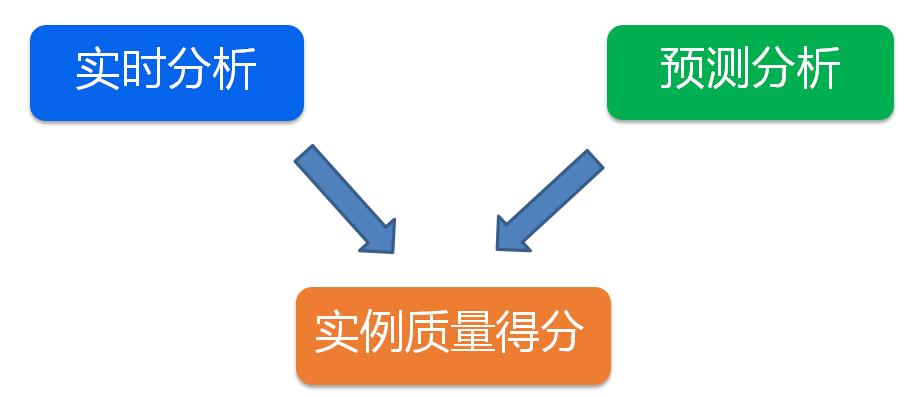
其中,预测分析是通过实例过去的历史数据,来分析它在未来两到三个月的走势。其实这个分析也是可以做定制化的,例如上文提及的计算型应用,如果客户对CPU比较敏感,我们在分析时就可以把CUP使用权重的比例调大;如果是对存储、空间利用率比较敏感,我们可以把存储方面的一些指标相应调大。通过这样的预测分析,再加上大数据、AI的一些模型,我们就可以得出一个实例得分的指标,并以此自动地优化数据库,或是提出一些优化建议。
Q1:刚讲的内容中有一块是关于拨测的,想请问平常是不是拨测也会通过一个核心的表现?
A1:这个会做,我们也会去做检测,看它是不是可写的,这不仅仅是包括网络上的,我们还可能对数据库进行操作。
Q2:很多人的数据库场景,无论是日志还是流程,直接通过终端进去也可以看到实例的健康状况,那拨测的操作类型跟这个相比有什么优越的地方?
A2:拨测主要就是快速以及检测实例的可用性,如果发现实例不可用,就需要马上做切换,让这个时间尽量降到最低,保证对业务的影响最小。相对于其他的日志,它会非常快速地发现问题,区别就在这里。
Q3:刚刚看了拨测的架构,目前还是中心化的,腾讯有没有做去中心化的呢?
A3:会考虑,因为我们虽然在拨测上做了优化,但其实整个性能方面还没有做到非常完善,我们会在这方面再做一些优化。目前来说,现在用的还是这一套,可能在我们的产品推出之后,就会推到腾讯云上面去。
Q4:想请问一下腾讯云的MySQL是采用什么方式来保证数据的一致性和实例的可用性?
A4:数据一致性是通过主动复制的方式来保持,我们可以提供一主多从的形式,跨服务器地部署,还可以提供灾备实例的功能。而实例的可用性,我们是通过拨测的方式来快速发现、定位实例的问题,一旦发生问题,会通过快速的主动切换的方式,去保证实例的高可用。
追问:切换的话也是比如说延迟达到多少,然后再进行不同的那种定级、定位吗?
A:如果是延迟的话,是不能切的,但是在我们平时的监控过程中,会对这个东西非常关注。如果发现有主动延迟的实例,会通过各种手段去消除这样的延迟。比如说5.5或5.6的版本就已经这样了,5.7的版本可以使用官方原生的控制。从目前腾讯云的实例情况来看,有主从延迟的实例还是比较少。

想了解更多关于智能运维的转型与落地?
不妨来“2018 DAMS中国数据资产管理峰会”
继续听听腾讯、轻维软件等名企运维大牛怎么说
扫描以下二维码,查看峰会详情及报名↓
↓↓↓ 点这里下载本文PPT
以上是关于腾讯云数据库智能化海量运维的建设与实践(附PPT)的主要内容,如果未能解决你的问题,请参考以下文章