揭秘腾讯云上的机器学习平台TI-ONE
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘腾讯云上的机器学习平台TI-ONE相关的知识,希望对你有一定的参考价值。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
以下为嘉宾分享的全文演讲稿(有改动):

最近大家有没有看漫威的《复仇者联盟 3》?
其中钢铁侠的战甲就是用金属钛制造的,钛具有质量轻、强度高的特点,而 TI-ONE 是人工智能平台,因此我们用了科技感十足的名字“智能钛”来形容它。

人工智能的重要性不需要我再强调,Andrew Ng 在 Spark Summit 2017 上提出《AI: The new Electricity》。
各大公司也相争提出自己的机器学习平台,比如说微软的 CNTK,Google 的 Tensorflow 等等。
但是回答为什么需要 TI-ONE 这个问题,还要从云计算的特点和机器学习的生命周期出发。
在云上,我们偏向云服务化,基础设施服务化,平台服务化,算法服务化,机器学习算法也不例外。
但是机器学算法有一个漫长的生命周期,从数据获取到数据预处理再到选择一个框架并编写算法,然后训练得到一个模型,最后用这个模型进行预测。在云上我们还要对模型进行服务化。
如此漫长的过程,所以我们需要加速机器学习的生命周期,加速模型的服务化,这就是我们需要 TI-ONE 的原因。
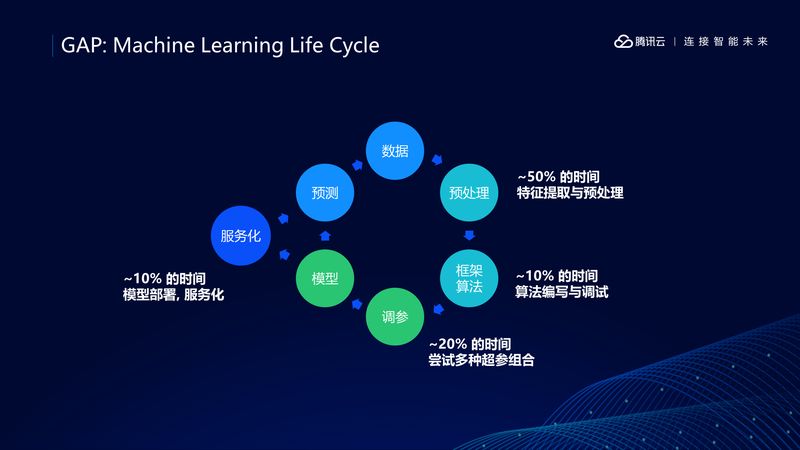
具体而言,TI-ONE 提供了如下功能:
首先整合了数据预处理平台,提高数据预处理效率。
支持主流机器学习框架,内置常用算法,以拖拽的方式就能完成算法开发。
支持自动调参,支持多个层面的协作,支持了一键模型部署和服务化,还有在线推理。
用开发者的语言来说,TI-ONE 就是腾讯云上的机器学习 IDE。

我将从架构,工作流,调参,协作,部署等这几个方面进行分享。

TI-ONE 是一个层次架构,最下层是 COS 存储层,存储层之上是 GaiaStack 资源调度层,GaiaStack 赋予 TI One 很多商业特性,后面我会展开分享。
调度层之上是计算框架层,我们整合了 Tensorflow,PyTorch,XGBoost,Angel 和 Spark 等,其中 Angel 是腾讯自研的,Spark 是腾讯增强的。
算法方面,我们集成了大量的常用算法,既有 CNN、RNN、DBN 等深度学习算法,也有的 GBDT、FFM 等传统机器学习算法。用户可以用这些算法训练自己的模型,支持业务,比如图象识别、语音识别、精准推荐和实时风控等等。
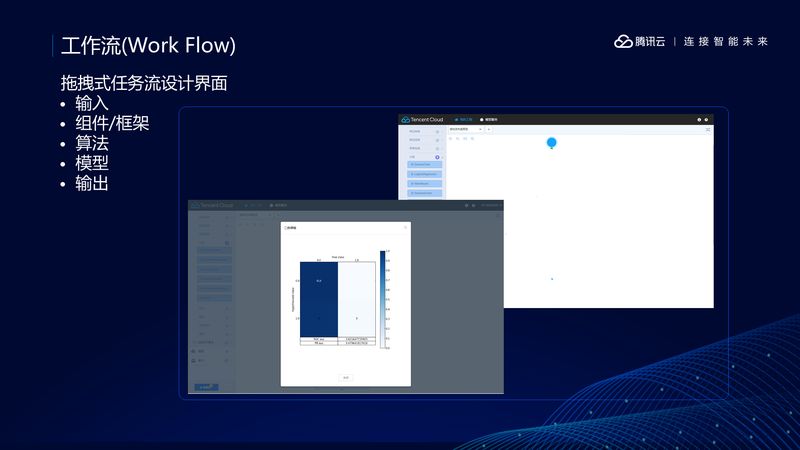
TI-ONE 为用户提供了一个图形化开发界面,以拖拽方式就能开发一个机器学习算法,这里提供一个例子:
从 COS 层或本地文件系统中获得数据
对数据进行预处理
对数据进行切分,需要指出的是,这里是将数据切分成训练集和验证集,而不是测试集
然后用拖拽的方式选择一种算法,以逻揖回归为例
设置算法需要的参数
训练得到模型
如果要验证这个算法也很简单,只要:
从存储层中获得数据
对数据进行预处理
输入到模型
算法评估
运行完成后会给出混淆矩阵和 AUC 值。
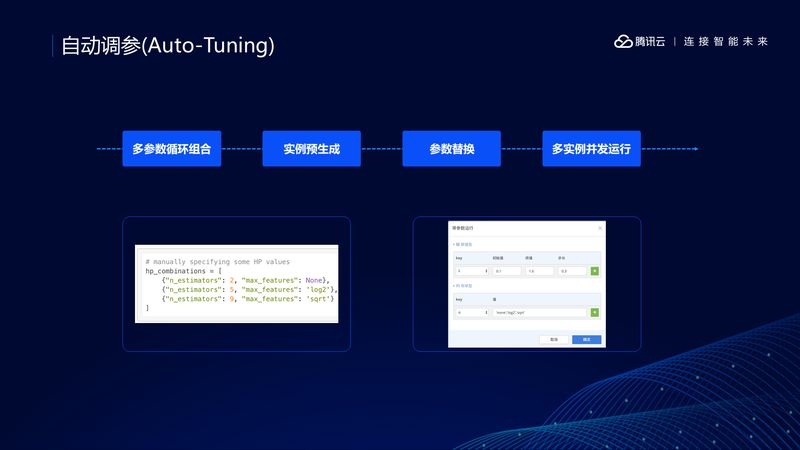
调参是机器学习的重要环节,而且非常具有技巧性,TI-ONE 提供了自动化的调参工具,特点是通过参数组合产生多个实例,然后并行运行这些实例,从这些实例中选出效果最好的一个。
举个例子,假设你要训练一个随机森林,你要决定森林中树的棵数和训练每棵树所需要的特征数,只要给定一个参数组合,然后交给 TI-ONE,TI-ONE 可以帮你选择最好的组合。
在另一些情况下,我们可能需要对一些正则化超参调优,我们只要给定一个范围,然后交给 TI-ONE,TI-ONE 就可以帮助我们选择最优的参数。
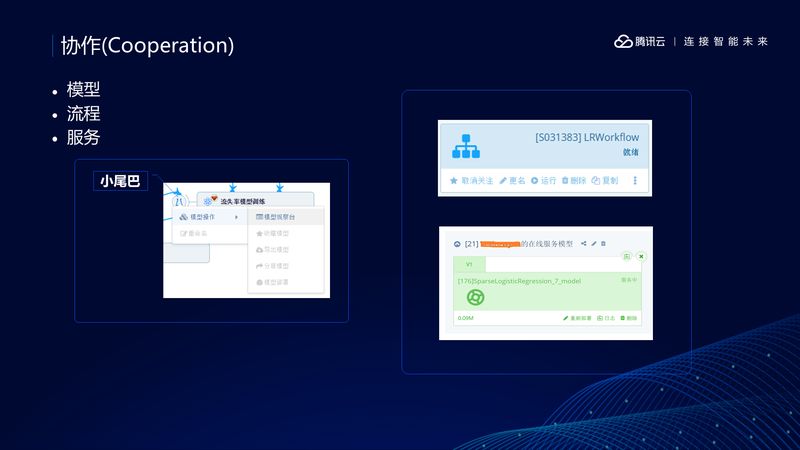
协作对于机器学习也很重要,TI-ONE 提供了多个层面的协作。
第一是模型层面的分享,训练好的模型可以分享给你的同事。比如你们俩同时对同一个业务开发算法,想比较谁的精度更高,就可以互相分享这个模型。
第二是工作流层面的分享,工作流就是机器学习生命周期,分享工作流,就是分享整个机器学习生命周期。假设你前面做了一个皮肤推荐的任务,后来要做装备推荐的任务,基本上只要小改动就可以了。
第三个是服务层面的共享,模型部署好后还可以共享,你可以把模型分享给后台人员,让他(她)帮你定位问题。
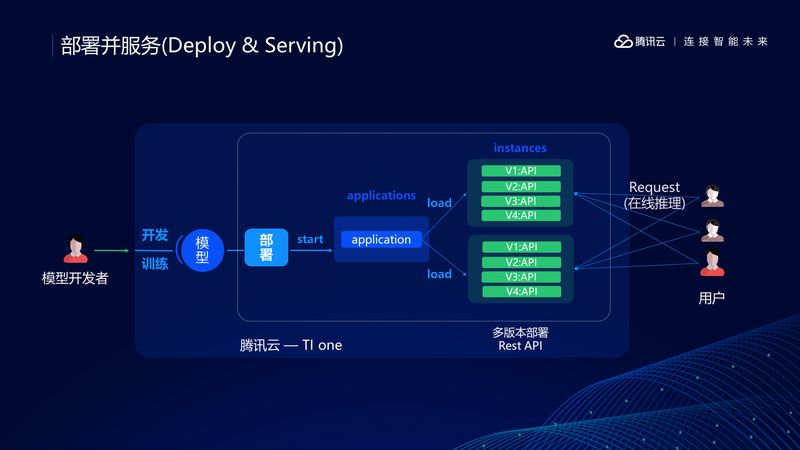
部署和服务是云上机器学习和传统学习的不同之处。
TI-ONE 提供了一键式部署工具。
我们可以将训练好的模型部署成 Application, 然后装载成多个实例,一个实例中还允许有不同版本。
第三方的用户和模型的开发者就可以用 REST API 去调用,非常方便。
前面我们讲了 TI-ONE 的特点,开发者肯定想知道它背后的设计之道。
我喜欢用冰山理论来解释事物背后的原理,前面看到的不管是工作流,还是调参,协作和部署工具,这些只是冰山一角,水下面是什么呢?
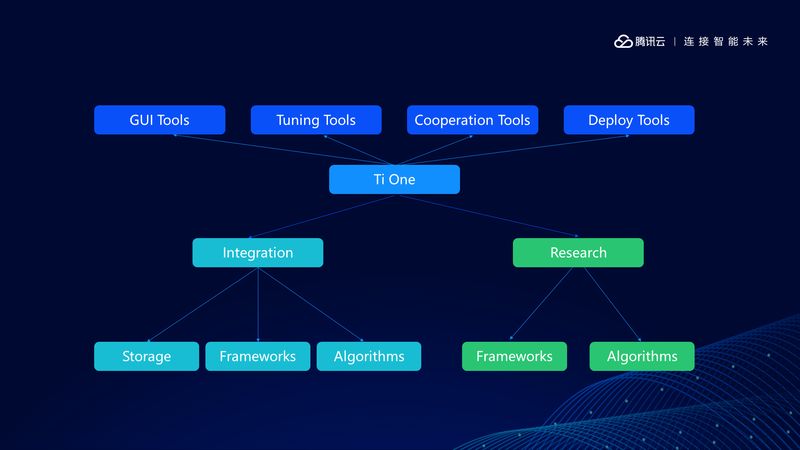
我们认为一部分原因是整合,我们整合了 COS 存储,整合了 GaiaStack 调度,整合了常用的机器学习框架和算法,但是仅仅整合还是不够,我们还需要自主研究构建差异化的竞争力,这个就是 TI-ONE 的特别之处。
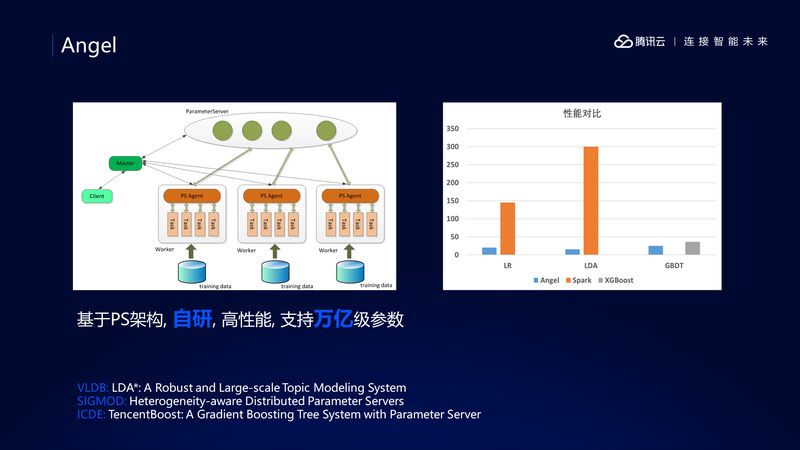
第一个特别之处是 Angel,Angel 是腾讯自研的机器学习的框架,它克服了 Spark 将模型放在单个节点的不足,通过对底层数学库的优化,它可以支持万亿级参数的模型,放眼业界,能支持如此大模型的计算框架也是凤毛菱角。
算法方面,我们实现了常用的传统机器学习算法,比如逻辑回归,SVM 等等,其中还有一些是我们原创的, 如 LAD* 就是我们发表在 VLDB 上的成果。
性能方面,我们比较了 Angel 和 Spark, XGBoost 等平台,发现 Angel 性能表现非常强悍,有些算法的性能是 Spark 的 20+ 倍。
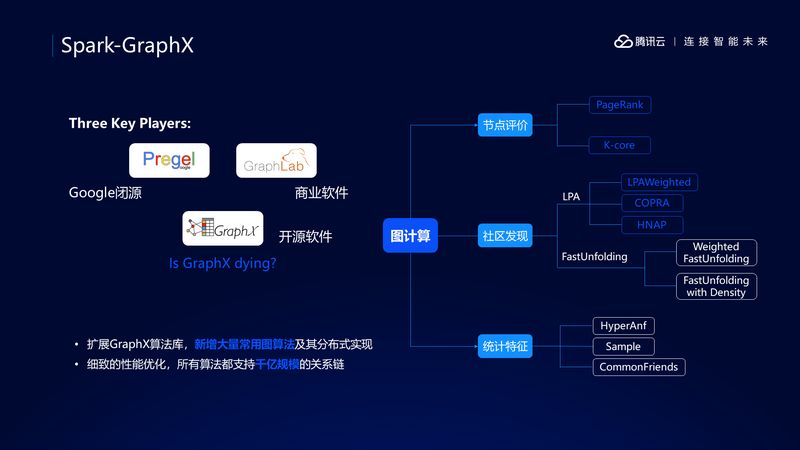
第二个特别之处是图计算算法,我们知道图计算领域有三个主要玩家,即 Pregel,GraphLab 和 GraphX,而 Pregel 是谷歌闭源,GraphLab 是商业软件,只有 GraphX 是开源软件。
但是 GraphX 更新慢,算法少,鉴于这种情况,我们就基于 GraphX 增加了很多图计算算法,有节点评价算法,社区发现算法,统计特征算法,经过细致的优化,这些算法都支持了千亿级规模的关系链。
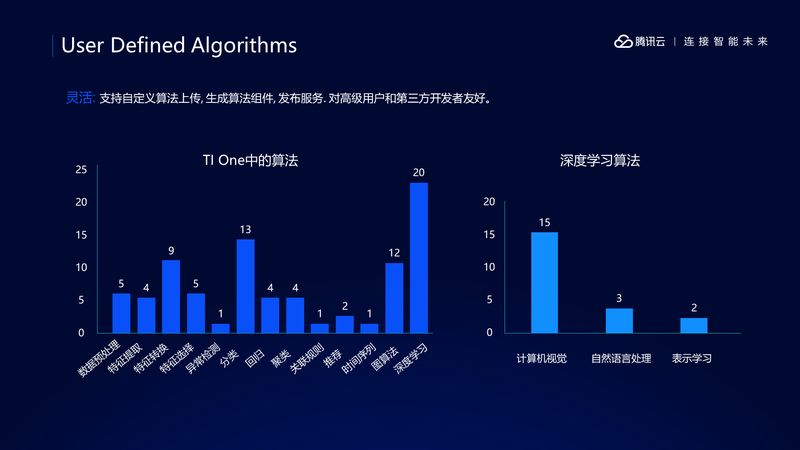
第三个特别之处是支持了用户自定义算法,前面提到我们集成了非常多的算法,有深度学习算法,也有传统学习机器算法,有回归算法,有分类算法,推荐算法等等,但是对于一些高级用户来说还是不够,所以我们允许用户自定义算法到 TI-ONE 执行,虽然是一个小功能,但是给用户带来很大的灵活性。
前面我们谈到了 TI-ONE 的功能和特别之处,现在要谈一谈商业用户比较关心的特性,严格来讲这个特性不是 TI-ONE 本身的,而是 GaiaStack 赋予的。

第一个是专用集群,当用户数据量较大时,我们可以提供多个完整集群让他使用,当用户的数据比较小的时候,可以多个用户共享集群,我们做了很好的多租户,用户的资源和数据隔离。
支持热升级,业务不中断,用户无感知。
支持主备自动切换的高可用,当服务量增大时,会自动加载新的实例,并自动负载均衡。
最后我们看看用户,我们公司内外都有很多的用户,在公司内比如腾讯游戏、微信、应用宝、QQ 音乐等等都是我们的用户。

如果你希望看到更多类似优质报道,记得点个赞再走!
┏(^0^)┛明天见!
以上是关于揭秘腾讯云上的机器学习平台TI-ONE的主要内容,如果未能解决你的问题,请参考以下文章
专访 | 腾讯云机器学习平台技术负责人黄明,详解 DI-X 深度学习平台