NLP干货!Python NLTK结合stanford NLP工具包进行文本处理
Posted 认知计算与智能服务实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP干货!Python NLTK结合stanford NLP工具包进行文本处理相关的知识,希望对你有一定的参考价值。
摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。而Stanford NLP 是由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。斯坦福大学的 NLP 小组是世界知名的研究小组,能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那对于自然语言开发者是再好不过的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。本分析显得非常方便好用。本文主要介绍NLTK(Natural language Toolkit)下配置安装Stanford NLP ,以及对Standford NLP核心模块进行演示,使读者简单易懂的学习本章知识。
目录
【Python NLP】干货!详述Python NLTK下如何使用stanford NLP工具包(1)
【Python NLP】Python 自然语言处理工具小结(2)
【Python NLP】Python NLTK 走进大秦帝国(3)
【Python NLP】Python NLTK获取文本语料和词汇资源(4)
【Python NLP】Python NLTK处理原始文本(5)
1 NLTK和StandfordNLP简介
NLTK:由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。
Stanford NLP:由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。斯坦福大学的 NLP 小组是世界知名的研究小组,能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那对于自然语言开发者是再好不过的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。本分析显得非常方便好用。
本文在主要介绍NLTK 中提供 Stanford NLP 中的以下几个功能:
中英文分词: StanfordTokenizer
中英文词性标注: StanfordPOSTagger
中英文命名实体识别: StanfordNERTagger
中英文句法分析: StanfordParser
中英文依存句法分析: StanfordDependencyParser, StanfordNeuralDependencyParser
2 安装配置过程中注意事项
本文以Python 3.5.2和java version "1.8.0_111"版本进行配置,具体安装需要注意以下几点:
Stanford NLP 工具包需要 Java 8 及之后的版本,如果出错请检查 Java 版本
本文的配置都是以 Stanford NLP 3.6.0 为例,如果使用的是其他版本,请注意替换相应的文件名
本文的配置过程以 NLTK 3.2 为例,如果使用 NLTK 3.1,需要注意该旧版本中 StanfordSegmenter 未实现,其余大致相同
下面的配置过程是具体细节可以参照:http://nlp.stanford.edu/software/
3 StandfordNLP必要工具包下载
必要包下载:只需要下载以下3个文件就够了,stanfordNLTK文件里面就是StanfordNLP工具包在NLTK中所依赖的jar包和相关文件
stanfordNLTK :自己将所有需要的包和相关文件已经打包在一起了,下面有具体讲解
Jar1.8 :如果你本机是Java 8以上版本,可以不用下载了
NLTK :这个工具包提供Standford NLP接口
以上文件下载后,Jar如果是1.8的版本可以不用下载,另外两个压缩包下载到本地,解压后拷贝文件夹到你的python安装主路径下,然后cmd进入NLTK下通过python setup.py install即可。后面操作讲路径简单修改即可。(如果不能正常分词等操作,查看python是否是3.2以上版本,java是否是8以后版本,jar环境变量是否配置正确)
StanfordNLTK目录结构如下:(从各个压缩文件已经提取好了,如果读者感兴趣,下面有各个功能的源码文件)
分词依赖:stanford-segmenter.jar、 slf4j-api.jar、data文件夹相关子文件
命名实体识别依赖:classifiers、stanford-ner.jar
词性标注依赖:models、stanford-postagger.jar
句法分析依赖:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers
依存语法分析依赖:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers
压缩包下载和源码分析:
分词压缩包:StanfordSegmenter和StanfordTokenizer:下载stanford-segmenter-2015-12-09.zip (version 3.6.0) 解压获取目录中的 stanford-segmenter-3.6.0.jar 拷贝为 stanford-segmenter.jar和 slf4j-api.jar
词性标注压缩包:下载stanford-postagger-full-2015-12-09.zip (version 3.6.0) 解压获取stanford-postagger.jar
命名实体识别压缩包:下载stanford-ner-2015-12-09.zip (version 3.6.0) ,将解压获取stanford-ner.jar和classifiers文件
句法分析、句法依存分析:下载stanford-parser-full-2015-12-09.zip (version 3.6.0) 解压获取stanford-parser.jar 和 stanford-parser-3.6.0-models.jar
4 StandfordNLP相关核心操作
4.1 分词
StanfordSegmenter 中文分词:下载52nlp改过的NLTK包nltk-develop ,解压后将其拷贝到你的python目录下,进去E:\Python\nltk-develop采用python 编辑器打开setup.py文件,F5运行,输入以下代码:
1 2 3 4 5 6 7 8 9 10 11 |
|
执行结果:
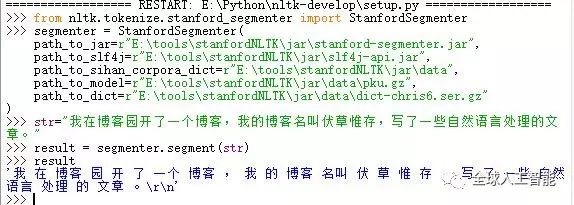
程序解读:StanfordSegmenter 的初始化参数说明:
path_to_jar: 用来定位jar包,本程序分词依赖stanford-segmenter.jar(注: 其他所有 Stanford NLP 接口都有 path_to_jar 这个参数。)
path_to_slf4j: 用来定位slf4j-api.jar作用于分词
path_to_sihan_corpora_dict: 设定为 stanford-segmenter-2015-12-09.zip 解压后目录中的 data 目录, data 目录下有两个可用模型 pkg.gz 和 ctb.gz 需要注意的是,使用 StanfordSegmenter 进行中文分词后,其返回结果并不是 list ,而是一个字符串,各个汉语词汇在其中被空格分隔开。
StanfordTokenizer 英文分词 :相关参考资料
1 2 3 4 5 6 7 8 |
|
执行结果:

4.2 命名实体识别
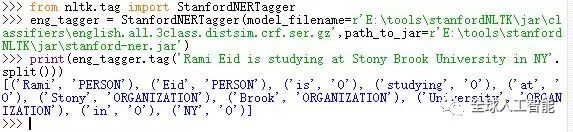
StanfordNERTagger 英文命名实体识别
1 2 3 4 |
|
运行结果:
StanfordNERTagger 中文命名实体识别
1 2 3 4 5 6 |
|
运行结果:

4.3 词性标注
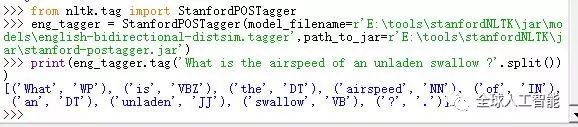
StanfordPOSTagger 英文词性标注
1 2 3 |
|
运行结果:
StanfordPOSTagger 中文词性标注
1 2 3 4 5 |
|
运行结果:


4.4 句法分析:参考文献资料
StanfordParser英文语法分析
1 2 3 |
|
运行结果:

StanfordParser 中文句法分析
1 2 3 4 |
|
运行结果:

4.5 依存句法分析
StanfordDependencyParser 英文依存句法分析
1 2 3 4 5 |
|
运行结果:
StanfordDependencyParser 中文依存句法分析
1 2 3 4 5 |
|
运行结果:
5 参考文献和知识扩展
NLTK官方网站
NLTK的API
NLTK中使用斯坦福中文分词器
GitHub上NLTK源码
以上是关于NLP干货!Python NLTK结合stanford NLP工具包进行文本处理的主要内容,如果未能解决你的问题,请参考以下文章