NLP机器学习在CRM前沿探索和实践
Posted AI学苑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP机器学习在CRM前沿探索和实践相关的知识,希望对你有一定的参考价值。
一、什么是NLP?
NLP是自然语言处理的英文简称。NLP的目标是让计算机能够学会人类语言的听说读写,以完成有意义的任务,比如订机票购物或QA等。完全理解和表达语言是极其困难的,完美的语言理解等效于实现人工智能。
二、NLP的主要任务
NLP的主要任务分为分词、词性标注、命名实体识别、句法分析、关系抽取、自然语言生成、文本分类、信息检索、信息抽取、问答系统、机器翻译、自动摘要等。
其中分词、词性标注、命名实体识别、句法分析属于基础任务,一般作为信息抽取、文本分类、关系抽取、聊天对话的前置任务。不过这几年由于深度学习的使用,可以端到端(end2end)的训练模型,可以省略分词、词性标注等传统的NLP任务。
三、NLP的技术发展及word2vec简介
NLP的技术发展经历了从规则到统计再到神经网络的发展历程。所谓规则就是人工总结语法规则,用正则表达式解析文本。统计的方法是从大规模语料中计算前一个词出现后,后一个词出现的概率,以此来评价句子的合理性。神经网络就是用深度学习算法来解决机器翻译、信息抽取、聊天对话等任务。
神经网络在NLP领域的开山之作就是word2vec.word2vec 是 Google 在 2013 年开源的一款将词表征为实数值向量的高效工具,采用的模型有 CBOW(Continuous Bag-Of-Words,即连续的词袋模型)和 Skip-Gram 两种。
word2vec通过训练,可以把对文本内容的处理简化为 K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。从而可以用向量运算的方式来解决很多NLP的相关工作。比如聚类、找同义词、词性分析等等。
词向量也是目前所有基于深度学习模型做NLP任务的输入数据,神经网络只接受向量化的数据,而词向量是目前文本数据最好的向量化形式。(词向量也被称为词嵌入word-embedding)
词向量的优劣很大程度上取决于训练的语料,所以垂直领域用垂直领域的语料进行训练得出的模型,将更适用于本领域的NLP任务。所以后续的应用都是建立在对本领域有良好适应性的词向量基础上。
词向量的另一个优点是它属于无监督学习,只要抓取足够多的语料就可以了,无须人工标注过程。
四、机器学习
机器学习作为一种从数据中发现规律的技术,能够较好的解决无法用逻辑规则描述的问题。比如怎样识别图片中的猫这样的问题。针对CRM的具体业务场景,例如:什么样的线索是高价值的?什么样的销售规划是符合公司下一步业务发展的?类似于这两个问题都是说不清楚,讲不明白。人类可以模糊说明和表达,但无法用计算机逻辑表达。所以这类问题是适合机器学习来解决的问题。
五、什么是CRM?
客户关系管理的定义是:企业为提高核心竞争力,利用相应的信息技术以及互联网技术协调企业与顾客间在销售、营销和服务上的交互,从而提升其管理方式,向客户提供创新式的个性化的客户交互和服务的过程。其最终目标是吸引新客户、保留老客户以及将已有客户转为忠实客户,增加市场。
六、落地场景一:线索评分和商机发现
线索评分是一个帮助销售人员判断一个潜在客户的价值、正确联系时间点预测的模型方法,此外线索评分也是下一阶段销量预测的一个重要特征。主要方法分为传统的人工评分和利用大数据机器学习评分两种。线索的人工评分主要依靠销售人员的经验。这里重点说一下用机器学习做线索评分的实施步骤。
(1)尽可能多的保留线索的各种信息,包括来源(微信推广、会议、官方网站白皮书、注册试用等等)、客户信息(企业规模、联系人职位、区域等)。
(2)当线索跟进过程中,在每一个时间节点上对线索进行重新评分。辅助销售人员判断线索的价值。
(3)销售人员可以手动建立目标客户的画像,也可以通过线索评分系统挖掘企业以往的客户数据来建立企业的客户画像,从而可以自动向企业推荐适合企业自身业务的高价值线索。
(4)在积累大量企业数据的基础上,可以做爬虫抓取社交媒体、新闻网站的数据,然后分析企业最近发生的各种商务事件(例如并购、产品发布会、高管入职等)从而发现新的商业机会。
七、落地场景二:企业图谱和采购决策关系图谱
企业图谱和采购决策图谱是一个基础数据。企业图谱有着广泛的用途,可快速补全企业的相关信息,同时也是线索评分的一个重要特征。从4000多万个企业中发现企业之间及企业主要管理者的关系涉及非常复杂的图算法(图9-1:燕京啤酒的企业图谱实例,基于neo4j实现)。
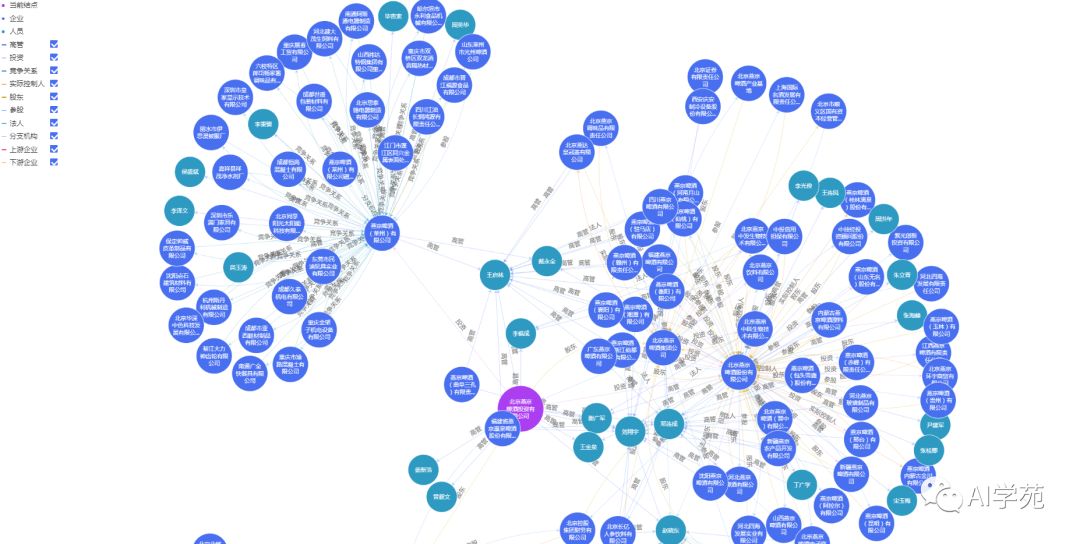
图9-1
八、落地场景三:营销规划的销量预测
营销规划怎么做?大部分销售类高管其实都是依据以往的经验拍脑袋定人员、收入和费用预算。销售目标定高了,达不到容易打击士气;定低了,又起不到激励的作用。其实如果有靠谱的销量预测,就能大致确定出收入,从而可以合理的分配人员和费用预算。重点是销量预测怎么做?如果是年销量的话,一般至少需要十年以上的数据积累,再结合各区域线索评分的数据来预测下一年的销量。预测下个月的销量相对容易些,差不多积累一年左右的数据就可以比较靠谱的预测下个月的销量。
预测模型肯定是在历史数据的验证下取得较准确的预测结果再部署上线预测客户真实的销量。比如在历史数据中验证的误差在2——5万元之间,我们有理由相信模型在真实环境下也能取得差不多的准确率。
九、深度学习、NLP技术栈及计算需求
深度学习技术栈主要是tensorflow/CNTK/PyTorch/Caffe2/MXNet等。其中目前应用最广泛的是tensorflow,根据公司的情况在实践中可灵活选择深度学习学习框架,一般从零开始构建AI体系的中小型企业建议使用tensorflow框架和python语言。推荐的开发工具是Visual Studio 2017(需要安装AI Tools扩展,见图9-2)。
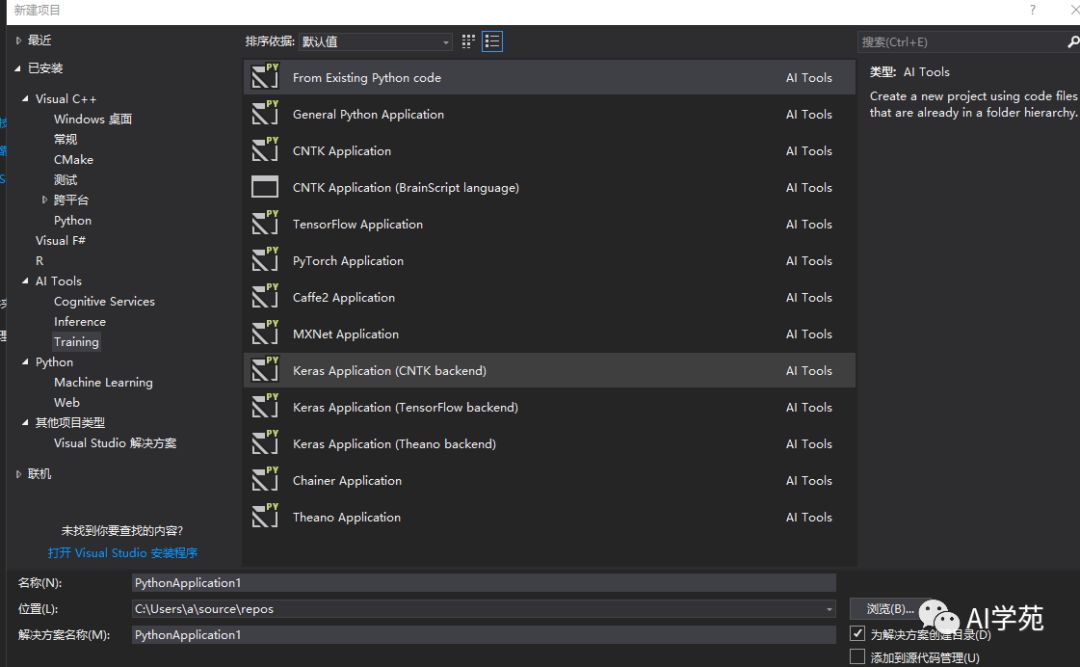
图9-2
机器学习的技术栈是pyhton的数据分析包numpy/pandas和算法包sklearn。分布式运算采用spark.
NLP主要使用word2vec,可结合tensorflow做信息抽取和语义分析的工作。可以分析网络中各企业发生的事件,当积累一定数据量后也可以分析用户输入的各种文本。
Neo4j是一种图数据库,非常适合存储企业图谱和采购决策关系图谱(Neo4j见图9-3)。Neo4j体验地址:http://39.106.182.185:7474/browser/,安装在个人的阿里云服务器上。
深度学习是一种需要大计算量的算法,故而需要较好的计算设备。目前业界主流是NVIDA GPU.
机器学习、NLP和知识图谱工具都安装在内部的GPU服务器上,并部署JupyterHub,向内部开发人员提供多用户的pyhon在线编程环境(示例界面见图9-4)。
以上是关于NLP机器学习在CRM前沿探索和实践的主要内容,如果未能解决你的问题,请参考以下文章