NLP2005年以来大突破语义角色标记深度模型,准确率提升10%
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP2005年以来大突破语义角色标记深度模型,准确率提升10%相关的知识,希望对你有一定的参考价值。
新智元编译
来源:washington.edu
编译:熊笑
【新智元导读】被称为取得了NLP “2005 年以来首个大突破”的研究报告 Deep Semantic Role Labeling: What Works and What’s Next,已被 ACL-17 接收。论文的第一作者是华盛顿大学的华人博士生何律恒。该研究为语义角色标注(SRL)引入了一个新的深度学习模型,显著提高了现有技术水平。
日前,“Stanford NLP Group” 发推特表示,华盛顿大学、FAIR 和艾伦研究所的合作研究 Deep Semantic Role Labeling: What Works and What’s Next ,是 NLP “2005 年以来首个大突破”。该论文已经被 ACL-17 接收。论文的第一作者是华盛顿大学的华人博士生何律恒。

新智元为您做了这篇论文的译介。
我们为语义角色标注(SRL)引入了一个新的深度学习模型,显著提高了现有技术水平,同时对其优缺点进行了详细的分析。我们使用了约束译码(constrained decoding)的深度 highway BiLSTM 架构,同时考察了近来初始化和正则化的最佳做法。我们的 8 层模型在 CoNLL 2005 测试集上达到 83.2 F1,在 CoNLL 2012 测试集上达到了 83.4 F1。与以前的技术水平相比,大约减少了 10% 的相对误差率。对研究结果的实证分析表明:(1)深度模型在恢复长距离语义依存关系方面表现出色,但仍然会犯明显错误;(2)语义分析仍然有改进空间。
语义角色标注(SRL)系统的目标是恢复一个句子的谓词-论元结构,来做出基本判断:“谁对谁做了什么”,“何时”和“哪里”。最近,没有句法输入的 SRL 的端到端深度模型(Zhou 和 Xu,2015; Marcheggiani 等,2017)取得的突破似乎推翻了长期以来的观点,即语义分析是这一任务的先决条件(Punyakanok等,2008)。在本文中,我们展示了这一结果可以通过具有约束译码的深度 highway 双向 LSTM 进一步推动,并再次显著提高了现有技术(在 CoNLL 2005 上有两个点的提升)。我们还对目前哪些技术取得了好的表现、还需要做什么以进一步提升表现进行了仔细的实证分析。
我们的模型结合了最近深度学习文献中的一些最优的做法。在Zhou和Xu (2015)之后,我们将 SRL 视为 BIO 标记问题,并使用深度双向 LSTM。然而,我们做出了以下调整:(1)简化输入和输出层;(2)引入 highway connections(Srivastava 等,2015; Zhang 等,2016);(3)使用循环dropout(Gal 和Ghahramani,2016);(4)用BIO 约束进行解码;(5)与专家产品合并。我们的模型比 2005 年和 2012年 CoNLL 测试集的技术水平相对误差减少了10%。我们还报告了 predicted predicates 的性能,以激发未来对端到端 SRL 系统的研究。
我们提供详细的误差分析,以更好地理解性能提升,包括(1)对架构、初始化和正则化的设计选择,对模型性能有非常大的影响; (2)不同类型的预测误差显示,该深度模型在预测长距离依赖方面表现优异,但仍然受困于已知挑战(如 PP- attachment errors 和adjunct-argument distinctions);(3)语法角色表明存在明显的 oracle syntax 改进空间,但现有自动解析器的误差阻止了 SRL 中的有效使用。
总结来说,我们的主要贡献包括:
•由开源代码和模型支持的端到端 SRL 的新型最先进深度网络。
•深入的误差分析,指出模型的工作原理及其挑战,包括结构一致性和长距离依赖关系的讨论。
•对未来改进方向有借鉴意义的实验,包括详细讨论如何和何时使用句法解析器来改进这些结果。
我们深度 SRL 模型的成功有两个原因:(1)应用训练深度循环神经网络中的最新进展,如 highway connections(Srivastava等,2015)和RNN dropout(Gal和Ghahramani,2016)(2)使用A *解码算法(Lewis 和Steedman,2014; Lee 等人,2016),以强化预测时间的结构一致性,而不增加训练过程的复杂性。
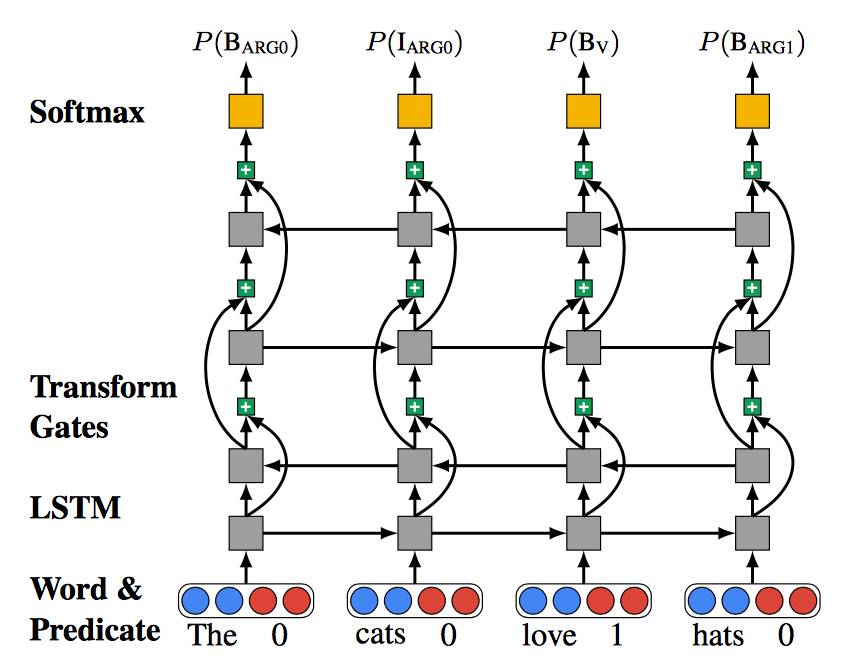
图1:四层Highway LSTM。曲线连接表示highway connections,+ 号表示控制层间信息流的变换门。
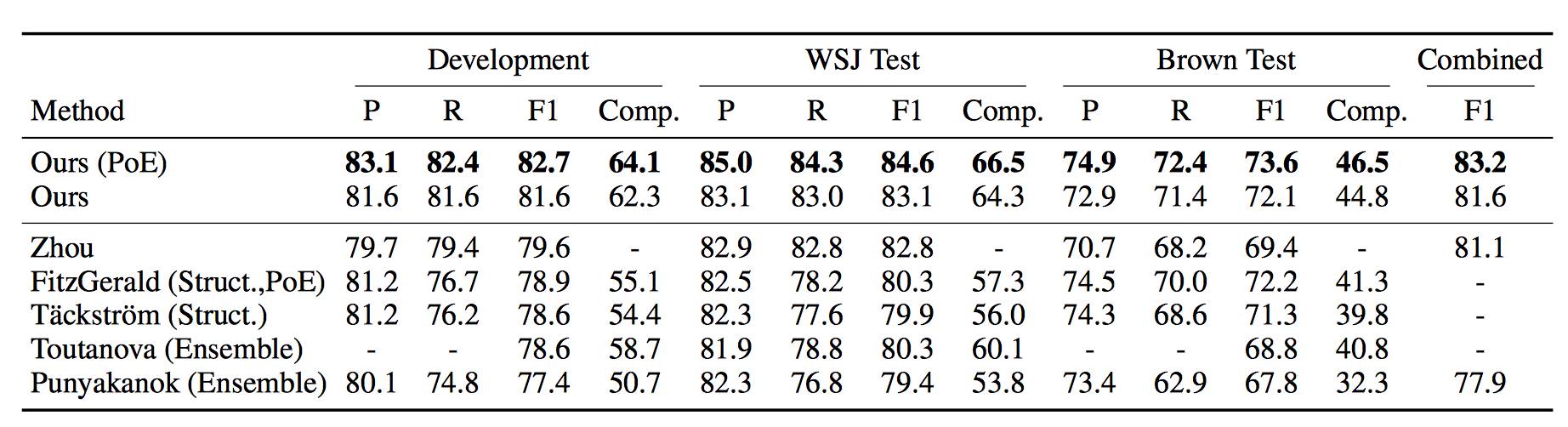
表1:CoNLL 2005 上的实验结果,涉及精度(P),召回率(R),F1和完全正确谓词百分比(Comp.)。我们报告了我们最好的 single 和 ensemble 模型(PoE)的结果。比较模型是Zhou 和Xu(2015),FitzGerald 等(2015),Täckström 等(2015),Toutanova 等(2008)和Punyakanok等(2008年)。
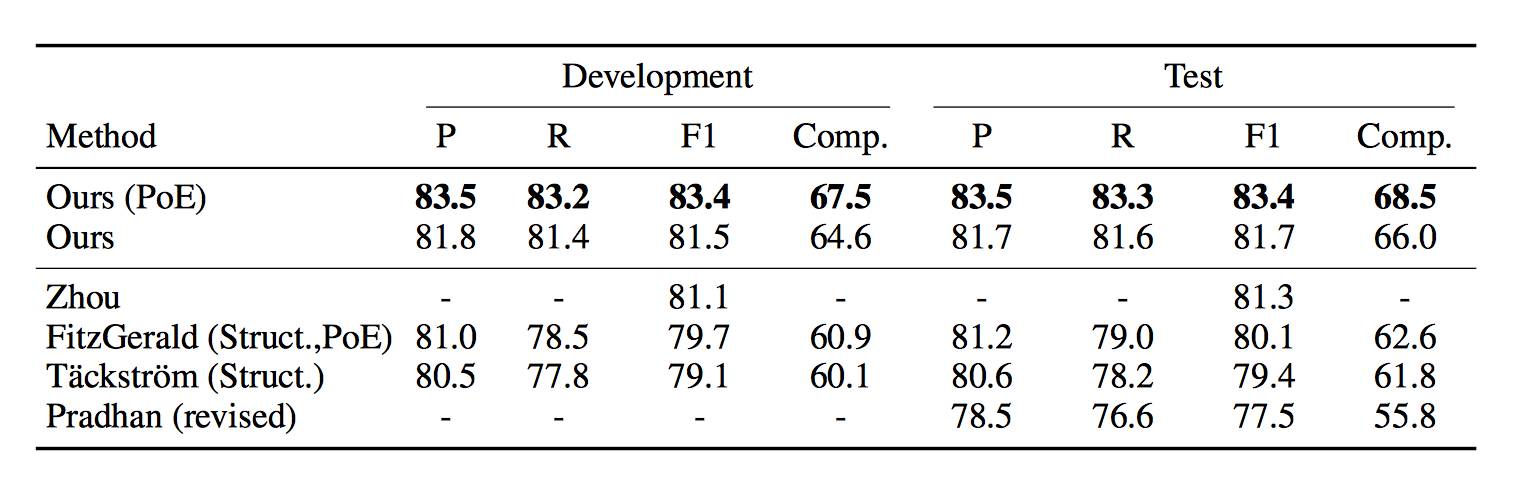
表2:CoNLL 2012 上的实验结果采用和表1 相同的度量方法。我们将我们最好的 single 和 ensemble (PoE)模型与Zhou and Xu (2015), FitzGerald 等(2015), Ta ̈ckstro ̈m 等(2015) 和Pradhan 等(2013) 进行比较.
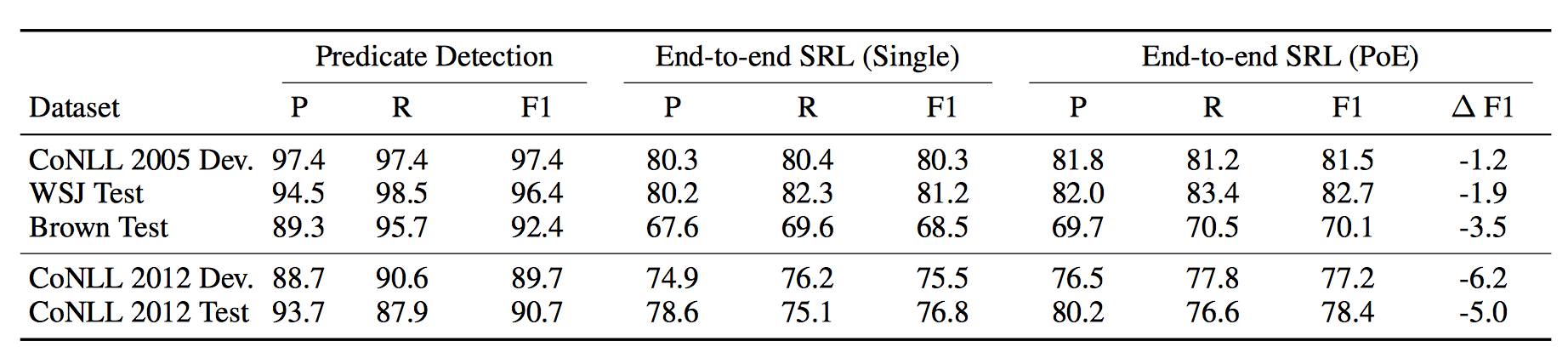
表3:使用 predictedpredicates 的谓词检测性能和端到端SRL 结果。与我们最好的 gold predicates ensemble 模型相比,ΔF1 显示出绝对的性能下降。
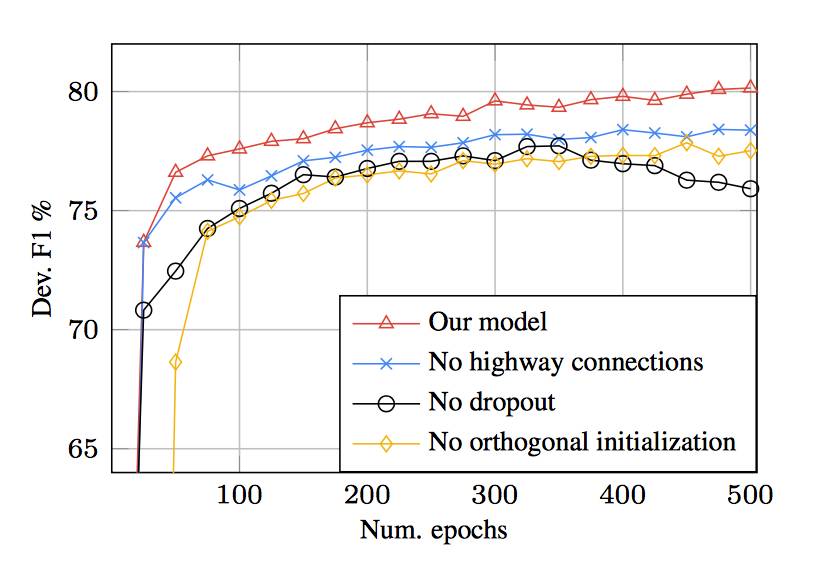
图2:various ablations 的平滑学习曲线。Highway 层组合,正交参数初始化和循环 dropout 对于实现强大的性能至关重要。这里显示的数字没有约束解码。
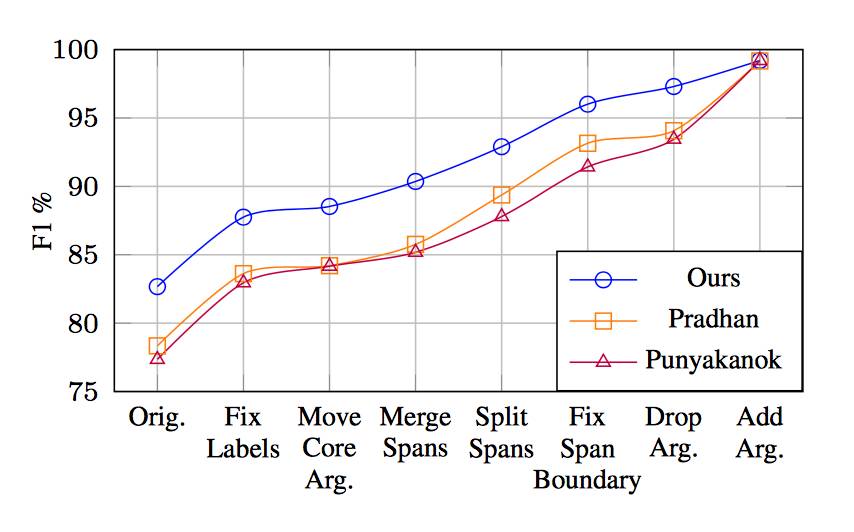
图3:与两个强 non-neural 基线相比,在进行序列中各种类型的oracle转换后的表现。Add Arg 转化之后,gap 被合拢,显示了我们的方法和传统系统相比,是如何从预测更多论元中获益的。
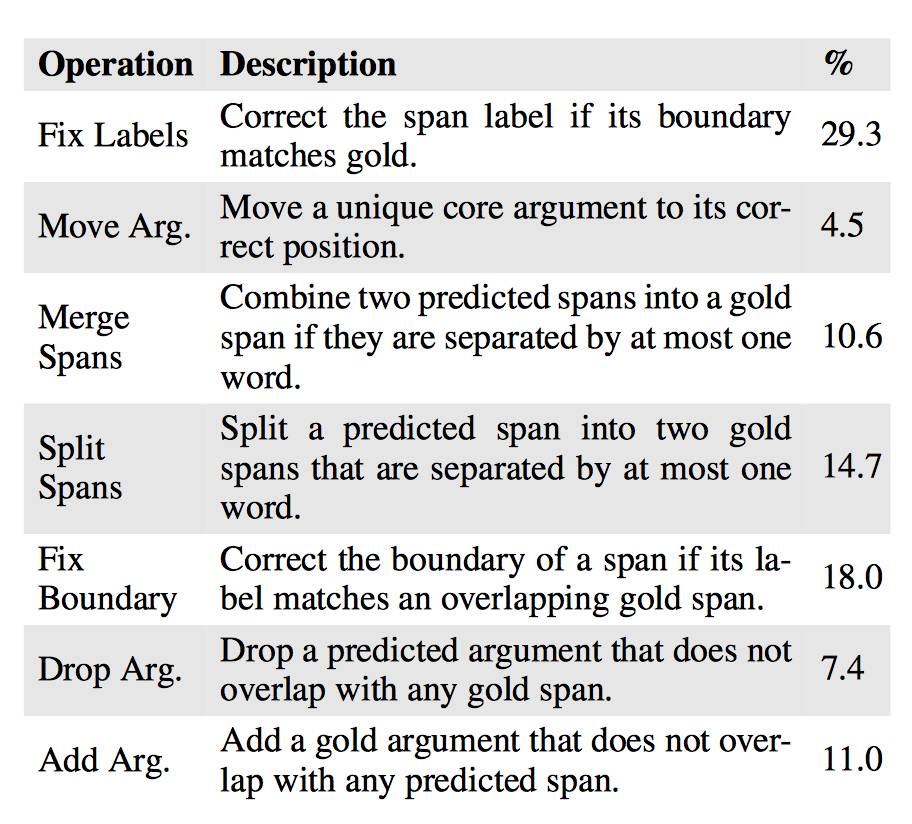
表4:Oracle 转换与每个操作后的相对误差减少配对。所有操作只有在不引起任何重叠参数的情况下才被允许。
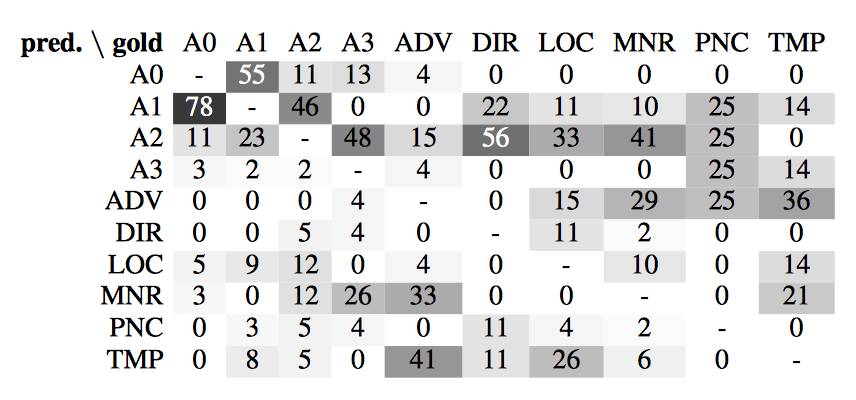
表5:标记误差的混淆矩阵,显示了“the percentage ofpredicted labels for each gold label”。我们仅计入了匹配 gold span boundaries 的预测论元。
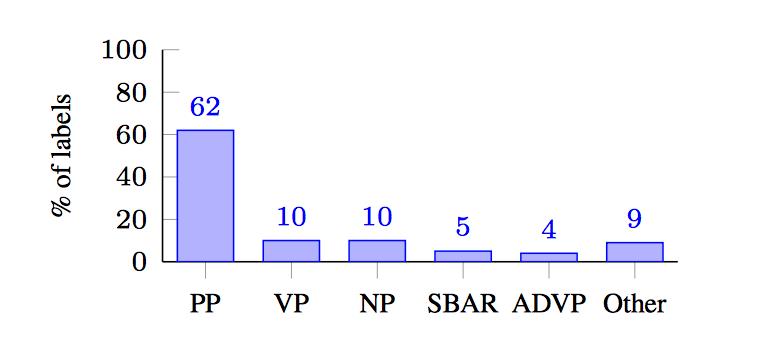
图4:对于我们的模型将gold span 一分为二(Z→XY)或合并两个 gold constituents(XY→Z)的情况,我们展示了Yspan 句法标签的分布。结果显示,这些误差的主要原因是不准确的介词短语attachment。
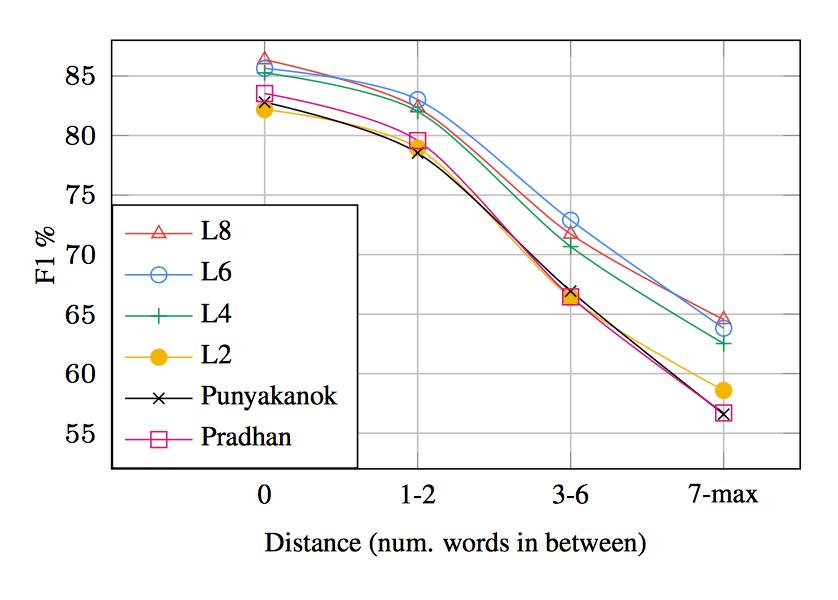
图5:谓词与论元之间的表面距离F1。对于较深层的神经模型,性能随论元距离增长而衰减的程度最小。

图6:强制执行核心角色只能发生一次(+SRL)的约束条件,性能受到损害的示例。
表6:2005年CoNLL上的F1,以及按类型细分的CoNLL 2012 上的 development set。语法约束解码(+ AutoSyn)显示了域内数据(CoNLL 05 和 CoNLL 2012 NW)的更大改进。
点击“阅读原文”查看新智元招聘信息
以上是关于NLP2005年以来大突破语义角色标记深度模型,准确率提升10%的主要内容,如果未能解决你的问题,请参考以下文章