机器学习NLP岗位面试准备提纲分享
Posted 机器学习与TensorFlow实战
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习NLP岗位面试准备提纲分享相关的知识,希望对你有一定的参考价值。
本文仅仅是机器学习岗位面试前的准备提纲,可供参考,后续有待补充,不详细谈各个问题的具体解法,仅限于提纲
一、机器学习算法
机器学习岗位面试自然会少不了问关于机器学习算法,包括基础机器学习算法的原理,公式推导,以及等各种做数据处理中可能遇到的问题
1、参数优化算法
最小二乘法:利用导数为0处取最优解通过求导优化参数
梯度下降法:沿着负梯度方向不断迭代寻找最优解优化参数
变种:随机梯度下降法、批量梯度下降法
牛顿法:求损失函数的Hessian矩阵
拟牛顿法:拟牛顿法比牛顿法更优,不需要计算Hessian矩阵,即不需要求二阶导
2、损失函数定义
最小二乘法:最小化均方误差,思想:保证所有数据的误差平方和最小
最大似然法:最大化似然函数,思想:寻找最大可能产生该样本的参数
从深度学习定义损失函数有:交叉熵损失函数、Softmax损失函数
3、朴素贝叶斯算法
朴素贝叶斯的条件独立性假设
朴素贝叶斯的公式推导,以及朴素贝叶斯的做判别的推断过程
Y代表了类别,X代表了特征,如Y={C1,C2,…,Ck} 共k个类别,X={X1,X2,…,Xn} 共n个特征
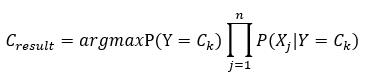
考虑特征X的分布,对应似然函数P( Xj | Y )三种情况
1、X是离散值
2、X是稀疏的离散值
3、X是连续值,如符合高斯分布
考虑某些特征样本值缺失问题,拉普拉斯平滑
4、线性回归
线性回归模型
线性回归损失函数定义:最小化均方误差
线性回归参数优化:最小二乘法、梯度下降法
多项式线性回归
L1正则化、L2正则化:防止过拟合、区别
5、Logistic回归
逻辑回归首先是解决分类问题,解决的是二分类问题
广义线性回归,推得逻辑回归的预测函数
逻辑回归预测函数 推导 损失函数(利用最大似然法)
优化函数使用:梯度下降法
6、决策树
ID3
信息熵:描述了样本的纯度
条件熵
信息增益
ID3算法的不足
(1) ID3算法没有考虑连续特征的处理
(2) ID3算法倾向于选择取值比较多的特征
(3) ID3算法对缺失值没有考虑
(4) ID3算法没有考虑过拟合的情况
但决策树算法最大的不足就是容易过拟合,需要进行剪枝处理
C4.5
和ID3的区别是尝试解决上面四个不足之处
将连续值离散化,离散化思路要清楚
信息增益比
明确信息增益比的计算方式:解决了ID3倾向于选择取值多的特征
CART
CART算法可以做分类,也可以用于回归,CART分类树、CART会归树
CART算法选择特征时使用的是基尼指数,而非是信息熵,这样降低了运算
CART对于连续值和离散值的处理也不同,连续值离散化的方式和C4.5策略是相同的,只是特征选择使用的是基尼指数,CART算法只生成二叉树,因此对于离散值的处理也不同,当有多个取值时,仍旧分成两类进行划分,也因此后续可能会继续使用此离散值
7、集成学习算法
异质个体学习器
同质个体学习器(常用)
个体学习器间存在强依赖关系:Boosting、Adaboost、boosting tree(Gradient boosting
tree)
Boosting算法:根据弱学习的学习误差率表现来更新训练样本的权重,提高学习误差率高的训练样本,使得这些训练样本在后续的训练过程中被重视
Adaboost算法:四个问题
(1) 如何计算学习误差率e
(2) 如何得到弱学习器权重系数a
(3) 如何更新样本权重D
(4) 如何使用结合策略
弱分类器之间是强关联的,第一个弱分类器运算之后才进行第二个弱分类器训练,弱分类器有权重系数,每个样本在每次弱分类器训练时也有权重系数,最后对于所有弱分类器使用的结合策略是加权投票法
个体学习器间没有关系:bagging、随机森林
可以从偏差和方差的角度去分析Boosting算法和Bagging算法的区别,而且可以看出随机森林使用模型的树的层数较深,GBDT模型树的层数相对浅,也都和boosting和bagging本身的特性有关,Boosting是通过减小模型的偏差提升性能,Bagging是通过减小模型的方差提升性能
GBDT 梯度提升决策树
Boosting的一种实现
可做回归问题和分类问题,也决定了损失函数的选择
分类:对数损失、指数损失
回归:均方误差、一般损失函数(绝对值误差、Huber损失、分位数损失)
GBDT在做回归问题时:
(1) 如何根据连续特征划分节点:方式是找使得分成两个节点后均方误差最小的值
(2)如何更新下一棵树,例如Adaboost是通过修改原始样本的权重,然后再利用加了权重的原始样本生成新的弱分类器(CART树)、但GBDT是利用上一棵树分成两个节点后,利用数据残差构造下一棵弱分类器CART树,然后这层树便是节点数据的均值
但上述描述中说的是使用均方误差作为损失函数判断划分节点特征
如果使用一般的损失函数,需要使用损失函数的负梯度拟合下一棵CART树,然后这层树的模型是求得该节点数据中使得损失函数最小的作为该节点的拟合输出值
GBDT算法是一个加法训练,每一层都是在做优化,一层优化结束后再进入下一层,每一棵树学习的是之前所有树结论和的残差,最后GBDT算法的结果是加权累加得到的所有弱分类器的结果
Xgboost算法
上面是Xgboost的损失函数,上个公式中T是叶子的个数,w自然是叶节点的权重
随机森林Random Forest
随机森林算法是基于boosting修改的算法,弱分类器多使用CART决策树
随机森林算法在boosting样本扰动的基础上,又添加了属性扰动,即随机森林算法的弱学习器在每次划分节点的时候不是从全部的属性中选择最优的,而是从全部n个属性中随机选择k个属性,然后选择k个属性中最优的作为划分节点的特征
优点:可以在多个弱分类器间并行计算,效率高
缺点:样本噪声过大时,使用随机森林很容易过拟合
8、SVM算法
线性分类器,而且一般只适用于处理二分类问题
优化函数:最大化函数间隔,明白如何得到函数间隔,明确约束条件
将优化函数转化成凸优化问题
利用拉格朗日乘子法,合并优化函数和约束条件
利用对偶概念转变优化函数
优化函数外层是对参数a求max,里层是对w、b求最小
通过求导为0得出w、b的表示,将优化函数转化为对参数a求max
最后使用SMO算法求参数a,最后得出模型
9、集成学习算法
Kmeans算法、均值漂移聚类、基于密度的聚类、凝聚层次聚类、用高斯混合模型的最大期望聚类等
10、下面列出机器学习面试中可能会出的问题
(1) 过拟合欠拟合(举几个例子让判断下,顺便问问交叉验证的目的、超参数搜索方法、EarlyStopping)
(2) L1正则和L2正则的做法
(3) 正则化背后的思想(顺便问问BatchNorm、Covariance Shift)
(4) L1正则产生稀疏解原理、逻辑回归为何线性模型(顺便问问LR如何解决低维不可分、从图模型角度看LR和朴素贝叶斯和无监督)
(5) 几种参数估计方法MLE/MAP/贝叶斯的联系和区别
(6) 简单说下SVM的支持向量(顺便问问KKT条件、为何对偶、核的通俗理解)
(7) GBDT随机森林能否并行(顺便问问bagging boosting)
(8) 生成模型判别模型举个例子、聚类方法的掌握(顺便问问Kmeans的EM推导思路、谱聚类和Graph-cut的理解)
(9) 梯度下降类方法和牛顿类方法的区别(顺便问问Adam、L-BFGS的思路)
(10) 半监督的思想(顺便问问一些特定半监督算法是如何利用无标签数据的、从MAP角度看半监督)
(11) 常见的分类模型的评价指标(顺便问问交叉熵、ROC如何绘制、AUC的物理含义、类别不均衡样本)
(12) CNN中卷积操作和卷积核作用
(13) maxpooling作用
(14) 卷积层与全连接层的联系
(15) 梯度爆炸和消失的概念(顺便问问神经网络权值初始化的方法、为何能减缓梯度爆炸消失、CNN中有哪些解决办法、LSTM如何解决的、如何梯度裁剪、dropout如何用在RNN系列网络中、dropout防止过拟合)
(16) 为何卷积可以用在图像/语音/语句上(顺便问问channel在不同类型数据源中的含义)
11、NLP和推荐系统相关理论知识
(1) CRF跟逻辑回归 最大熵模型的关系
(2) CRF的优化方法
(3) CRF和MRF的联系
(4) HMM和CRF的关系(顺便问问 朴素贝叶斯和HMM的联系、LSTM+CRF 用于序列标注的原理、CRF的点函数和边函数、CRF的经验分布)
(5) WordEmbedding的几种常用方法和原理(顺便问问language model、perplexity评价指标、word2vec跟Glove的异同)
(6) topic model说一说
(7) 为何CNN能用在文本分类
(8) syntactic和semantic问题举例
(9) 常见Sentence embedding方法
(10) 注意力机制(顺便问问注意力机制的几种不同情形、为何引入、seq2seq原理)
(11) 序列标注的评价指标
(12) 语义消歧的做法
(13) 常见的跟word有关的特征
(14) factorization machine
(15) 常见矩阵分解模型
(16) 如何把分类模型用于商品推荐(包括数据集划分、模型验证等)
(17) 序列学习、wide&deep model(顺便问问为何wide和deep)
二、数据结构算法
面试中算法题是少不了的,这体现一个程序员的基本功,因此平时要多多在Leetcode、牛客网上刷题,所以在面试前倒也没办法突击准备,注重平时多积累,说道最简单且容易忽视的算法也就是排序算法,因此面试前也是可以临时抱佛脚准备一下排序算法:
简单排序算法:冒泡排序、选择排序、插入排序
1、冒泡排序:简单排序算法之一,思想是通过与相邻元素的比较和交换把小的数交换到最前面
2、选择排序:思想是通过一次遍历循环将最小的元素移动到序列的最前面
3、插入排序:思想是不是通过交换位置而是通过比较找到最合适的位置插入元素来达到排序的目的,上述三个简单排序算法的时间复杂度都是O(n^2)
4、归并排序、快速排序:之所以将归并排序和快速排序放在一起是因为面试中真的容易直接让手撸算法思路,因此应对面试需要知道算法思想,并能复现代码逻辑,归并排序和快速排序平均时间复杂度都是O(nlogn),快速排序效率最高,但在最坏情况下快排的效率不如归并排序,归并排序空间复杂度是O(n),快速排序空间复杂度是O(logn)
5、堆排序:通过最小堆实现数组的从小到大排序,时间复杂度为O(nlogn)
6、计数排序:对整数进行排序,排序的时间复杂度和空间复杂度是O(n+k),思想:用待排序的数作为计数数组的下标,统计每个数字的个数,然后依次输出得到有序序列
7、桶排序:关键在于映射函数,将原始数据映射到n个桶上,桶中的元素仍采用比较排序,桶中元素可以采用快速排序,但映射到桶的操作大大减低了排序时间
8、基数排序:利用了桶排序思想,只不过基数排序每次都只是处理数字的一位,从低位到高位顺序进行,对每一位依次进行桶映射排序的思想
9、希尔排序:分组插入排序,又称为缩小增量排序,思想:先将整个待排序元素序列分割成若干个子序列(由相隔固定增量的匀速组成),对每个子序列直接插入排序,然后一次缩减增量再进行排序,到增量最小时,再对全体元素进行一次增量排序。利用了插入排序在元素基本有序的情况下排序效率很高
上述列举了十大排序算法,其中计数排序和其他九种算法的区别在于其他九种算法都是基于比较排序的,基于比较排序的算法的时间复杂度下限是O(nlogn)
当然算法题无穷无尽,体型多变,但大致也就那么几种,多刷题,多总结
三、海量数据处理面试题
在机器学习岗和数据岗面试中经常会问到海量数据的面试题,这里给出一些大致思路
时间问题:Bloom filter、Hash、bit-map、堆、数据库、倒排索引、trie树
空间问题:大而化小,分而治之(Hash映射)
Hash算法
Hash:拉链法存储
Hash函数的选择(确定映射方式)
Hash在海量数据中的应用、堆在topK问题中的应用
海量数据处理方式一:分而治之/Hash映射 + Hashmap统计 + 堆/快速/归并排序
海量日志数据,提取访问次数最高的topK个IP
步骤1、分治思想,先通过hash映射将日志文件映射到1000文件中,hash(x)%1000
步骤2、hashmap统计:使用key-value形式统计每个IP出现的次数,在每个文件中统计
步骤3、比如取top100,我们可以在每个文件使用堆排序,取出每个文件中最高,合并每个文件最高的,再用堆结构取出这1000个中的top100
海量数据处理方式二:外排序,多路归并、bit-map
给定一个文件,里面最多包含n个不重复的正整数,且其中每个数都小于等于n,n=10^7
1、Bit-map位图法
步骤:用一个1000万个位的字符串表示
2、外排序、多路归并排序
步骤:先分治内存排序生成40个有序的文件,多路归并排序四十个文件
上述之处抛出了一些问题,有些问题值得好好思考,也欢迎大家补充!
本文完结,创作不易,欢迎转载,转载请注明出处【机器学习与TensorFlow实战】 作者【CHEONG】,谢谢!博文每周一更新,欢迎大家交流!
以上是关于机器学习NLP岗位面试准备提纲分享的主要内容,如果未能解决你的问题,请参考以下文章