CV+NLP更有智慧的眼睛:图像描述(Image Caption)&视觉问答(VQA)综述(上)
Posted 机器学习研究组订阅号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CV+NLP更有智慧的眼睛:图像描述(Image Caption)&视觉问答(VQA)综述(上)相关的知识,希望对你有一定的参考价值。
前言
2016 年 6 月 29 日,拉斯维加斯 CVPR2016 的会场,最佳论文奖颁给了 Kaiming He 的 Deep Residual Learning for Image Recognition,也就是我们所熟知的 ResNet。在那以后的几年,计算机视觉的三大基本任务:分类,检测,分割被以 ResNet 为骨干网络的各种 Net 迅速蚕食。计算机视觉的研究者们,也更加地由感知智能偏向到认知智能,他们终于要严肃面对在自然语言处理中的面对的种种问题,去探索人工智能更神秘的边界。在这之中,较为主流的问题有两个,一个是图像描述(Image Caption),另一个叫视觉问答(Visual question answering,VQA)。本文将对近两年来两大方向的发展做一个迅速的回顾,以期帮助我们能够更好的展望未来。
目录
1、教会机器触景生情:浪漫的 Image Caption
(1)简单概述:任务描述,评价标准,常用数据集
(2)故事还要从 Encoder-Decoder 结构说起
(3)结语
2、教会机器对答如流: 机智的 VQA(待写)
(1)简单概述:任务描述,评价标准,常用数据集
(2)两个世界下的对话
(3)结语
教会机器触景生情:浪漫的 Image Caption

简要概述
Image Caption,一般有几种叫法:图像描述,图像标注,看图说话。它的任务,就是给机器一张图像,而后需要机器去感知图像中的物体,甚至去捕捉画面中的关系,最后生成一段描述性质的语言。既然是描述性质的,那么一个难点就在于如何去评判生成语句的好坏。在这里,我们主要有指标去评价:
BLEU:全称为 Bilingual Evaluation Understudy,双语互评辅助工具。我们把生成的 candidate caption 和参考语句 reference caption 看成 n-gram,也就是一个将句子顺序划分的 n 个词组成的组,而后对这些组计算精度,并且在长度上施加适量的惩罚,来得到 BLEU 的分数。一般论文中会报告 n = 1, 2, 3, 4 的结果。详细可以戳这里理解:Image Caption 评价标准--BLEU(https://livc.io/blog/190)
METEOR:研究表明,基于召回率的标准比单纯基于精度的 BLEU 更像人工判断的结果。METEOR 基于 1-gram 的精度和召回的调和平均,详细可以戳这里理解: 看图说话的AI小朋友——图像标注趣谈(上) (METEOR 部分,https://zhuanlan.zhihu.com/p/22408033)
ROUGE:全称为 Recall-Oriented Understudy for Gisting Evaluation,这是用于评估文本摘要算法的标准集合。在 Image Caption 任务中,常用 ROUGE-L 指标,L 代表最长公共子序列(LCS),这是同时出现在 reference caption 和 candidate caption 中且顺序相同的一段小语句。由于 reference caption 一般有多条,那么 ROUGE-L 会基于 LCS 召回率和精确率来计算 F1 score。详细可以戳这里理解:Image Caption 评价标准--ROUGE (https://livc.io/blog/191)
CIDEr-D: 要知道 CIDEr-D,就得先了解 CIDEr。这是在 CVPR2015 上提出的一种,专门面向于图像描述问题的指标。改进之处在于,它会根据在所有参考标注中更多出现的无关于视觉信息的词赋予更低的权重。而 CIDEr-D 做的修改之处主要在于,减少了句子长度和单词频率带来的影响。当在较长句子上重复较高置信度的单词时,基本 CIDEr 指标会很高,CIDEr-D 通过基于候选和参考句子长度之间差异的高斯惩罚与计数上的限制来使得评判标准更加像人类。详细可以戳这里理解:Consensus-based Image Description Evaluation(https://arxiv.org/abs/1411.5726)
SPICE:SPICE 这个指标是在 ECCV2016 上提出的,它基于句子对应的 semantic scene graphs 来评价 F-score,还是很科学的。
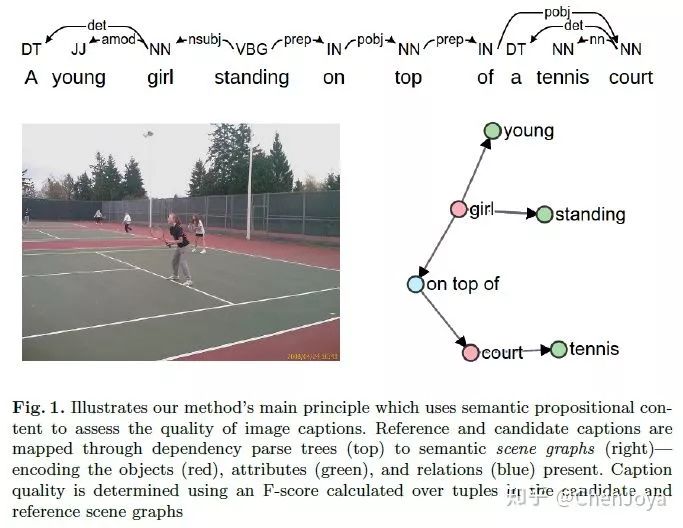
详细可以戳这里理解:Semantic Propositional Image Caption Evaluation(https://arxiv.org/abs/1607.08822)
这些指标是相关研究中基本都会报告的指标。那么,我们再来看评测这些指标的常用数据集:
MS COCO:微软的 COCO 数据集中,有超过 160,000 的图像,人工为每张图像都至少撰写了 5 条标注,总共有超过 100 万句的描述。Microsoft COCO Image Captioning Challenge(https://competitions.codalab.org/competitions/3221#learn_the_details)
Flickr8k & Flickr30k:图像数据来源于雅虎的相册网站 Flickr,图像数量分别是 8000 和 31783,每张图像的人工标注为 5 句描述。 Flickr30k (http://shannon.cs.illinois.edu/DenotationGraph/data/index.html)
做图像描述的意义在哪里呢?如果在图像描述问题上能够看到曙光,那么势必可以为一些在视觉上有天生障碍的人提供更好的辅助,让计算机成为他们的另一双眼睛。
故事还要从 encoder-decoder 结构说起
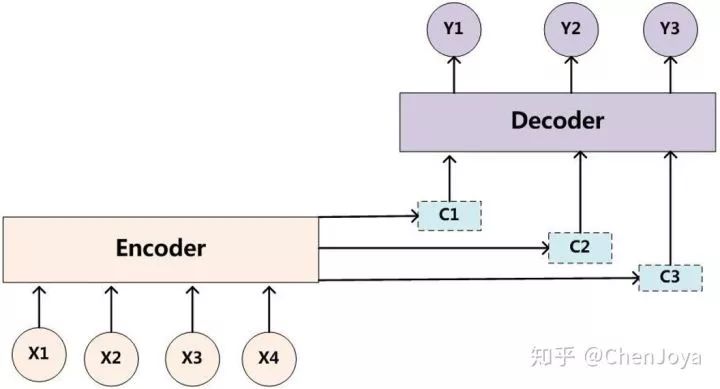
故事还要从 encoder-decoder 结构说起。这是一个广泛应用于机器翻译,写诗,作曲,看图等的结构,在 2014 年左右被提出,它将输入序列转化成一个固定长度的向量;再将这个固定向量再转化成不定长的输出序列。这是一类强大的思想,基于 encoder-decoder,我们可以设计出各种各样的应用算法。在 CVPR'15 上,有了 《Show and Tell: A Neural Image Caption Generator》 这样一篇文章,它使用 CNN 为图像提取一个固定长度的视觉特征,而后接上 Decoder 将这个特征解码为输出序列。
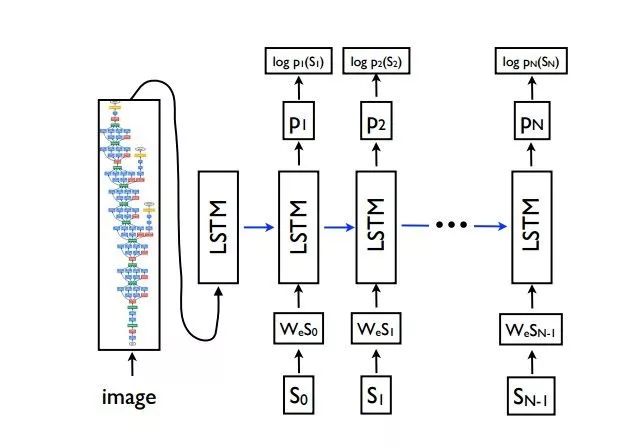
那么借鉴 attention 机制,在 ICML'15 上,有了 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》 这样一篇文章,为卷积层的 feature map 的每一个位置都加上一个权重,这个权重就代表注意力因子,可以通过反向传播来学习。具体来说,假设经过 backbone 后,得到 14*14*256 的 feature map,那么我们将其看成 14*14 = 196 个位置,每个位置有 256 维的向量。我们对于每一个位置添加一个权重因子,传入 Decoder RNN 的上下文向量就是这些向量的加权平均。有了 attention 机制,模型可以自由选择在生成某个词的时候去更加关注什么位置,如:

What Value Do Explicit High Level Concepts Have in Vision to Language Problems ? (CVPR'16,阿德莱德大学)
这篇文章有意义的地方在于,它回答了高层次语义信息(high-level concepts)对于 Image Caption,VQA 这些 Vision-to-Language 的问题到底有什么样的意义。在 Show and Tell 中,仅仅是采用了 CNN 高层的卷积特征来作为视觉特征,在此之后的信息是全部被丢弃的。作者发出了这样的疑问:should we give up on high-level concepts in V2L altogether?来看下面的图片,作者采用 single-label 的模型微调出一个 multi-label 的模型,而这样的标签其实就隐藏在对于图片的描述之中,图像中又有人,又有桌子,也有酒,我们采用多个二分类器(element-wise logistic loss function)来处理这样的问题,而后将这样的属性特征(attributes vector)送入语言模型中,不同的任务有不同的语言模型。
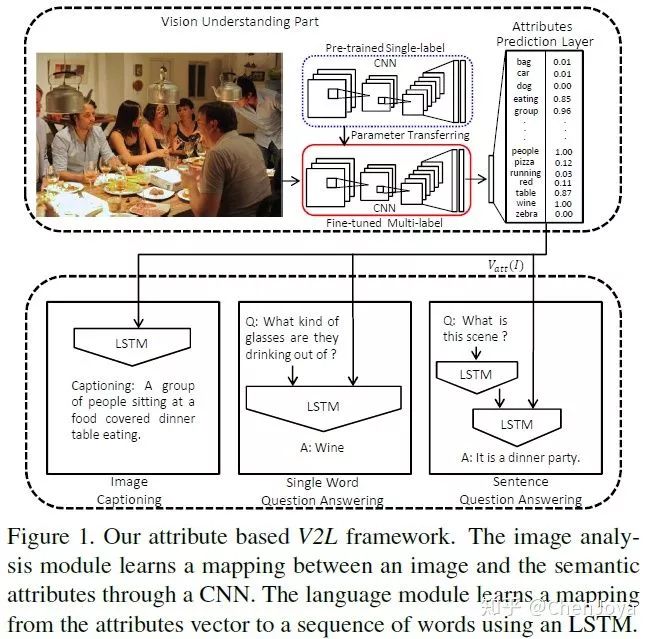
如何来选择这些 attributes 呢?从给出的所有描述中获得即可。在预测 attributes 时采用 BING 算法(一种提取目标框的算法,出自CVPR2013)来提取区域,通过 CNN 后再整合这些特征。为什么要采用基于区域的方法呢?猜测是可以帮助预测表示数量的词语。
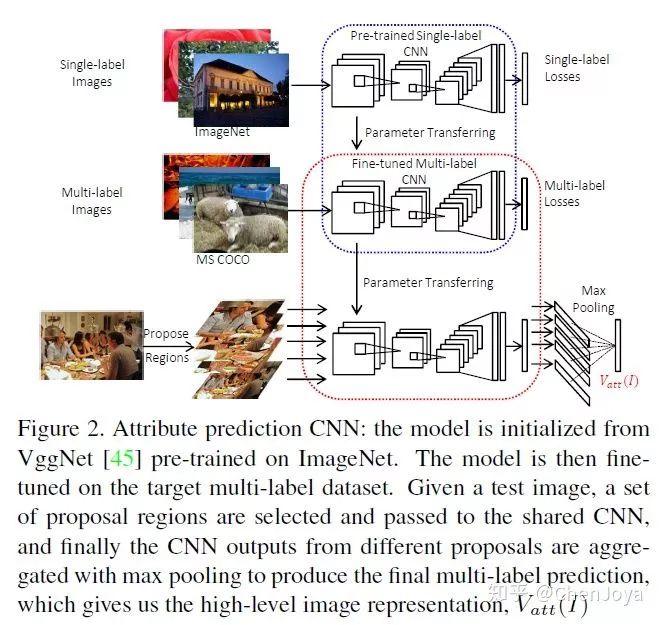
在实验部分有表明,使用 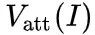 代替
代替 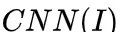 可以大幅提高模型效果。
可以大幅提高模型效果。
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning(CVPR'17,浙江大学 & 哥伦比亚大学 & 山东大学 & 腾讯 AI Lab & 新加坡国立大学)
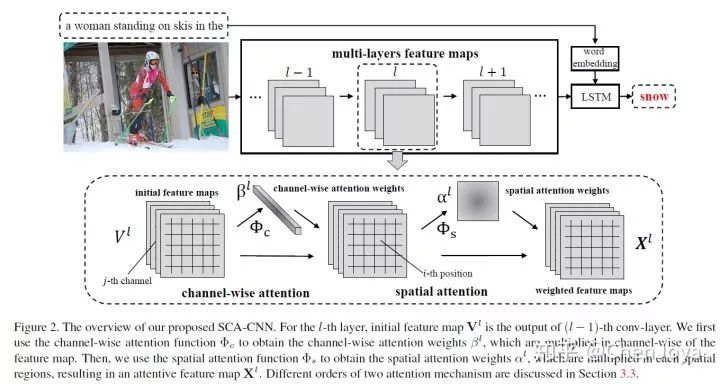
文章属于对于 attention 机制的改进。Show, Attend and Tell 将 attention 机制引入了 Image Caption,其采用的是空间位置上的 attention (spatial attention),而且只使用了网络的最后一个卷积层。SCA-CNN 的作者认为这样并不符合 spatial, channel-wise, and multi-layer 形式的 CNN 特征。基于此,作者引入了 multi-layer 和在通道上做 attention 的思想(channel wise attention)来充分地利用 CNN 特征的特性。
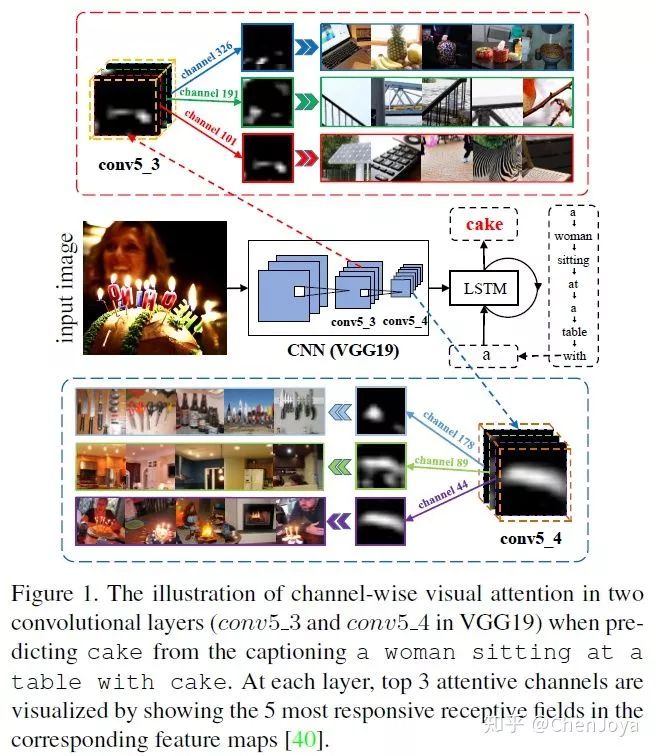
上图所示,通道上的一个 feature map 其实可以看作是对于对应 filter 的响应,所以 channel-wise attention 可以看作是选择符合句子语境的语义特征的过程。如想要去预测蛋糕这个词,我们将会给那些有蛋糕啊,灯光啊,蜡烛的语义的 feature maps 赋予给大的权重。而不仅仅采用高层特征的 multi-layer 的形式则可以更加利用低层特征上的保留的形状信息(还是预测蛋糕的时候,需要更加关注阵列、圆柱体的形状)。
我们重点关注三个事情:如何选择 layer, 如何实现 channel-wise attention 以及如何将 channel-wise attention 和 spatial attention 配套使用。作者采用了分离学习 spatial attention weights 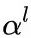 和 channel-wise attention weights
和 channel-wise attention weights 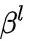 的方式来节省 memory:
的方式来节省 memory:
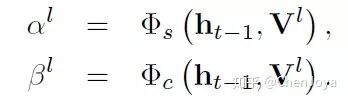
如下图,整个算法的流程就是,在生成某一个词时,拿到某一层的特征图,先得到 channel-wise attention 的权重,与原特征图相乘,再经过空间位置注意模型得到最终的特征 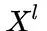 。而对于层的选择的话,文中并没有详细描述,猜测是将选定的层都拿来用的。之后就是 LSTM 生成下一个词的常规操作了。
。而对于层的选择的话,文中并没有详细描述,猜测是将选定的层都拿来用的。之后就是 LSTM 生成下一个词的常规操作了。
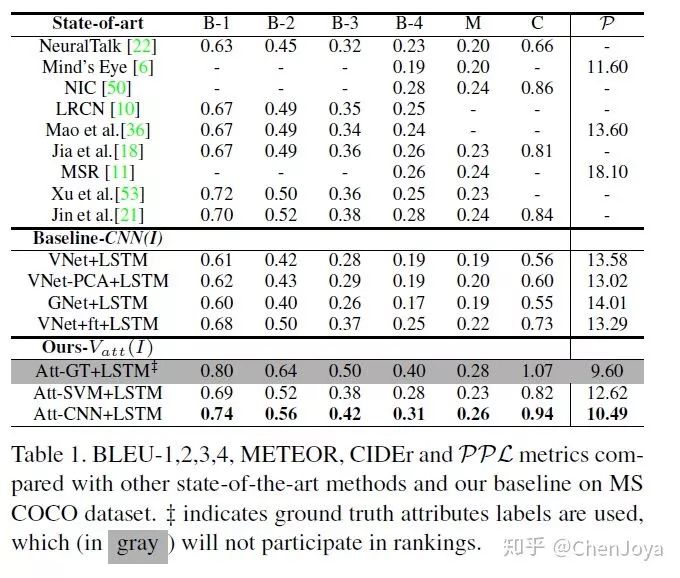
在实验部分中,文章得出了以下结果:(1)channel wise attention 能够显著提升效果;(2)先做 channel wise attention 再进行spatial attention 比反过来效果要稍微好一些;(3)multi-layer 的效果确实比单层的效果要好一些,但是过多会引起下降;
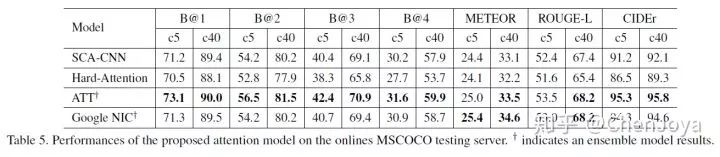
下表展示了 SCA-CNN 在 MS COCO Image Challenge set c5 and c40 上的表现。相比于 spatial attention model(Hard-Attention),提升的效果十分明显,但是其不如 ATT 和Google NIC,主要原因在于后二者都采用了模型融合的方式。
Self-critical Sequence Training for Image Captioning(CVPR'17,IBM)
这篇文章的结果相当在当时候是相当牛逼的,据说曾在 COCO 上霸榜五个月之久。它做了一件什么事情呢?采用 Reinforcement Learning 来做 Image Caption。大家也许还记得去年有个新闻叫“腾讯获计算机视觉权威赛事冠军,领衔图像描述生成技术”,而它用的方法除了基于上面的 SCA-CNN 外,还使用了强化学习来训练 decoder。那么为什么要使用强化学习?我们的评价指标如 BLEU,METEOR,ROUGE,CIDER 都是不可微的,这就无法做到训练和测试同步。此外,还存在 exposure bias 的问题,生成词的时候误差会累积把后面的词带偏,因为训练的时候模型从来就没有看过它自己的预测结果。

于是人们想到了强化学习,输入是图片和已经生成的单词(state),action 是下一个单词,而 reward 就是这些评价指标,通过 policy gradient 来进行优化。但是像 REINFORCE 这种 policy gradient 方法会有 high variance 的问题,我们会通过加入一个 baseline 来修正,表现在 baseline 之下要进行抑制,在 baseline 之上就进行拉高。这个 baseline 有可能是另外一个网络,还挺复杂的。如果是像 actor-critic 这种策略,就需要有一个 critic 网络去给 action 打分,这样虽然可以避免巨量的 sampling 去得到 rewards,但是还是得有这么一个评委去估计 reward。而这篇论文提出的 SCST 算法,Self-critical Sequence Training,属于 REINFORCE 算法的改进,是没有 critic 网络的,这就可以避免还要联合训练一个 critic;然后就是所谓的 Self-critical 了,采用 greedy decoding 的方法,在测试阶段取自己概率最大的词计算 reward 来作为 baseline,这么做的理由在于,如果我自己按照概率 sample 到的词比测试阶段最高概率的词好,那么就会拔高这个词的分数,在实现梯度下降的同时能充分的做到和测试同步。
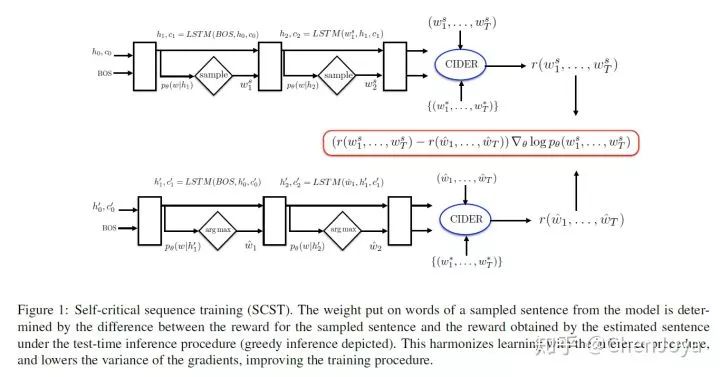
整体的模型是采用了 Show,Attend Tell,直接来对 CIDEr 进行优化。先前在 CIDEr 上最好的分数是 104.9,这篇文章直接将其拉高将近 10 个百分点,可怕!
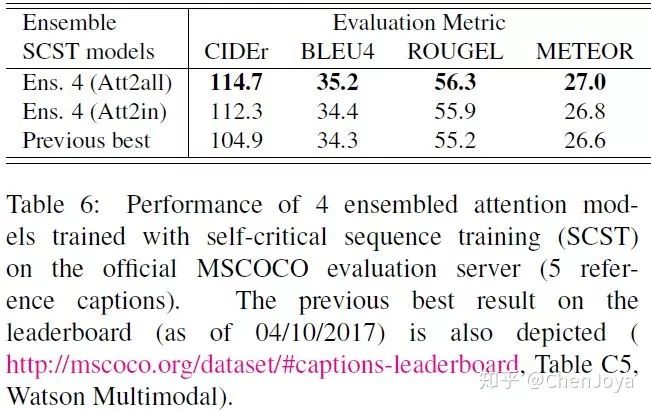
Bottom-Up and Top-Down Attention for Image Captioning(CVPR'18,澳大利亚国立大学 & 京东 AI 研究院 & Microsoft Research & 阿德莱德大学 & 麦考瑞大学)
这篇文章来头同样很大,不仅刷新了 image captioning 的结果,另外获得了2017 VQA Challenge 的第一名!它紧密结合了计算机视觉中的一大基本任务,Object Detection 来做高层次的视觉任务,取得了相当不错的效果。
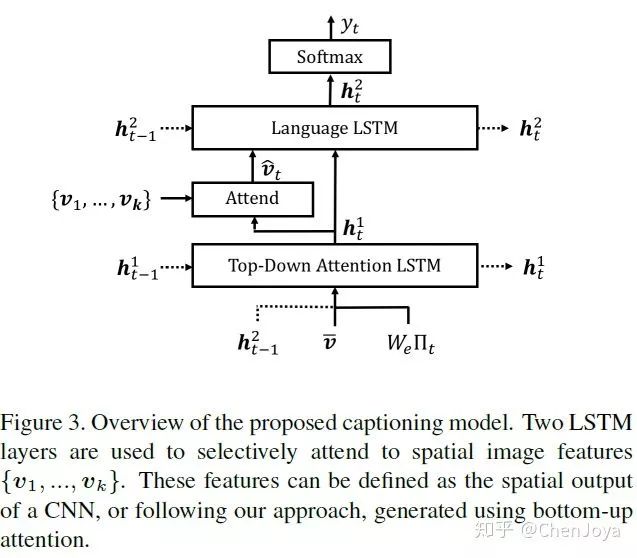
首先,论文题目中有两种 attention 机制,bottom-up attention 是指的人会被视觉中的显著突出物体给吸引,是由图像这种底层信息到上层语义的;而 top-down attention 指的是人在进行某项任务的时候,紧密关注和该任务相关的部分,是由上游任务去关注到图像的。以往在 Image Caption 中的 attention 大多都是 top-down attention,如下图,在 show,attend and tell 中的 attention 其实就可以看成左边的形式,而本文的 bottom-up attention 则允许是在 object-level (或者叫显著性区域)所提取特征。

我们来关注一下构建的模型。整个模型分为提取图像特征的 Bottom-Up Model 和 生成 caption 的 Captioning Model。Bottom-Up Attention Model 采用 Faster R-CNN 作为 检测器,添加一个 attribute class 的分支在 Visual Genome (这里引入了外部数据集?) 上也进行训练,目的是学习到更加好的特征表达。在 Faster R-CNN 跑完之后,我们提取每一个 区域的特征 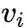 (文中的说法是 mean-pooled convolutional feature from this region)。
(文中的说法是 mean-pooled convolutional feature from this region)。

我们再来看 Captioning Model 。我们现在有了很多个区域的特征集合 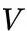 ,而后在生成某个词的时候,我们要对它们先做一个 soft attention,即加权,这也就是属于 top-down attention 了,由一 个 Attention LSTM 来实现,再由 Language LSTM 来生成词语。为什么要特意画分开呢?因为这里是采用了 Self-critical Sequence Training for Image Captioning 的方法,使用 SCST 来优化 CIDEr 的!
,而后在生成某个词的时候,我们要对它们先做一个 soft attention,即加权,这也就是属于 top-down attention 了,由一 个 Attention LSTM 来实现,再由 Language LSTM 来生成词语。为什么要特意画分开呢?因为这里是采用了 Self-critical Sequence Training for Image Captioning 的方法,使用 SCST 来优化 CIDEr 的!
我们关注一下 bottom-up attention 带来的提升。不论是何种优化方法,都能够带来显著的提示。可以看到在 CIDEr 上带来了 8% 的提升,真的是非常强了。
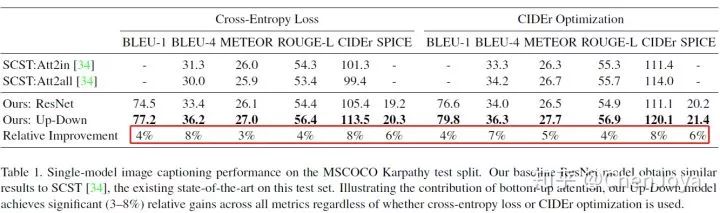
在 ensemble 了四个模型之后,取得了最好的成绩。
Attacking Visual Language Grounding with Adversarial Examples: A Case Study on Neural Image Captioning(ACL'18,麻省理工 & 戴维斯加大 & IBM & 京东 AI 研究院)
在 Image Caption 领域,一般比较主流的提升效果的方法会在视觉相关的会议(主要是 CVPR)上发表,而其它会议上会有一些做 Image Caption 其他方面的创新,比如艺术形式的 Caption,亦或是这一篇在 ACL 2018 上的工作:Show and Fool,使用对抗攻击揭示一下 Image Caption 的模型有多么的脆弱。这样做的意义在哪里呢?我们需要明白,误导一个 caption 的 model 远远比误导一个简单的 classifier 要难: (1)不像分类任务的标签是确定的,caption 任务的结果往往是取 top-n 的。如果将其看成分类任务,将会有巨大的数量,此外同一种意思有千万种表达,不能看作是不同的类;(2)攻击 RNN 的研究本来相对较少,而攻击 CNN+RNN 这样一个模型更是少之又少(文中宣称是第一个对于 Caption 的攻击工作)。

总体的目标函数如下,其中 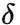 代表扰动,
代表扰动,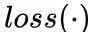 对应着不同的攻击方法。
对应着不同的攻击方法。 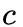 是一个权重,越大则越可能攻击成功,但是扰动的程度也可能越大。
是一个权重,越大则越可能攻击成功,但是扰动的程度也可能越大。
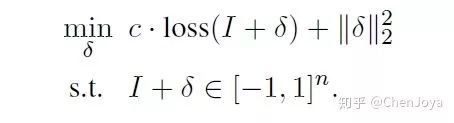
将其变为无约束的问题,引入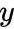 和
和 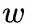 两个变量,目标函数变为:
两个变量,目标函数变为:
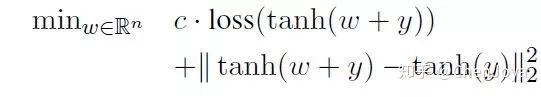
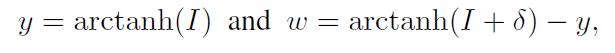
作者提供了两种攻击方式:(1)Targeted caption method:给一句话,扰动任意一张图片让它生成这句话;(2)Targeted keyword method:给一些关键词,扰动图片使其包含这些关键词。我们首先来看 Targeted caption method 的实现方法。我们给定一个 caption  ,想要让模型面对图片时生成它,那么即需保证在所有可能的 captions
,想要让模型面对图片时生成它,那么即需保证在所有可能的 captions  中概率最大:
中概率最大:
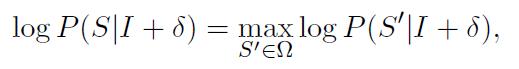
转换成每一个词的对数和:
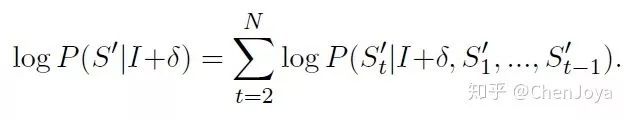
后面的这一项通常由 decoder 的部分给出,我们可以得出前面未曾确定的损失:
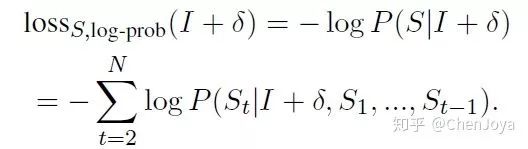
那么整体的损失函数为:
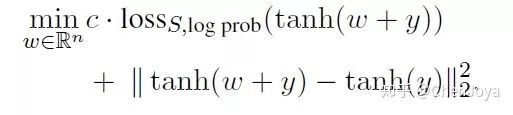
而在 Targeted keyword method 中,我们给定关键词 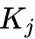 后,作者采用了一种比较简单的处理方法:希望在任何位置,产生这个词的概率都会最大。此外,为了防止多个关键词在同一个位置碰撞,文中引入了一个 gate function ,把其他的关键词的损失掩盖掉。
后,作者采用了一种比较简单的处理方法:希望在任何位置,产生这个词的概率都会最大。此外,为了防止多个关键词在同一个位置碰撞,文中引入了一个 gate function ,把其他的关键词的损失掩盖掉。
整个模型基于 Show and Tell 构建,实验部分,作者讲明如何处理上述“所有可能”的情况:采用原模型在 MS COCO 验证集上的结果作为 targeted caption 。这样的话
不会超出 captioning network 的输出空间。作者也用同样生成的扰动对 Show,Attend and Tell 进行了攻击,证明了这种扰动是可以迁移的。

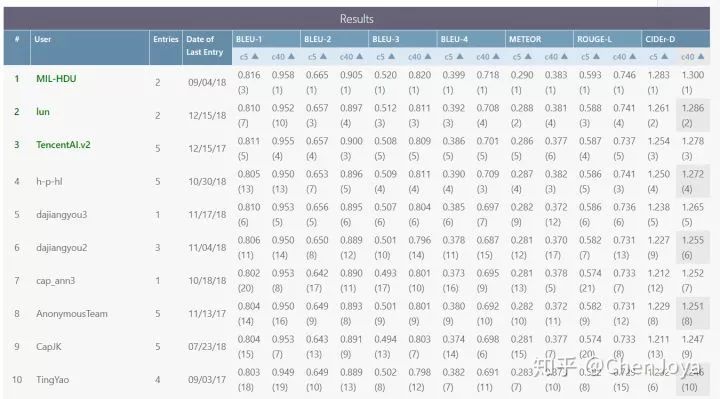
MS COCO Leader Board
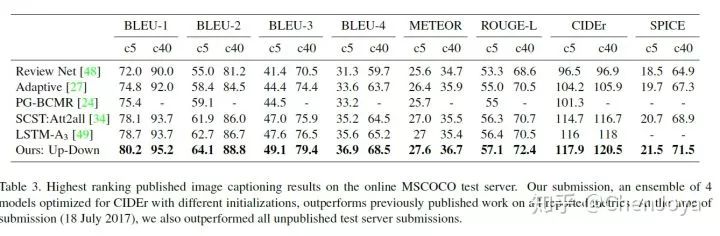
我们来看一看 COCO 的 leader board,虽然刷榜和论文方法有区别,而且也并没有公开方法,但是这可以帮助我们来感受现在的图像描述技术的水准。从 CIDEr-D 上来看,从 2015 年到现在,这个分数上涨了大约有 2 倍之多,图像描述技术的发展不可谓不迅速。
CodaLab - Competition(Microsoft COCO Image Captioning Challenge)
(https://competitions.codalab.org/competitions/3221#results)
结语
最后,让我们以图像描述在艺术领域的应用,ACM MM 2018 上的最佳论文“Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training”,她面向于一张图像所做的诗歌,来结束对于 Image Caption 的回顾:
The sun is shining ---------- 阳光漫步
The wind moves ---------- 和风轻抚
Naked trees ---------- 光裸的树
You dance ---------- 你在跳舞
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会
以上是关于CV+NLP更有智慧的眼睛:图像描述(Image Caption)&视觉问答(VQA)综述(上)的主要内容,如果未能解决你的问题,请参考以下文章