性能测试系列JMeter核心技术:分布式压测和参数化
Posted 测试小工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能测试系列JMeter核心技术:分布式压测和参数化相关的知识,希望对你有一定的参考价值。


在中,我们提到了JMeter的线程启动和运行,是会占用系统资源的,一旦需要大并发,而JMeter单机部署配置不够,将会导致JMeter无法在规定时间内启动对应的线程数,无法对服务器产生预期的压力,最终影响到性能测试的结果。
为了解决单机部署JMeter产生的这类问题,我们引入了JMeter分布式部署。
JMeter分布式的实现,其实是在多台上机器部署java和JMeter。
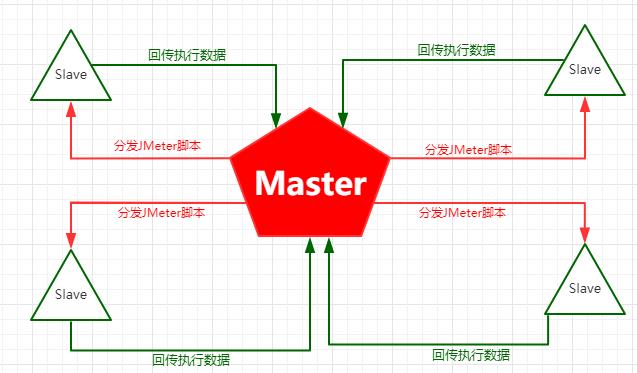
其中有一台机器叫做控制机,我们称之为Master,主要用于JMeter脚本分发和收集汇总Slaves的测试结果。
其他机器叫做压力机,或者叫负载机,我们称之为Slaves,数量可以是1台或多台,主要用于执行JMeter脚本并将结果反馈给Master。
我们来看下Master和Slaves的运行过程:
Master运行时,会把JMeter脚本,分发给其他Slaves。
-
Slaves获取到脚本后,会以命令行的方式,运行JMeter脚本,并把执行产生的数据回传给Master。
-
Master汇总收集所有Slaves运行的结果。
我们来看下下面这张图,能够帮助我们理解这段话:
搞清楚了JMeter分布式的原理,接下来我们来看下JMeter分布式环境搭建的具体步骤:
假设有3台机器:
Master: 10.0.0.1
Slave1: 10.0.0.2
Slave2: 10.0.0.3
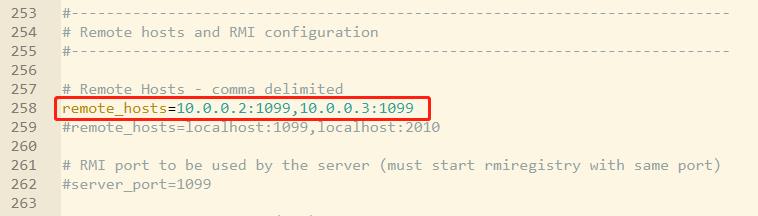
Master配置
Slave配置
1. 在Slave上安装JMeter,并修改jmeter.properties文件配置,如下图所示:

注意:
1. 端口如果没有被其他应用程序占用,可以不用修改server_port。
2. remote_hosts不用改。
2. 启动JMeter/bin目录下的jmeter-server。
-
以上配置完成后,我们就可以在Master上执行以下命令运行我们的脚本进行性能测试了:
jmeter -n -t test.jmx -l test.jtl -e -o test_report
以上就是JMeter分布式的运行原理和搭建步骤,接下来我们来了解下参数化。

讲参数化之前,我们先来思考一个问题,为什么要做参数化?
原因主要有以下两点:
缓存
缓存的作用是为了提高数据的处理效率而设置的,比如某个用户频繁重复获取某一个商品的信息,有极大可能就是访问的缓存的数据,这种场景和实际的线上场景显然是不符合的。
而线上实际场景可能是多个用户获取多个不同的商品信息,这时候很大可能不是访问的缓存数据。
而cpu读取缓存的速度会比不读取缓存的速度快很多,这样会让性能测试结果和线上的实际运行情况不符合。
业务的需要
举个实际的例子,比如买车票,同一天同一车次,一个人只能买一张,这个时候如果不对用户做参数化,就会导致购票失败。
JMeter参数化有很多种,这里介绍下常用的3种方式:
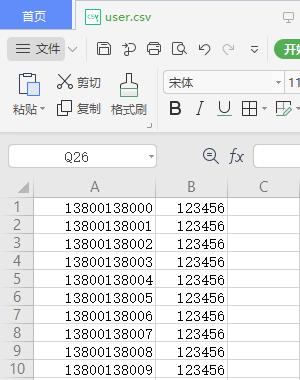
CSV Data Set Config组件:将参数放在txt或者csv文件中
新增一个存放参数化数据的文件:user.csv
添加一个csv Data Set Config
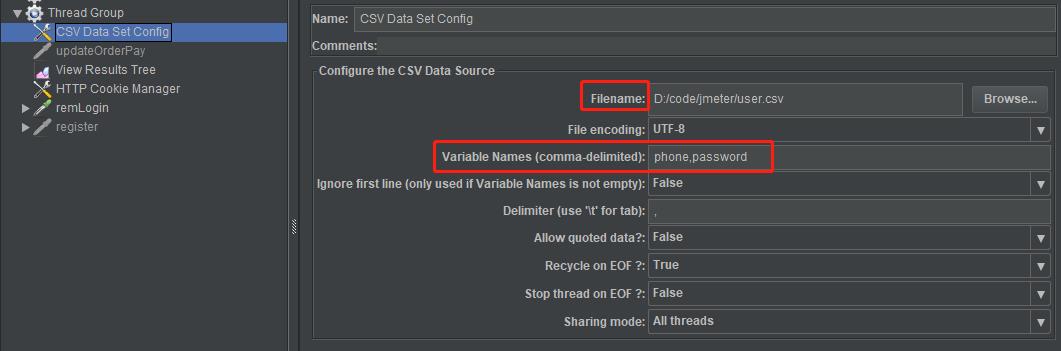
在HTTP Requests里使用参数:
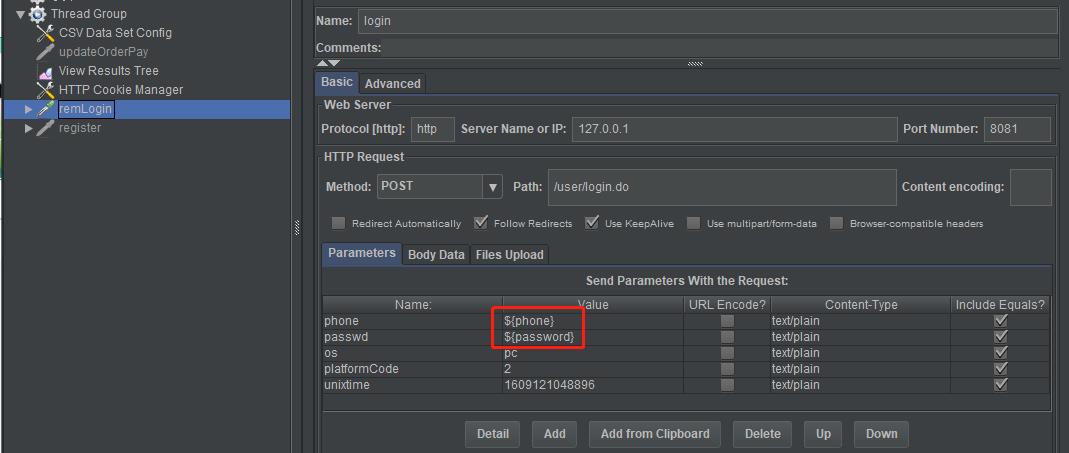
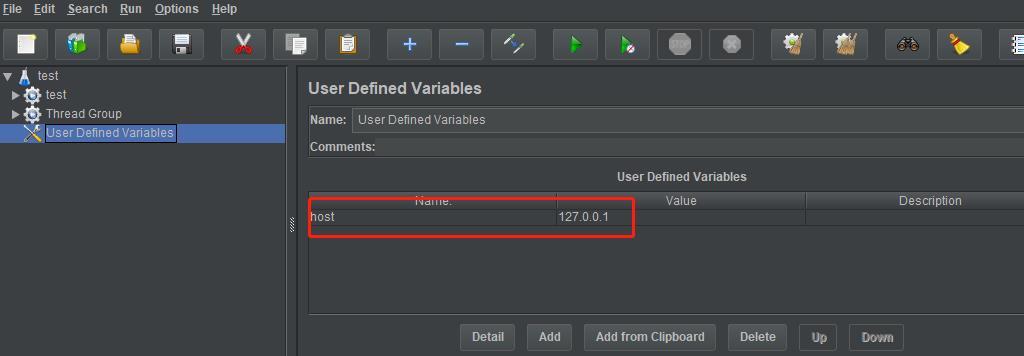
User defined variable: 通常用来配置脚本公共的参数,比如域名,端口号等
新增一个config element - User defined variable组件:
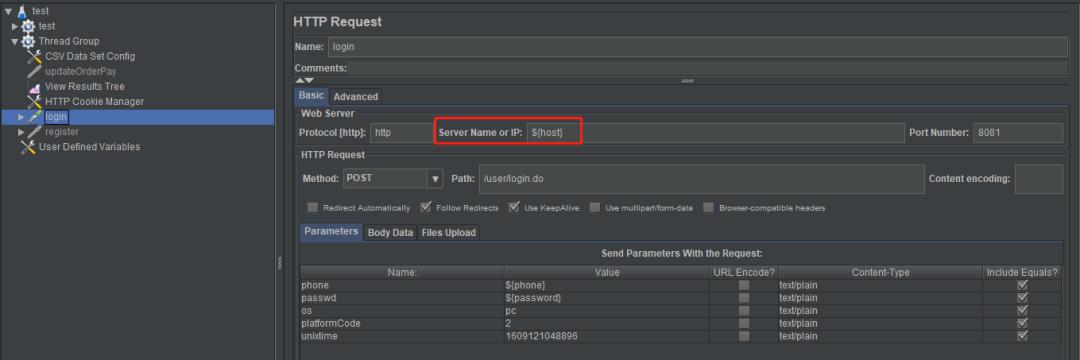
在HTTP Requests里使用:
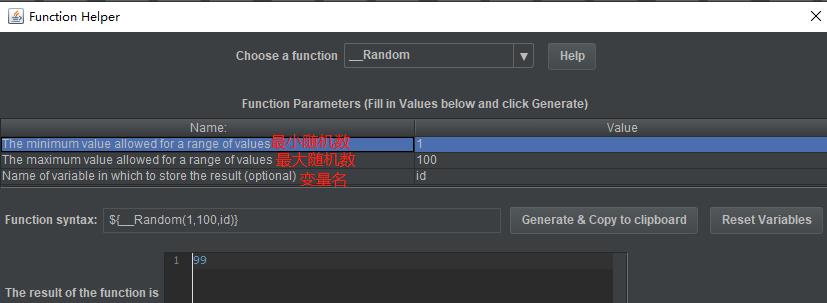
__Random可用于生成随机数,用法:
__CSVRead可用于读取文件,用法:
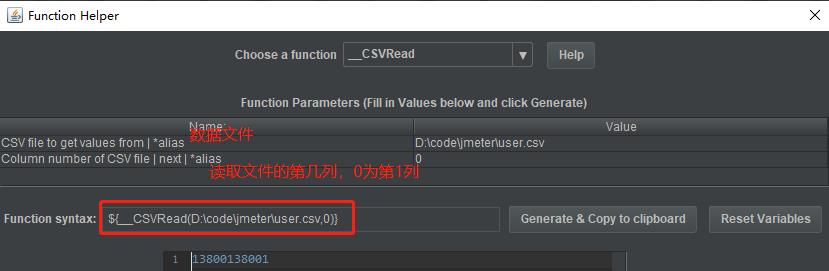
以用户登录的请求参数:phone(手机号),password(密码)为例
3. Function Helper(函数助手)中的函数:如__CSVReader,__Random等
下一期预告:JMeter二次开发和Beanshell脚本

扫描二维码,技术文章第一时间获取!
福利 |
性能测试 |
测试开发系列 |
测试开发系列 |
自动化测试 |
测试必须懂 |
以上是关于性能测试系列JMeter核心技术:分布式压测和参数化的主要内容,如果未能解决你的问题,请参考以下文章
jmeter非GUI(cmd命令行)模式的压测和输出测试报告
性能测试 性能测试实战Jmeter性能测试平台开发,性能测试平台架构解析 ,性能测试平台搭建 分布式性能压测平台 Jmeter分布式性能测试管理平台 性能测试平台示例案例 《完结篇》