数据可视化专题R读取多种格式的数据与常见错误原因汇总
Posted 智汇医圈Plus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化专题R读取多种格式的数据与常见错误原因汇总相关的知识,希望对你有一定的参考价值。
智慧医圈Plus,每天进步一点点!

前言
自本期开始,我们将围绕着R与数据可视化发布一个新的专题【R与数据可视化专题】,若你此前阅读“你离R语言大神只有七步之遥”之后,开启过热血沸腾之旅,那么估计多半人尝试之后就只剩无尽沮丧了。没办法,牛B的神器,都是有点性格的,不太容易相处。
为了重启热血之旅,就让我们一步步拆解那篇文章中提到的步骤,逐步熟练掌握这统计与可视化神器吧!

数据读取的关键点
所谓巧妇难为无米之炊,用好R的第一步就是这读取数据了。纵使可视化的代码和生成的图让人心醉神迷,若读入数据这第一枪打不响,估计剩下的也就只有无尽惆怅与暗自神伤了!而很多人就半途而废在这读取数据上了。那就让我们先来看看数据读取前需要Check的几个问题吧!
1.弄明白文件的分隔符(从Excel导出时尤其要注意用逗号/Tab/分号或是其它)
2.行名和列名如何设置(直接从文件中读取/读入后再生成)
3.数据类型是什么(纯数字/纯字符串/两者混合,警惕Excel表改动你的数据)
4.是否有缺失值(有/无)
5.目标函数需要什么形式的数据
(List/DataFrame/Vector/Matrix/
Factor)
6.目标函数能否容忍缺失值(具体查看函数说明文档)
导入CSV/TXT/TSV文件
接下来就让我们看看常见的CSV/TXT/TSV格式文件的读取吧!
这三种类型的文件通常用read.table函数族来解决。最常用的是read.table和read.csv,而read.csv和read.table实际上是一样的,只是设置的默认值不同罢了。
read.csv、read.csv2、read.delim是read.table函数的包装,分隔符分别对应逗号,分号,制表符,同样接受read.table所有参数。因此针对这三种类型的文件,完全可以用read.table一个函数搞定,只不过要对参数比较熟悉,依据实际情况进行调整。


小智提醒

重点注意:
read.table函数以数据框的格式读入数据,所以适合读取混合模式的数据,但是要求每列的数据数据类型相同。
常见参数解析
看如何一步步读入合适的DataFrame
file参数
这是必须的,可以是相对路径或者绝对路径(注意:Windows下路径要用斜杠'/'或者双反斜杠'\')

header参数
其默认为FALSE,即数据框的列名为V1,V2...设置为TRUE时第一行作为列名。
神奇的header,当你设置为TRUE时,就自动拥有了列名哦,省时省力。

注意
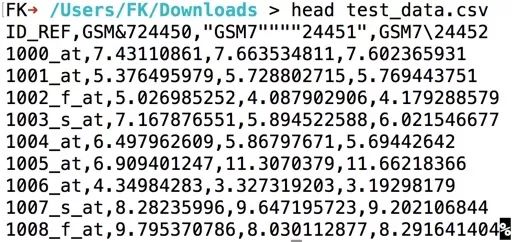
当第一行包含特殊字符时
可能给后续数据处理带来问题
可提前处理好特殊字符
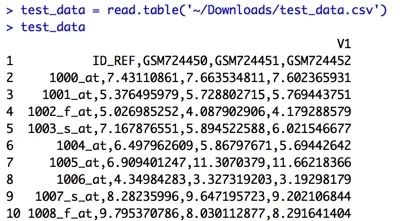
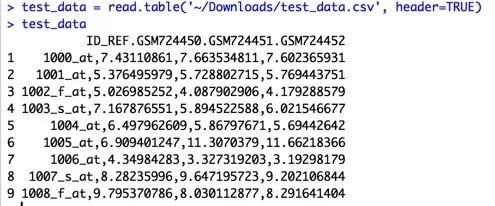
看看R read.table都是怎么处理行列名中特殊字符的!
sep参数
读入csv/tsv/txt等文本文件时最为重要的参数,大家在读入数据时不能依赖于后缀名,而应该自行检查文件的分隔符。
尤其是经Mac/Windows其它软件生成或转换而来的文本文件时尤其如此。
一起来看看它的魔法吧!

row.names参数
一个header参数让我们自动获得了列名,那么有办法让data.frame自动获得行名吗?省去手动转换的麻烦!那就让我们一起来看看row.names参数吧!
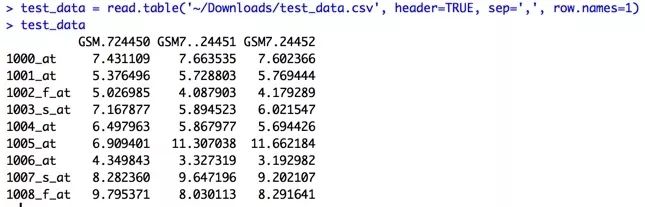
是不是很酷炫!
注意
rows.names其中一种用法就是指定列数
以其作为行名的时候
一定要确保指定的列没有重复哦
否则就会出现如下错误!

stringAsFactors
字符型数据读入时自动转换为因子,因子是R中的变量,它只能取有限的几个不同值,将数据保存为因子可确保模型函数能够正确处理。
But当变量作为简单字符串使用时可能出错。要想防止转换为因子:
1.令参数stringAsFactors=FALSE,防止导入的数据任何的因子转换。
2.更改系统选项options(stringsAsFactors=FALSE)
3.指定抑制转换的列:as.is=参数。通过一个索引向量指定,或者一个逻辑向量,需要转换的列取值FALSE,不需要转换的列取值TRUE。
如何加速读取
你的文件是不是很大,大到每读入一次都感觉像是过了一个世纪?那么就快来试试如下方法吧!
设定colClasses参数,其对读取速度能提升一倍
1.先读取头100行,用这小段样本来确定每列的类型
2.识别每列的数据类型,而后再整个读取

原理:
这样做可以加速其实是通过事先告诉数据类型,避免R在读入数据时去推测数据类型,而浪费时间。
采用新的读取数据的函数/包,比如...
Amazing包
(不要怀疑你的眼睛,这就是个代称,如果想要知道具体的包名,请 回复20180417R获取;得来不易的才懂得珍惜哦,赶快去试用吧!)
Hadley Wickham和RStudio团队写了一些新的R包,这些包对于每个需要在R中读入数据的人来说都是非常有用的。Amazing包提供了一些在R中读入文本数据的函数。我们通常会用R中的read.table家族函数来完成我们的数据读入任务。这里,Amazing包提供了许多替代函数。它们增加了额外的一些功能并且速度快很多。
下面给一组对比数据说明下什么叫牛B,读取一个包含400万行的数据,两者差距有多大。(实际数据与计算机配置有关,不一定与如下时间相同)
read.table花的时间是50.62秒,而Amazing包中的read_table完成相同的任务只花了2.76秒。是不是有种飞一样的感觉?这是因为read_table把数据当做是固定格式的文件,并且使用C++快速处理数据。膜拜Hadley Wickham大神,简直高产的不要不要。发明了ggplot这种神器不说,简直变态,几乎每个开发的包都是屌炸天的神器。
大家在使用R的过程中是不是遇到过如下问题?
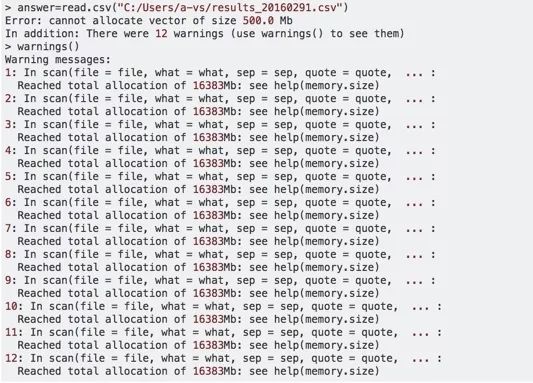
当你希望用它来读取相对较大的数据集或是文件的时候,你需要注意了,很可能导致出现上述错误。此错误是由于读入数据所需内存容量已经超出分配给R的内存容量导致的。因此,当你想读入大文件时,需要大概估算读取需要的内存,当大于你所拥有的物理内存的时候,你最好另想办法!
无论如何,当你使用的R读取大量数据的时候,要系统化的想问题:

你的系统有多少内存?
系统上有没有其他应用?
系统上有没有其他人也在工作?
啥操作系统?
32位还是64位滴?
下面是一个典型的估算内存的场景
大多数初学者刚开始都不会涉及这个问题
无论如何
看看还是很有趣~

R语言就是集智慧与美貌于一身的神器
看到这里你有没有想去试一试呢~
赶紧动身吧!
好了~
今天的推送就到这里
欢迎持续关注哟(^U^)ノ~YO


相关原文
往期热点

智汇如水
积少成多

HAPPY

科研资讯 尽在智汇
以上是关于数据可视化专题R读取多种格式的数据与常见错误原因汇总的主要内容,如果未能解决你的问题,请参考以下文章
如何设计一个漂亮的仪表盘—Jeecg仪表盘轻松实现数据可视化专题