基于R语言空间数据可视化导论-以2014年中国各省就业人口数为例
Posted 泥板书房
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于R语言空间数据可视化导论-以2014年中国各省就业人口数为例相关的知识,希望对你有一定的参考价值。
空间数据可视化可以形象直观地展示空间数据的结构特征和复杂关系,使其易于理解、接受以及对知识进行更高层次的抽象概括,因此空间数据的可视化被广泛地应用于空间数据的理解、知识的发现和表现。在实际工作中Arcgis作为空间数据可视化的主要工具而被广泛应用,但因其价格较高、安装需要的内存较大,也给我们的使用带来很大的不便。因此本文对R语言及其相关包可视化空间数据进行介绍,希望可以为大家提供一个快速、友好、便捷的地理数据可视化方法。
实战开始:
1.加载程序包
library(ggmap)
library(rgdal)
library(rgeos)
library(maptools)
library(dplyr)
library(tidyr)
library(tmap)
2.加载地理数据
geodata <- readOGR(dsn=”sheng”, layer = “CN-sheng-A”)
3.查看数据
head(geodata@data)
plot(geodata)
nrow(geodata)
4.加载统计数据
library(readxl)
sta <- read_excel(file.choose())
sta <- as.data.frame(sta)
5.将统计数据链接到矢量文件的属性表中
geodata@data <- left_join(geodata@data, sta, by=c(“SHENG_ID” = “SHENG_ID”))
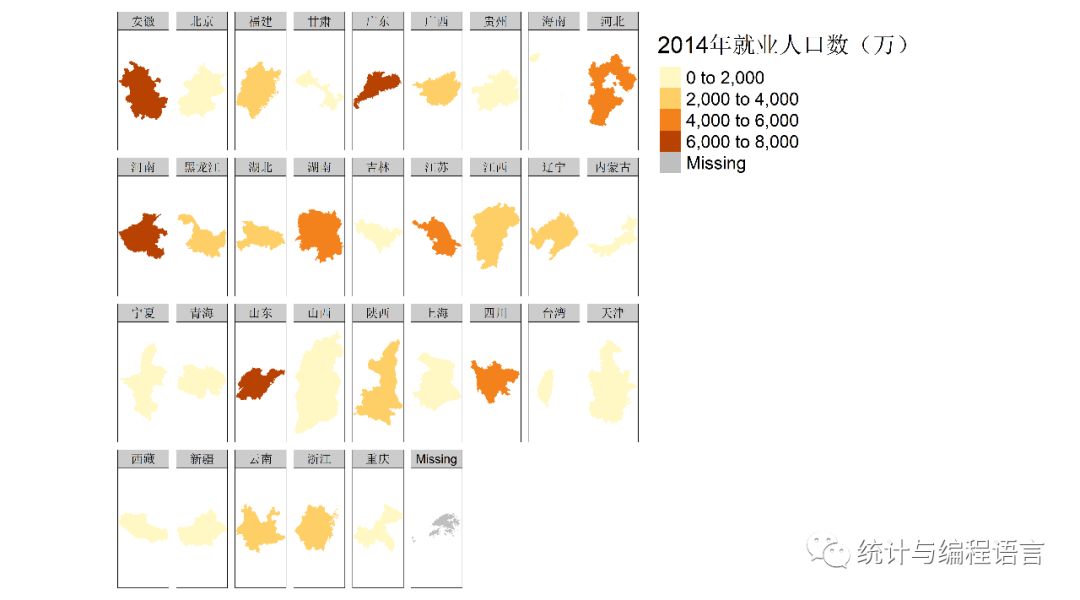
6.基于tmap绘制就业人口分布图
tm_shape(geodata)+tm_fill(“job2014”, thres.poly=0,title =”2014年就业人口数(万)”,palette=”Reds”)+tm_text(“name_e.x”)+tm_borders(“grey40”, lwd=1)#tmap绘制地图
tm_shape(geodata)+tm_fill(“job2014”, thres.poly=0)+
tm_facets(“name.y”, free.coords = TRUE, drop.units = TRUE)#依据省的名字分面绘制
7.选择并突出显示就业人口大于4000万的区域
plot(geodata, col = ‘lightgrey’)#画基本地图
sel <- geodata$job2014 > 4000#选择大于4000万的数据
sel <- na.omit(sel)#删除NA值
plot(geodata[sel, ], col = ‘turquoise’, add=T)#添加大于4000万的图层
最后大家可以考虑一下怎么基于tmap突出显示就业人口大于4000万的区域!!!
需要文中数据和基于tmap突出显示就业人口大于4000万的区域可以留言给我。
以上是关于基于R语言空间数据可视化导论-以2014年中国各省就业人口数为例的主要内容,如果未能解决你的问题,请参考以下文章
数据可视化应用核密度空间插值实战案例(附Python和R语言代码)