数据可视化|用Python实现手机抓包,获取当当图书差评数据!
Posted Python绿色通道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化|用Python实现手机抓包,获取当当图书差评数据!相关的知识,希望对你有一定的参考价值。
有态度地学习
在这个万物互联的时代,手机端(App)、电脑端(Web),连接着你我他。
本次学习了手机抓包的相关知识,了解了Charles-mitmproxy-Appium的基本使用,通过对当当图书评论的爬取,得以实践。
那么就让我们来看看当当图书「活着」的差评吧!
/ 01 / Charles
Charles是一个APP抓包工具,与我之前最先使用的Filddler相似,可以得到手机App运行过程中发生的所有网络请求和响应内容。
这里简单说一下安装。
电脑端下载安装完Charles后,需要配置证书,最后开启SSL监听,这个具体大家自己自行百度。
连好以后,手机打开当当App,到图书「活着」的差评页,不断向下滑动差评页面,便能在电脑上的Charles观察到下面的信息。
将电脑上的信息与手机上的信息匹配一下。
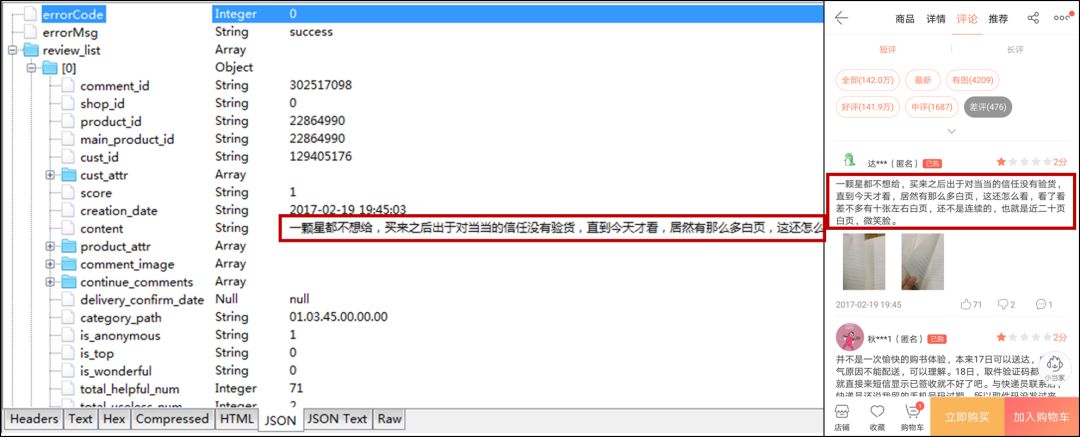
这样我们通过请求信息,就可以知道App评论的真正API接口了。
不过呢有的时候会碰见App接口带有密匙的,我们不好确定出API接口,那么就轮到mitmproxy上场了。
/ 02 / mitmproxy
mitmproxy也是用来抓包的,是一个控制台形式,我理解的就是没有UI界面,在命令行上展示的(windows上不能用,我瞎理解的...)。
mitmproxy有两个关联组件,一个是mitmdump,是mitmproxy的命令行接口,可以对接Python脚本,用Python实现监听后的处理,也就是用脚本处理信息。
另一个是mitmweb,为Web程序服务,本次不涉及。
mitmproxy的安装同样需要证书配置,电脑端配一个,手机端也要配一个。
这里有个坑,我的华为手机直接识别不了pem格式的文件,无法直接安装,还得从SD卡那才能安装,也就是有权限问题。
手机WIFI代理设置和Charles差不多,只是端口需要改变,这里是8080,。
然后命令行运行我都是在mitmdump.exe所在的文件夹开启的,实在是不想去搞那些烦人的环境变量。
这里就直接讲mitmdump的应用,毕竟windows用不了mitmproxy。
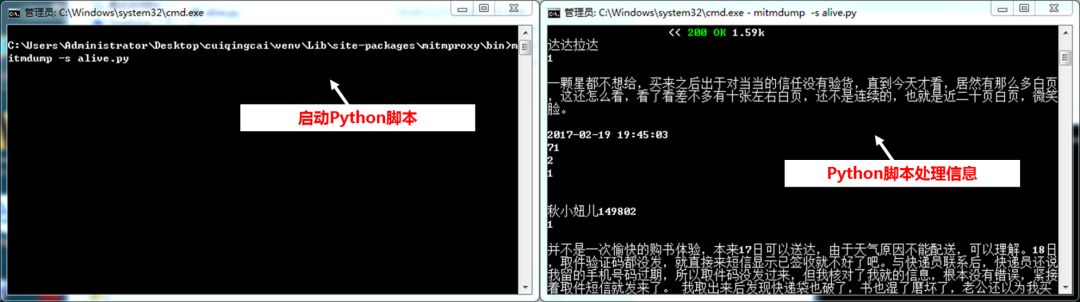
通过手动下滑差评页面,就能自动处理信息并存储。

Python脚本如下,第一次深刻接触脚本大佬,以前还只是听说了游戏脚本而已。
import json
def response(flow):
url = 'product.mapi.dangdang.com'
page_size = 'page_size=15'
# 对url进行筛选,只选取评论的url
if url and page_size in flow.request.url:
text = flow.response.text
data = json.loads(text)
for item in data['review_list']:
# 获取用户昵称
if len(item['cust_name']) > 0:
name = item['cust_name']
else:
name = '无名'
print(item['cust_name'])
# 获取用户评分
if len(item['score']) > 0:
score = str(item['score'])
else:
score = '0'
print(item['score'] + '\n')
# 获取用户评论
content = item['content'].replace(',', ',').replace('\n', '')
print(item['content'] + '\n')
# 获取用户评论时间
creation_date = item['creation_date']
print(item['creation_date'])
# 获取有用数
if len(str(item['total_helpful_num'])) > 0 :
total_helpful_num = str(item['total_helpful_num'])
else:
total_helpful_num = '0'
print(item['total_helpful_num'])
# 获取无用数
if len(str(item['total_useless_num'])) > 0 :
total_useless_num = str(item['total_useless_num'])
else:
total_useless_num = '0'
print(item['total_useless_num'])
# 获取评论数
if len(str(item['total_reply_num'])) > 0 :
total_reply_num = str(item['total_reply_num'])
else:
total_reply_num = '0'
print(item['total_reply_num'])
print('\n')
# 将获取信息写入csv文件
with open('alive.csv', 'a+', encoding='utf-8-sig') as f:
f.write(name + ',' + score + ',' + content + ',' + creation_date + ',' + total_helpful_num + ',' + total_useless_num + ',' + total_reply_num + '\n')
python
那么我们现在已经实现了信息的获取和存储,是不是已经完成工作了呢?
并不是,我们还要实现自动化,上面可是手动下滑页面啊!
感谢程序让人解放双手,实现自动化,佩服佩服。
/ 03 / Appium
Appium是移动端自动化测试工具,它可以模拟App内部的各种操作,本次用到就有「点击」和「下滑」。
其实就跟selenium 一样,只不过一个是电脑端自动化,一个是手机端自动化。
Appium安装挺复杂的,而且新版本的命令还不一样。
比如下滑,已经不能使用swip,而是使用TouchAction。
环境变量就是JDK,SDK等,坑太多,小伙伴慢慢体会...
都准备好了之后,将手机和电脑通过数据线连接,打开USB调试,允许访问数据。
用adb命令获取连接情况,及手机型号信息。
用SDK包下的aapt命令获取APK的包名及入口名,这里不细说,有事找度娘。
这样便能配置Appium参数了。
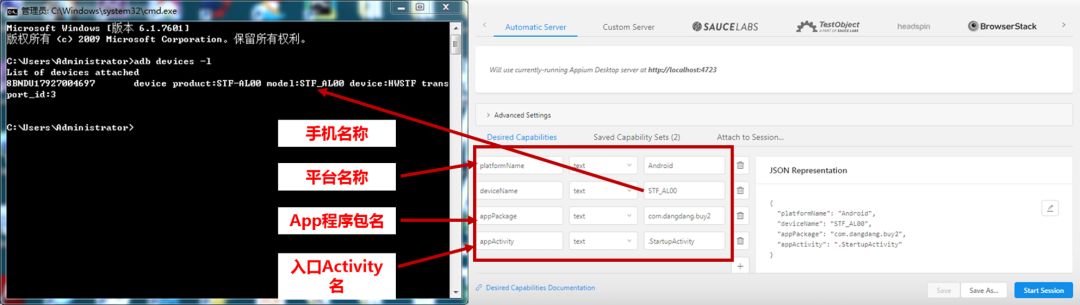
点击蓝色按钮,手机便能自动启动当当App啦!
接下来就是操作手机,然后点击Appium的刷新键,获取元素定位代码,这里就完全用Appium上给的定位,懒得想,毕竟对手机网页不是很懂...
{ 左右滑动切换图片 }
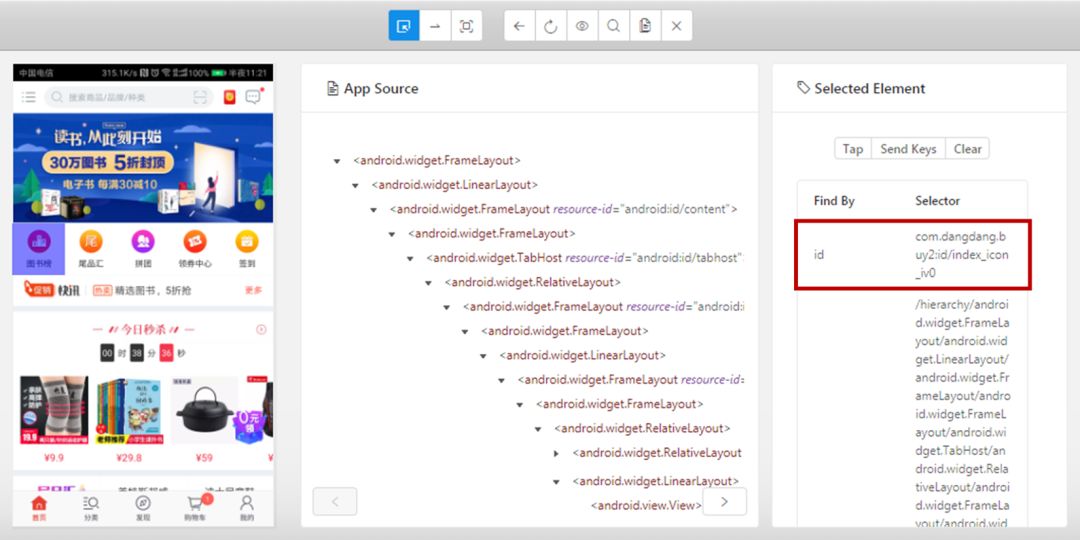
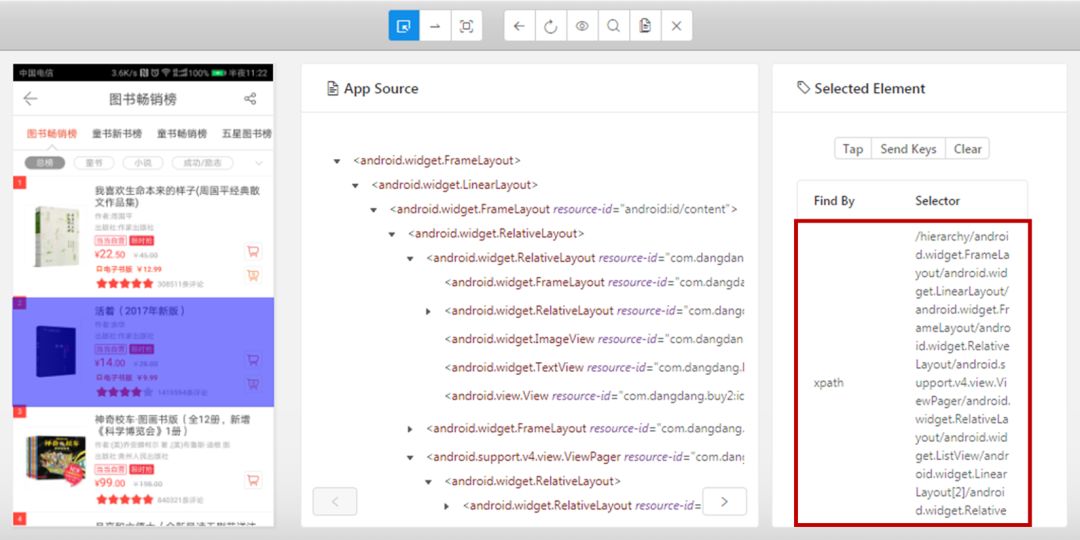
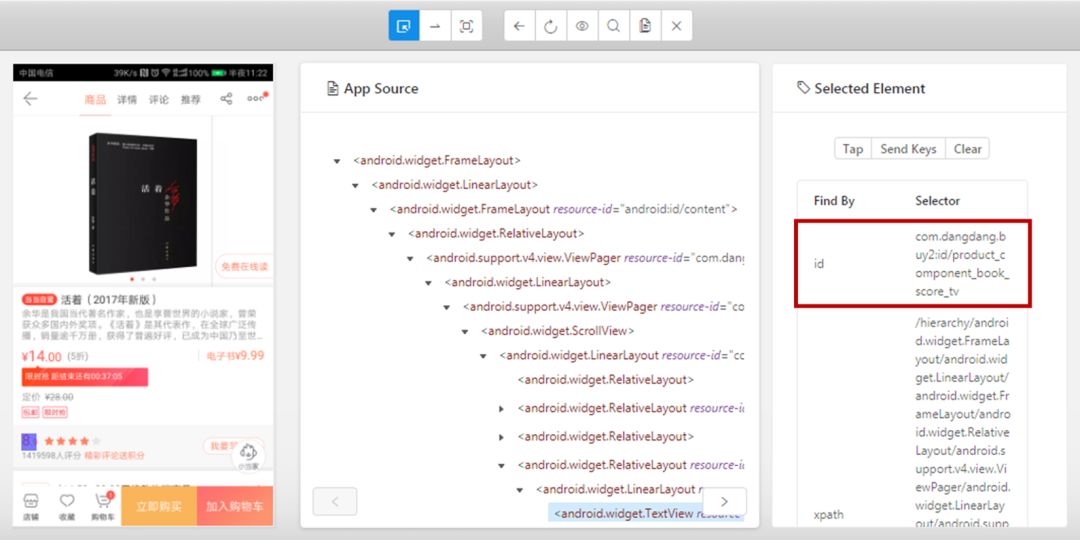
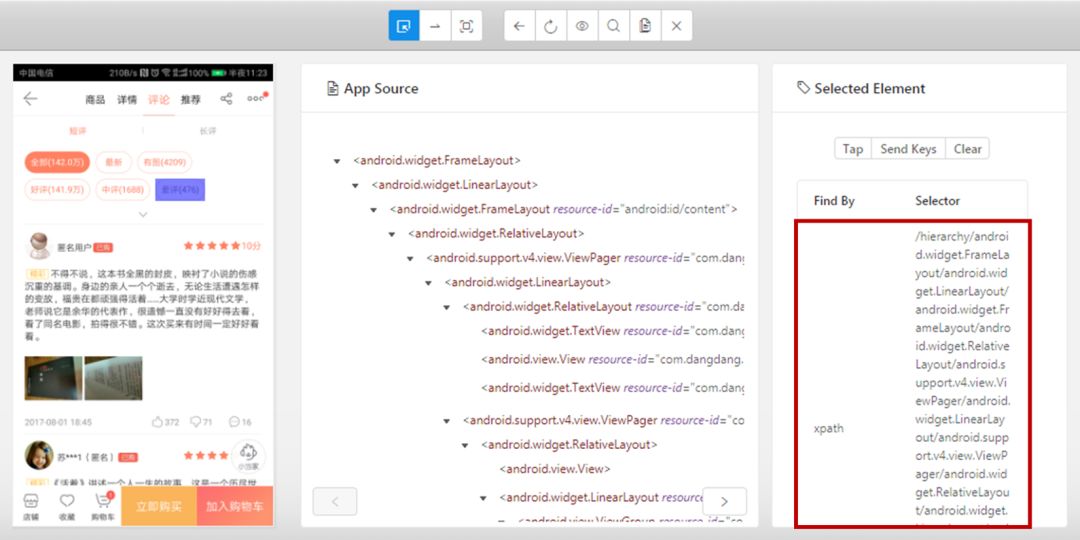
最后就是使用Python代码驱动App啦。
import time
import random
from appium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from appium.webdriver.common.touch_action import TouchAction
from selenium.webdriver.support import expected_conditions as EC
def main():
# 设置驱动配置
server = 'http://localhost:4723/wd/hub'
desired_caps = {
'platformName': 'android',
'deviceName': 'STF_AL00',
'appPackage': 'com.dangdang.buy2',
'appActivity': 'com.dangdang.buy2.StartupActivity'
}
driver = webdriver.Remote(server, desired_caps)
# 这里获取一下手机屏幕实际大小,可以为设置滑动参数做参考
size = driver.get_window_size()
print(size)
wait = WebDriverWait(driver, 60)
# 因为要叫我切换地区,选择取消
button_1 = wait.until(EC.presence_of_element_located((By.ID, 'com.dangdang.buy2:id/left_bt')))
button_1.click()
# 点击图书榜按钮
button_2 = wait.until(EC.presence_of_element_located((By.ID, 'com.dangdang.buy2:id/index_icon_iv0')))
button_2.click()
# 点击图书「活着」区域块
button_3 = wait.until(EC.presence_of_element_located((By.XPATH, '/hierarchy/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.support.v4.view.ViewPager/android.widget.RelativeLayout/android.widget.ListView/android.widget.LinearLayout[2]')))
button_3.click()
# 点击评论区域块
button_4 = wait.until(EC.presence_of_element_located((By.ID, 'com.dangdang.buy2:id/product_component_book_score_ll')))
button_4.click()
time.sleep(5)
# 点击差评按钮
button_5 = wait.until(EC.presence_of_element_located((By.XPATH, '/hierarchy/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.support.v4.view.ViewPager/android.widget.LinearLayout/android.support.v4.view.ViewPager/android.widget.RelativeLayout/android.widget.LinearLayout/android.view.ViewGroup/android.widget.RelativeLayout[6]/android.widget.TextView')))
button_5.click()
# 向下滑动,y轴参数我随便选的,向上滑就对了
while True:
TouchAction(driver).press(x=515, y=1247).move_to(x=515, y=1026).release().perform()
time.sleep(float(random.randint(5, 10)))
if __name__ == '__main__':
main()
手机自动操作就在下面这个视频里,我录下来的(小程序识别)。
最后成功存储数据。
/ 04 / 数据可视化
词云代码如下。
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
df = pd.read_excel('alive.xlsx', header=None, names=["name", "score", "comment", "date", "up_number", "down_number", "reply_number"])
text = ''
for line in df['comment']:
text += ' '.join(jieba.cut(line, cut_all=False))
backgroud_Image = plt.imread('book.jpg')
stopwords = set('')
stopwords.update(['没有', '什么', '不是', '知道', '怎么', '就是', '本书', '当当', '这个 商品', '一个', '自己', '真的', '商品 不太好', '一本', '这样', '但是', '现在', '你们', '一直', '以后', '这个', '商品'])
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STZHONGS.TTF',
max_words=2000,
max_font_size=150,
random_state=30,
stopwords=stopwords
)
wc.generate_from_text(text)
# 看看词频高的有哪些,把无用信息去除
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e:e[1], reverse=True)
print(sort[:50])
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
wc.to_file("活着.jpg")
print('生成词云成功!')
最后生成差评词云,来看看大家怎么吐槽的。

可以看出主要槽点就是「快递物流」「书本质量」「客服服务」上 。
毕竟「活着」这本书,内容还是不错的,从中深深的体会到生活的不易~
扫码加我私人微信
ps: 如果你想关注一下非技术方面的知识,可以关注我的小号,说些搜索引擎找不到知识!
以上是关于数据可视化|用Python实现手机抓包,获取当当图书差评数据!的主要内容,如果未能解决你的问题,请参考以下文章
Python手机抓包案例,用Charles捕获春雨医生接口数据