数据可视化全国排名前300的学校地区分布可视化
Posted 数据智农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化全国排名前300的学校地区分布可视化相关的知识,希望对你有一定的参考价值。
数据可视化全国排名前300的学校地区分布报告
第一:数据获取
网络爬虫
(1)编程代码
import requests
from bs4 import BeautifulSoup
import bs4
def gethtmlText(url):#爬取网页信息并返回给其他函数
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#产生异常信息
r.encoding=r.apparent_encoding#解决异常信息
return r.text#把信息传递给其他函数
except:
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td') #class="hidden-xs need-hidden indicator5" style="display: none;"
ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string])#
def printUnivList(ulist,num):
tplt = "{0:^10}\t{1:{4}^8}\t{2:6}\t{3:10}"
print(tplt.format("ranking","school name","area","score",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
def main():
uinfo = []#将大学信息放入这个列表中
url ='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html=getHTMLText(url)#调取三个函数
fillUnivList(uinfo,html)
printUnivList(uinfo,300)
main()
(2)代码运行步骤
1、打开Anaconda3下面的Spyder
2、把名为school的py文件导入
3、第三点击运行按钮
(3)代码运行截图
第二:数据清洗
(1)把Spyder运行窗口的数据复制黏贴到excel
截图:
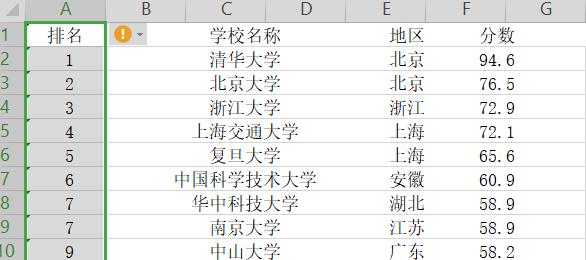
(1)由图可见所有数据都在一列所有需要把数据进行分列处理
1、点击分列进行分列
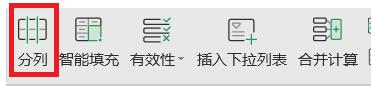
2、点击分隔符号
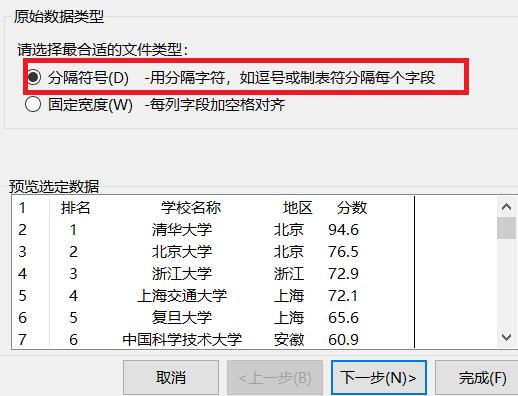
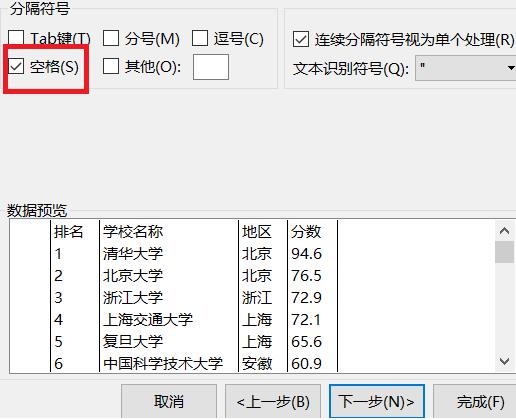
3、
(3)运用数据透视表把地区里面重复的地点进行合并


2、把地区选中拖拽到行的位置

(4)先在地区后面插入一列然后填入1再运用SUMIF函数把所有重复地区的个数统计出来
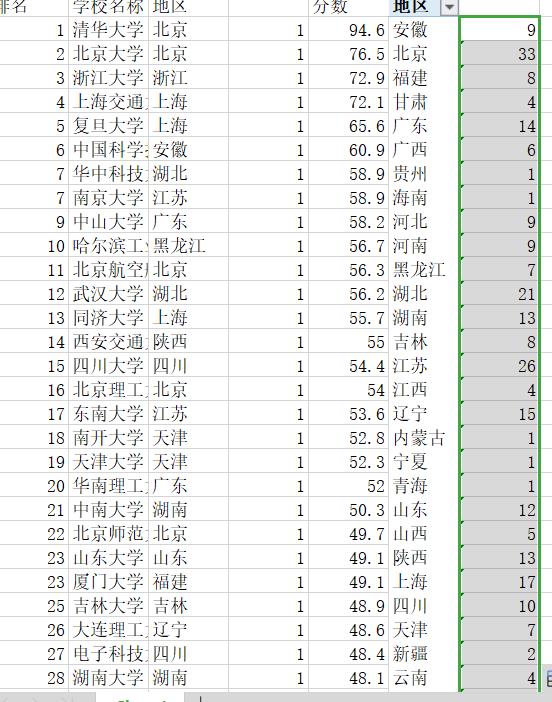
(5)运用同样的方法提取出前十名的高校的重复地区的个数
(6)把同一个地区的所有高校与排名评分进行筛选然后按Ctrl+g快捷键之后选择显示可见单元格选项进行复制黏贴形成一个新的excel表
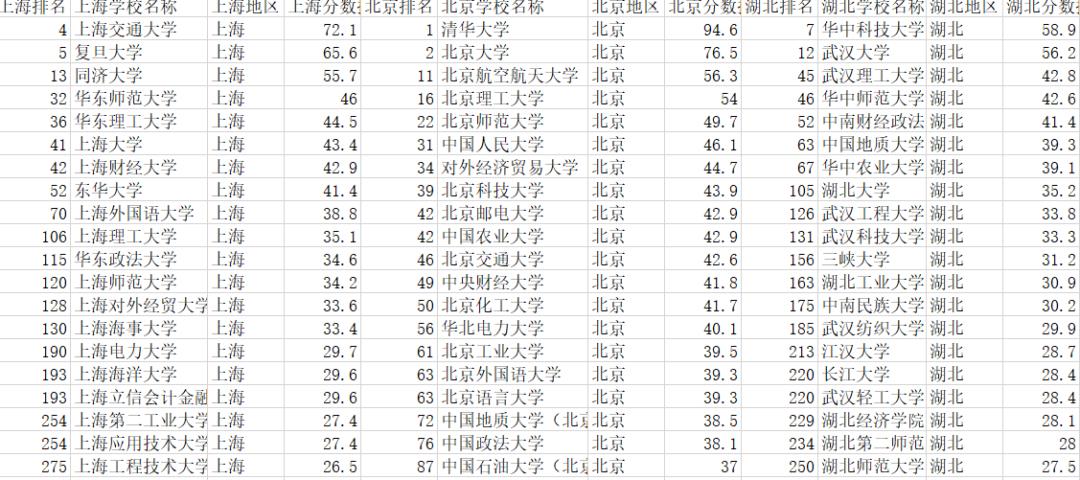
第三:数据可视化制作过程
(1)运行BDP进行数据可视化
(2)网址:https://me.bdp.cn/home.html
(3)操作过程
1、进入首页
2、导入数据点击数据源然后点击立即添加

3、点击excel

4、点击上传文件

5、导入数据后点击工作表然后点击新建图表
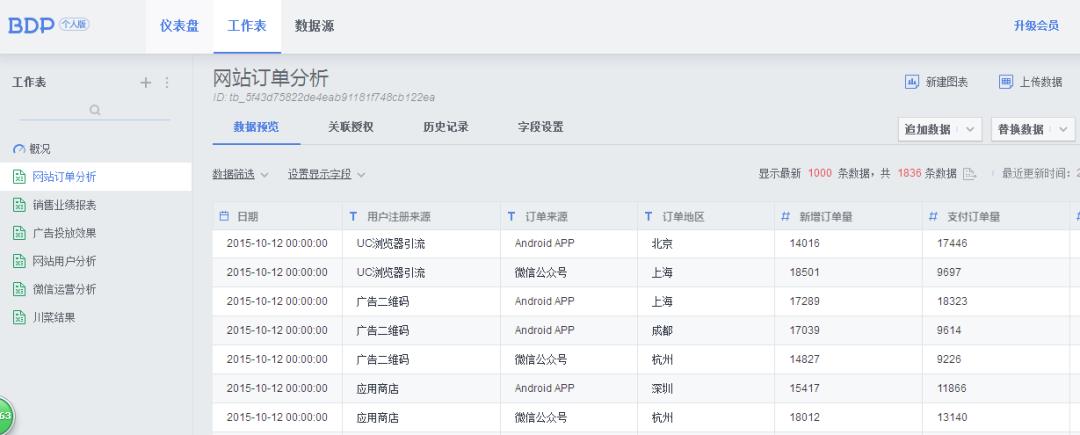
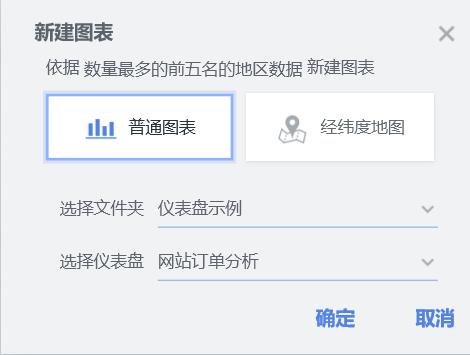
6、点击如下选项然后点确定
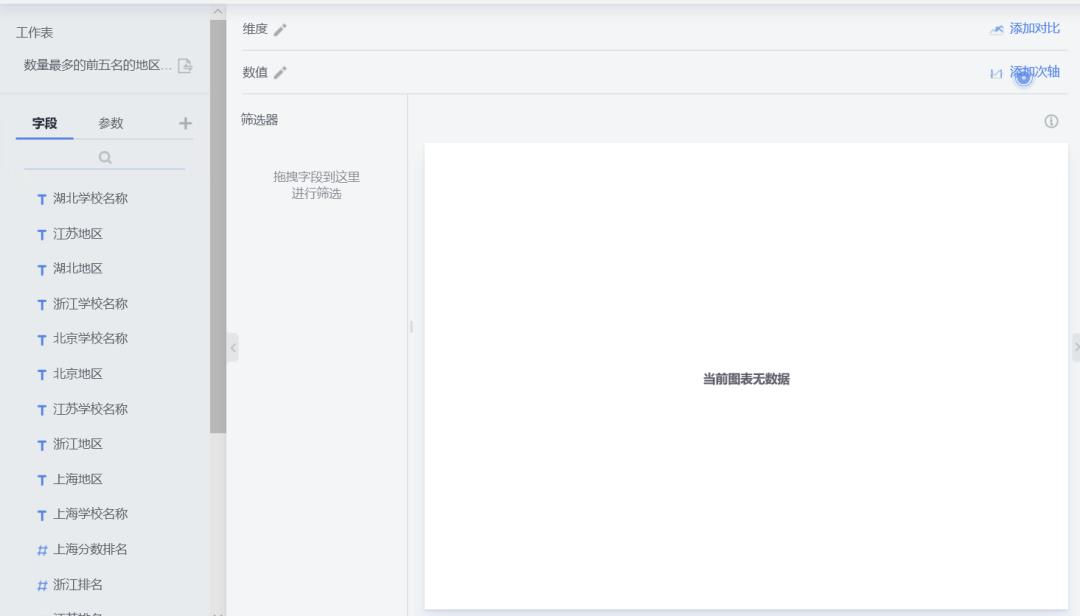
7、点击左下角数据到数值和维度的位置形成图形保存
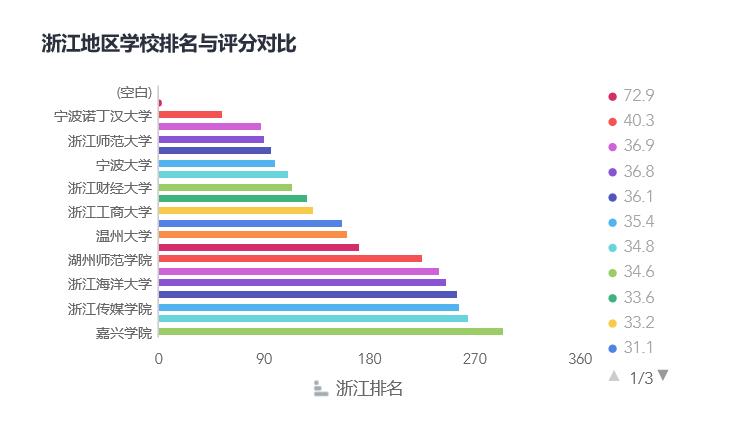
第四:数据可视化结果截图
第五:用同样方法做出所有所需要的表

长按二维码关注
如有任何问题
您可以发送邮件至
dataintellagr@126.com
或关注微博/知乎/微信后台留言
我们期待您的提问!
微博:数据智农
知乎:数据智农
邮箱:dataintellagr@126.com
制作:陈显蕊
推荐阅读
以上是关于数据可视化全国排名前300的学校地区分布可视化的主要内容,如果未能解决你的问题,请参考以下文章