小尝试:基于指标体系的数据仓库搭建和数据可视化
Posted 木东居士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小尝试:基于指标体系的数据仓库搭建和数据可视化相关的知识,希望对你有一定的参考价值。
小尝试:基于指标体系的数据仓库搭建和数据可视化
0x00 前言
我将整理文章分享数据工作中的经验,因为业务内容上的差异,可能导致大家的理解不一致,无法体会到场景中的诸多特殊性,不过相信不断的沟通和交流,可以解决很多问题。前面我们分析了职场基本功、数据指标体系,今天我们来就前面文章中的指标体系,聊一下数据仓库的搭建和数据可视化。
历史导读:
以下,Enjoy:
0x01 为什么基于指标体系搭建数据仓库
-
搭建指标体系实际上是同需求方达成一种协议,可以有效地遏止不靠谱的需求,让需求变得体系且有条理; -
数据指标体系是指导数据仓库搭建的基石,稳定且体系的数据需求,有利于数据仓库方案优化,效率提升。
没有数据指标体系的团队内数据需求经常表现为“膨胀”现象。每个人都有看数据的视角和诉求,然后以非专业的方式创造维度/指标的数据口径。数据从业人员被海量的数据需求缠住,很难抽离出业务规则设计好的解决方案,最终滚雪球似的搭建难以维护的“烟囱式”数据仓库。
0x02 基于指标体系搭建数据仓库思考
我们简单回忆下的数据仓库分层问题,做“又宽又薄”的数据仓库分层,让数据能够有序的流转。数据全链路的整个生命周期只有通过层次才能清洗明确的被使用者感知和消费。任何跨层依赖,循环依赖,多重依赖都会导致数据问题的多发且不可维护。
-
数据仓库常见分层方式
-
数据仓库分层和跨层依赖、循环依赖、多重依赖的不同表现形式
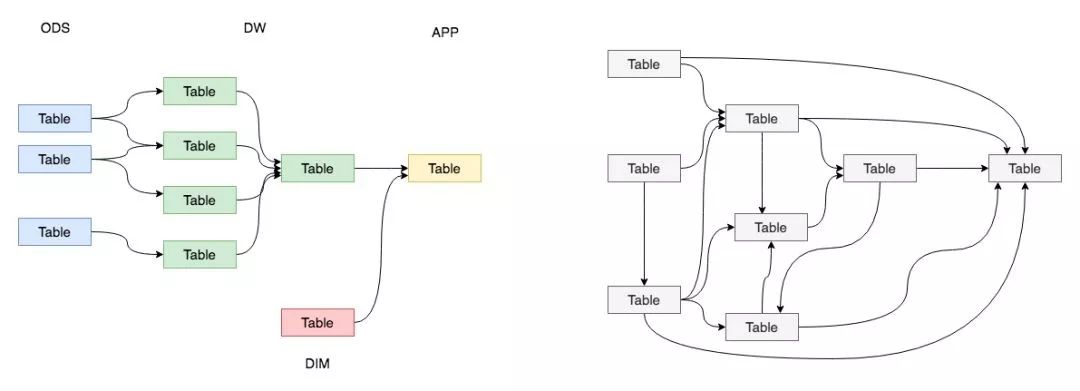
因此,我们需要有效的组织和管理数据,让它更有秩序。
-
每层都有作用域和职责,清晰每层数据的目标定位和理解。 -
规范工作方式,做标准数据分层,开发通用性强(健壮)的数据中间层,避免耦合重复计算问题。 -
提供统一的数据服务,输出统一认知的数据口径 -
将复杂的数据任务拆解,标准步骤每层解决场景问题。
从数据仓库的分层来看,ODS层是贴业务,形态主要依赖业务数据形式;APP层是贴使用场景,取决于数据怎么呈现和消费,DW层是中间层,负责发挥重要的扩展作用,肩负大量的数据加工计算责任。
鉴于以上数据仓库的分层逻辑,我们不难得出结论。
-
ODS层的搭建不需要过多思考,依赖业务库的表现形式; -
APP层的更多依赖数据最终的场景搭建,考虑场景因素居多,比如多维、速度、口径。
只有DW层让数据生产者有极大的发挥空间,如何设计出好的(扩展性强)DW层是数据仓库的重点标准,相信很多同学在DW层搭建的过程都出现过类似问题“理想很丰满,现实很残酷”,搭建的数据“不接地气,不实用”,还是不能解决数据需求问题,总是跟不上业务的发展变幻。
那么,从现在开始不妨首先建立指标体系,基于指标体系搭建数据仓库。我们常见的指标体系大致包含以下内容:
-
产品框架
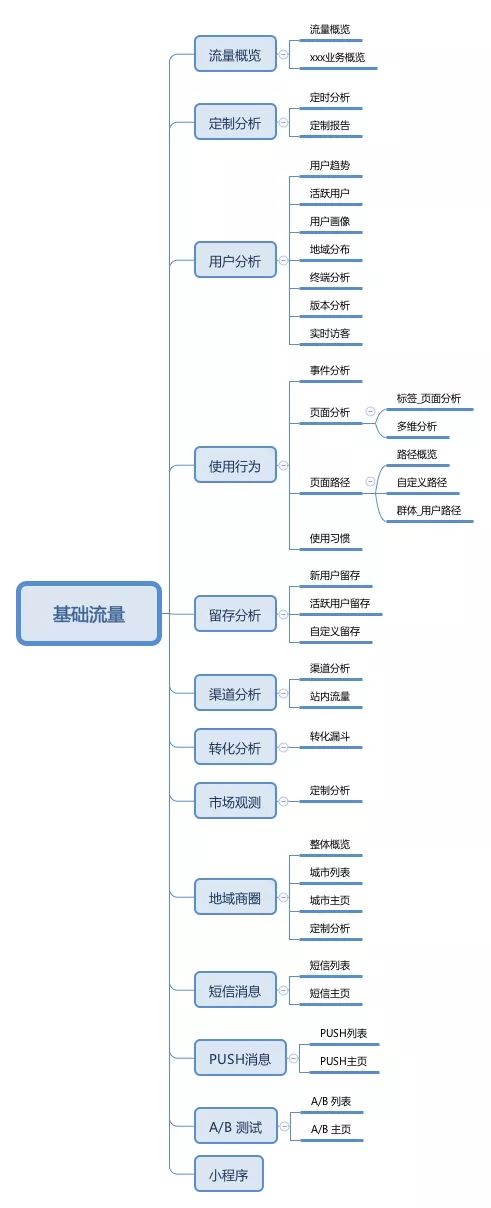
-
数据矩阵
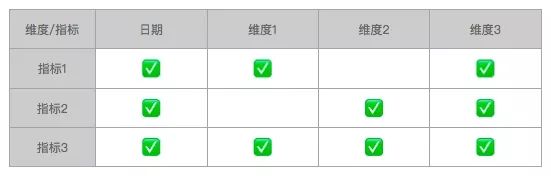
说明:
根据产品框架梳理出可靠的数据矩阵效果最佳,单现实的情况是在产品框架下的不同报表的指标口径或是计算逻辑可能存在差异,因此数据矩阵可以是根据某个报表单独针对性小矩阵。
-
数据口径
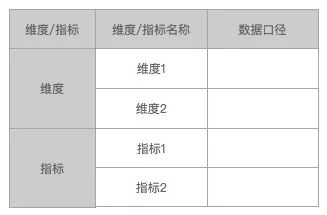
说明:同数据矩阵一样不同的数据报表中,相同的指标名称可能存在不同的数据口径或者计算逻辑 ,因此指标的口径定义方面也可以做一些调整,例如口径和计算逻辑不同,必须区分出不同的指标名称,或者是相同的指标名称,做好指标口径定义的说明,告知受众群体差异点在哪里。
0x03 基于指标体系搭建数据仓库
常见的数据仓库搭建,实现数据分层大致分为两种模式:
-
A模式:基于业务实体或者数据的应用场景,从应用层向底层推导过程。 -
B模式:基于已有的数据,从底层分类整理数据,向应用层逐步搭建。
以底层向应用层搭建数据仓库,侧重在于需求尚且不清晰的情形下开展数据开发工作,首先实现数据预处理,做好数据的采集对接和数据主题分类。以备数据消费场景落地的时候,快速实现功能的开发。这种模式通用型强,使用广泛,同时也会造成很多冗余和设计不合理,实际响应需求的时候出现扩展性差,重构几率高的现象。
另一种模式则是在需求明确的前提下,以需求向底层推导数据仓库建模。通过需求让参与项目的各方快速理解业务诉求,统一目标的认知。高质量的梳理出业务需求和数据仓库之间的关系,针对性强的搭建数据仓库。但是这依然有诟病,就是数据建设容易出现“烟囱式”搭建,满足场景有限,复用性差。
基于指标体系搭建数据仓库,主要解决的是“A模式”中的数据场景考虑不全面的问题。如果数据的使用场景考虑不全面就会造成“烟囱式”数据搭建,复用性差。数据需求如果以“点状”碎片的形式提出,没有全局的认知和规划,数据仓库的搭建只能针对性的以“点状的烟囱式”搭建。如果需求能体系化的产出,梳理出业务场景中所需要的维度、指标。那么就可以最大限度的解决数据建模过程中的“烟囱式”,从而让数据的搭建“又宽又薄”。
例如,我们有如下数据矩阵

那么,我们可以选择的数据仓库分层建模方式如下

说明库.表1:通过APP层的数据表服务数据可视化,数据应用服务,多维查询;库.表2:实时明细表,通过与其他的实时表(库.表3)或者维度表(库.表4、5)关联生成APP层的数据表;库.表6:埋点数据产生的日志表,或者是从业务库对接过来的业务数据(比如订单数据)
0x04 数据可视化报表
当然,理想很丰满现实很残酷,正如我几次提到实际工作存在很多不理想,这是很多人遇到的问题,我也在探索新的方式,如果大家有兴趣可以加入微信群一起交流。
小姬的系列文章:
热门文章
以上是关于小尝试:基于指标体系的数据仓库搭建和数据可视化的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop 和 BI 如何结合?搭建一个基于 Hadoop+Hive 的数据仓库,它的前端展现如何实现?如何实现 BI?