「R」数据可视化15:倾斜图
Posted 优雅R
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「R」数据可视化15:倾斜图相关的知识,希望对你有一定的参考价值。
“今年注定是个与众不同的春节,因为武汉肺炎病毒,整个中国都有些不太平。但是,过去几十年中国曾克服过很多困难,相信这一次,也一定会平安渡过。不仅因为我们比过去更加强大了,也因为在强大的过程中我们依然心连心甚至因为信息网络变得更加紧密。
什么是倾斜图(Slope Graph)
倾斜图,又名斜线图、斜率图,可以展示单指标不同时期的变化情况,既能展示值的大小变化,同时能展示排名变化。倾斜图可以看作简化后的折线图,如果我们对一条线如何发展的细节不感兴趣,而只想看看它沿哪个方向发展,那么斜率图就是一个不错的选择。尤其如果我们有很多折线,它们通常看上去没有普通的折线图那么混乱。以下是两个倾斜图的例子:
左边的图统计了农场动物从2005年到2015年数量的变化,右边的图是2000年到2013年的移民居住情况。可以看到倾斜图能够非常直观体现出变化情况,如左图中,通过颜色等可以明显发现狗和猫的数量明显下降。在生物医学方面,倾斜图我们可以用于表示不同时间点不同指标或者不同时间点同一指标不同个体的变化情况等,以更加直观体现出变化趋势。那么要怎么做倾斜图呢?
怎么做倾斜图
有多种方法可以做倾斜图,最简单的用ggplot2就可以,当然也可以用专门做倾斜图的包比如CGPfuncitons。具体专用包比较好用一个函数就可以搞定,所以就只介绍最常见的方法使用ggplot2进行作图方法:
1)需要什么格式的数据
目前疫情地图实时更新,所以这次就正好用公开的疫情数据做一次倾斜图。因为2020年1月20日,钟南山院士在发布会上正式确定武汉肺炎病毒可以人传人,所以取了1月20日的确定感染人数的数据(截至24:00)和今天1月25日(截至16:27)的确定感染人数数据。按照1月25日公布的数据,只选取了前10个省份,做了如下的数据表:
Day0120<-c(270,5,14,2,0,0,0,0,0,0)
Day0125<-c(729,36,78,33,62,57,43,39,32,28)
Province<-c("Hubei","Beijing","Guangdong","Shanghai","Zhejiang","Chongqing","Hunan","Anhui","Henan","Sichuan")
a<-data.frame(Day0120,Day0125,Province)
a$Province<-factor(Province)
a
Day0120 Day0125 Province
1 270 729 Hubei
2 5 36 Beijing
3 14 78 Guangdong
4 2 33 Shanghai
5 0 62 Zhejiang
6 0 57 Chongqing
7 0 43 Hunan
8 0 39 Anhui
9 0 32 Henan
10 0 28 Sichuan
(2)如何使用ggplot2做倾斜图
library(ggplot2)
library(RColorBrewer)
#x是我随意取的
p<-ggplot(a) +
geom_segment(aes(x=0,xend=3,y=Day0120,yend=Day0125,color=Province),size=.5)+
geom_point(aes(x=0,y=a$Day0120,color=Province))+
geom_point(aes(x=3,y=a$Day0125,color=Province))+
theme_bw()+
theme(
panel.background = element_blank(),
panel.grid=element_blank(),
axis.ticks.x=element_blank(),
axis.text.x=element_blank(),
panel.border=element_blank(),
legend.position = c("none")
)+
scale_x_continuous(limits = c(0,4),breaks=c(0,3))+
scale_y_continuous(limits = c(0,800),breaks=c(0,150,300,450,600,750))+
scale_color_brewer(palette = "Paired")+
xlab("") +
ylab("The Number of Confirmed")+
geom_text(label=a$Province, y=a$Day0125, x=3,hjust=0,size=3)+
geom_text(label="01/20 24:00", x=0, y=(1.1*(max(a$Day0120,a$Day0125))),hjust= 0.5,size=3)+
geom_text(label="01/25 16:27", x=3, y=(1.1*(max(a$Day0120,a$Day0125))),hjust= 0.5,size=3)
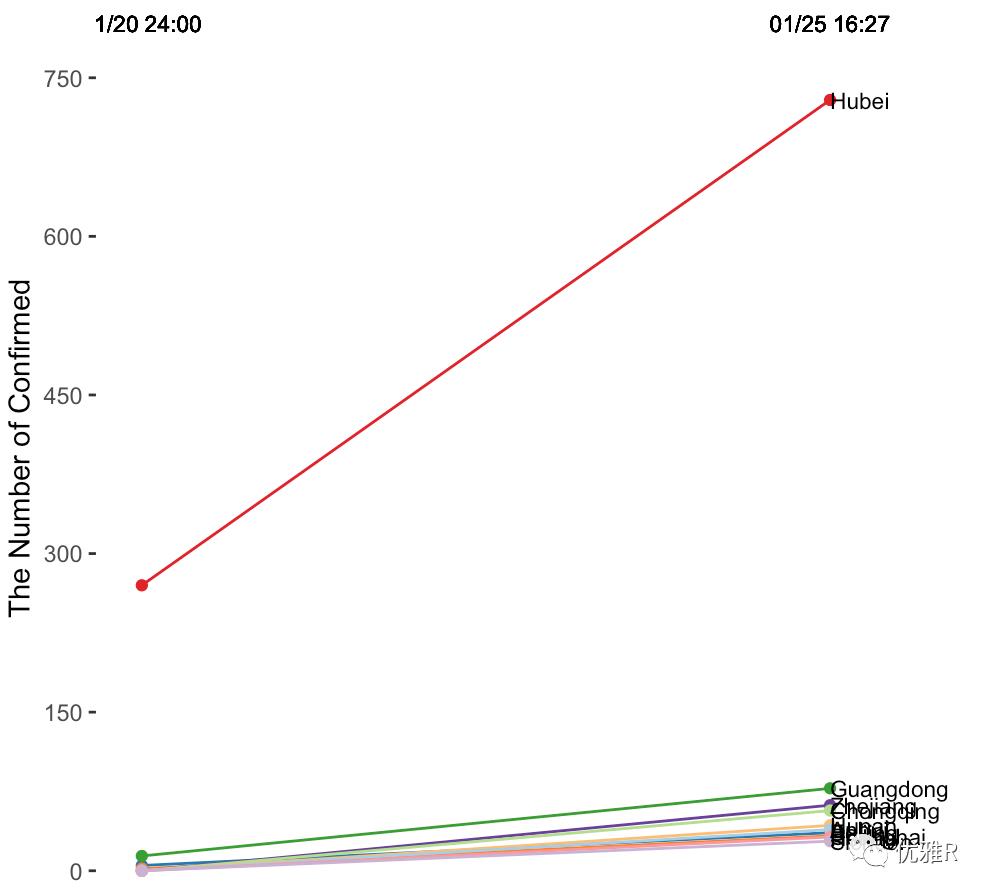
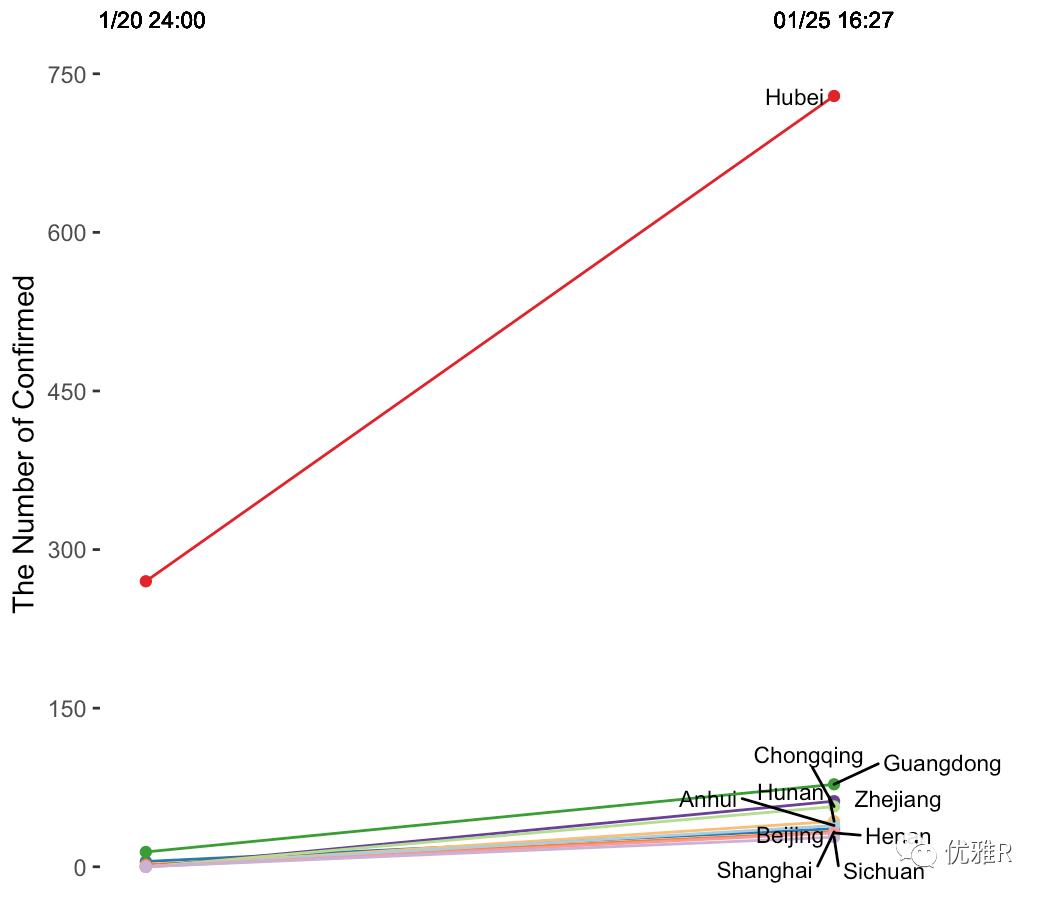
由于湖北省的人数过高,可以看到下面的省份都挤在了一起,这时候可以考虑使用ggrepel将文字区分开,或者是有AI等工具调试会比较方便。如果使用ggrepel包只需要将geom_text(label=a$Province, y=a$Day0125, x=3,hjust=0,size=3)替换为geom_text_repel(label=a$Province, y=a$Day0125, x=3,hjust=0,size=3)
因为湖北是疫情的源头,那么其他省份的情况究竟如何呢?我们可以把湖北省去掉,重新作图:
a<-a[2:9,]
p2<-ggplot(a) +
geom_segment(aes(x=0,xend=3,y=Day0120,yend=Day0125,color=Province),size=.5)+
geom_point(aes(x=0,y=a$Day0120,color=Province))+
geom_point(aes(x=3,y=a$Day0125,color=Province))+
#theme_bw()+
theme(
panel.background = element_blank(),
panel.grid=element_blank(),
axis.ticks.x=element_blank(),
axis.text.x=element_blank(),
panel.border=element_blank(),
legend.position = c("none")
)+
scale_x_continuous(limits = c(0,4),breaks=c(0,3))+
scale_y_continuous(limits = c(0,90),breaks=c(0,20,40,60,80))+
scale_color_brewer(palette = "Paired")+
xlab("") +
ylab("The Number of Confirmed")+
geom_text(label=a$Province, y=a$Day0125, x=3,hjust=-0.15,size=2.5)+
geom_text(label="01/20 24:00", x=0, y=(1.1*(max(a$Day0120,a$Day0125))),hjust= 0.25,size=3)+
geom_text(label="01/25 16:27", x=3, y=(1.1*(max(a$Day0120,a$Day0125))),hjust= 0.25,size=3)
p2
所以可以看到广东、浙江、重庆几个省份是增长比较快的。当然,针对图可以再做一些美化,不过个人觉得可以直接在AI软件中调试,这样会更方便一些,所以本次就偷懒了~
最后希望疫情赶快控制住!加油!
“本文作者蒋刘一琦,自嘲是一个有艺术追求的生信狗,毕业于浙江大学生物信息学专业,目前在复旦大学就读研究生,研究方向为宏基因组。
编辑:王诗翔
往期精彩:
欢迎大家投稿(Markdown文件)至 w_shixiang@163.com,内容包括但不仅限于R语言编程、统计算法、生物统计、可视化、生信软件包等。
以上是关于「R」数据可视化15:倾斜图的主要内容,如果未能解决你的问题,请参考以下文章