统计关系的数据可视化
Posted 老坛学Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统计关系的数据可视化相关的知识,希望对你有一定的参考价值。
今日主题:seaborn库中可视化数据关系的实践操作,请relplot()上台表演。
数据可视化的意义
每一天我们都会获得到各种各样的数据,为了问题的解决,我们需要适当的做一些数据的分析,其中最直观的方式就是绘图,通过将数据转变为图表,我们能发现一些趋势,找到数据之间相互关系,从而制定合理的方案进行问题的解决。下面我们依次耍耍scatterplot()、lineplot()和relplot()这三个函数。
库导入与数据准备
玩耍中使用的是iris数据集,这个数据集一共有5个变量,分别是sepal_length(花萼长度)、sepal_width(花萼宽度)、petal_length(花瓣长度)、petal_width(花瓣宽度)、species(花种类)。
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdiris = pd.read_csv('iris.csv', encoding='utf8')

前面两步就用复制粘贴带过了。
下面直接进入正题。
relplot()
这个函数的初始化需要传入这些参数:
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None,data=None, row=None, col=None, col_wrap=None, row_order=None,col_order=None, palette=None, hue_order=None, hue_norm=None,sizes=None, size_order=None, size_norm=None, markers=None,dashes=None, style_order=None, legend='brief', kind='scatter',height=5, aspect=1, facet_kws=None, **kwargs)

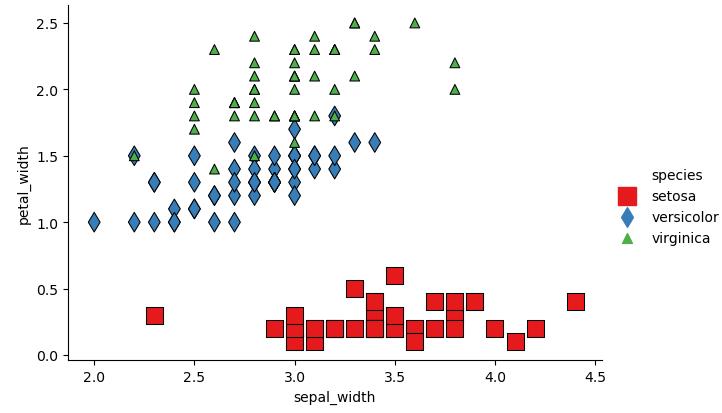
g = sns.relplot(x='sepal_width', y='petal_width', hue='species', data=iris,kind='scatter', palette='Set1', size='species', sizes=(50, 150),style='species', markers=['s', 'd', '^'], height=4, aspect=1.5, edgecolor='black')plt.show()
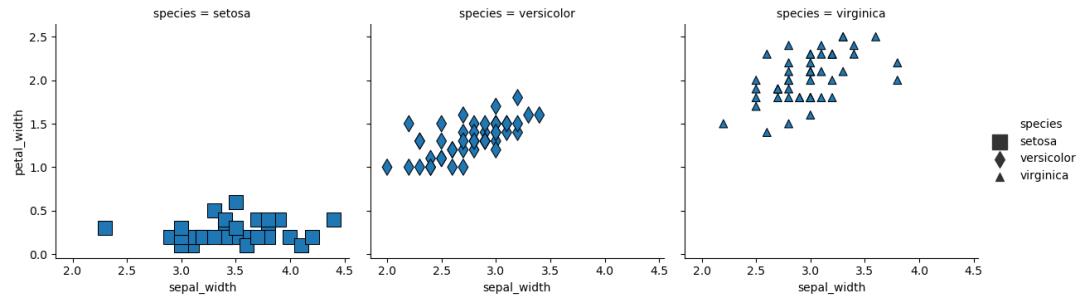
g = sns.relplot(x='sepal_width', y='petal_width', col='species', data=iris,kind='scatter', size='species', sizes=(50, 150),style='species', markers=['s', 'd', '^'],height=4, aspect=1, edgecolor='black')plt.show()
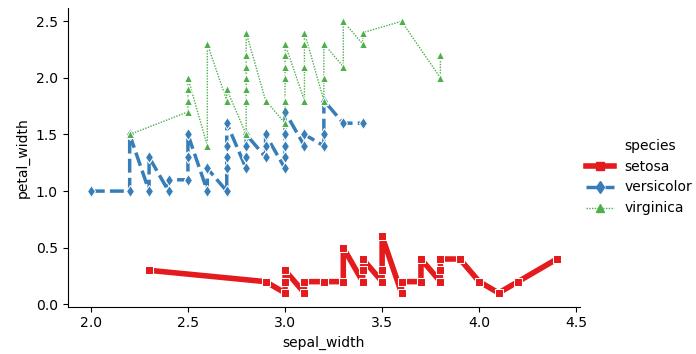
g = sns.relplot(x='sepal_width', y='petal_width', hue='species', data=iris,kind='line', palette='Set1', size='species',sizes=(1, 4), style='species', markers=['s', 'd', '^'],height=4, aspect=1.5, estimator=None)plt.show()
参数设置的含义之前的文章讲过了,这儿就不再写了。
— E N D —
长
按
关
注
“像海绵吸水一样学习知识”
ID : 老坛学Python
记录·分享·成长

点“在看”给我一朵小黄花
以上是关于统计关系的数据可视化的主要内容,如果未能解决你的问题,请参考以下文章
数据可视化应用数据统计分析的显著性标注(附Python和R语言代码)