适用于Windows,Ruby,Cucumber和Capybara的无忧启动指南
Posted 京鸿智武
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了适用于Windows,Ruby,Cucumber和Capybara的无忧启动指南相关的知识,希望对你有一定的参考价值。
大纲
我通常使用Selenium Webdriver进行Web测试自动化项目。这是一个非常有名的框架。它有一个非常大的社区和支持,所以当你遇到困难时,你可以轻松找到解决方案。另一方面,我的一些朋友是Ruby的大粉丝测试。我还参加了一些Ruby测试研讨会,看到了它的特性和功能。在我看来,Ruby有一个非常干净的编码语法,很容易学习。它不需要在其图书馆自动化太多的精力,例如水豚驱动的Web应用程序,RESTClient实现用于与Web服务交互的SitePrism for POM(页面对象模型)。
在这篇文章中,我将解释如何安装和设置Ruby,水豚和黄瓜。这是Ruby测试初学者的快速入门教程。首先,让我们从定义开始。
什么是水豚?
在Capybara的官方网页上,它被描述如下:“ Capybara是用Ruby编程语言编写的库,可以很容易地模拟用户如何与你的应用程序交互。水豚可以与许多不同的驱动程序通过相同的干净和简单的界面执行您的测试。您可以在Selenium,Webkit或纯Ruby驱动程序之间进行无缝选择。水豚自动等待你的内容出现在页面上,你永远不必发出任何手动睡觉。“
样本水豚特点:
1 2 3 4 5 |
When /^I login with "(.*?)" username and "(.*?)" password$/ do |user, password| fill_in 'username', :with =>; user fill_in 'password', :with =>; password click_button 'Login' end |
什么是黄瓜?
Cucumber是编写和执行软件功能的高级描述的框架。它支持行为驱动开发(BDD)。它提供了一种编写任何人都可以理解的测试的方法,而不管他们的技术知识如何。黄瓜认识的语言叫做小黄瓜。Cucumber本身是用Ruby编写的,但它可以用来“测试”用Ruby或其他语言编写的代码,包括但不限于Java,C#和Python。
一个黄瓜脚本的例子:
1 2 3 4 5 6 7 |
Scenario: Filter the television list Given some different televisions in the TV listing page When I visit the TV listing page And I search for "Samsung" TVs Then I only see titles matching with Samsung TVs When I erase the search term Then I see all television brands again |
安装和设置
第一步:安装Ruby
>>对于Windows,安装Ruby的最佳位置是http://rubyinstaller.org/downloads/。去那个网站,安装最新的32位版本的Ruby。
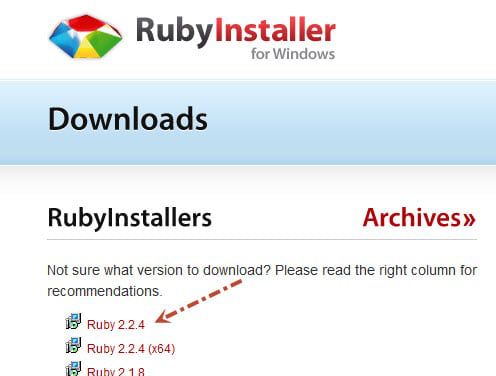
注意:64位版本的Ruby在Windows领域是相对较新的,并不是所有的软件包都被更新为兼容。
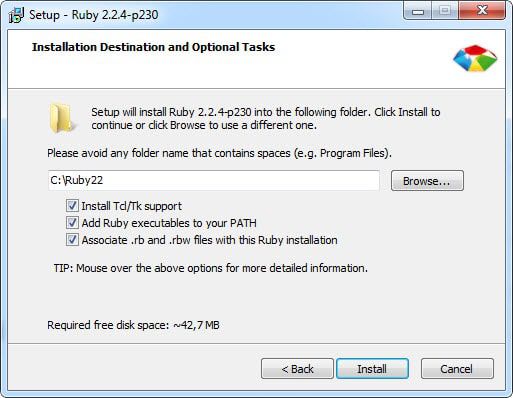
>>在这篇文章中,我将使用Ruby 2.2.4版本,并在安装过程中选择以下选项。确保选中“ 将Ruby可执行文件添加到PATH ”选项。”
>> 使用ruby -v命令检查Ruby安装。你会看到如下所示的Ruby版本。

>> 通过在命令行上运行gem -v来检查RubyGems的安装。RubyGems是Ruby的包管理器,应该随标准的Ruby安装一起提供。

第2步:安装Ruby开发工具包
>>在同一页面下载Ruby开发工具包。它将允许Ruby构建库的本地扩展。
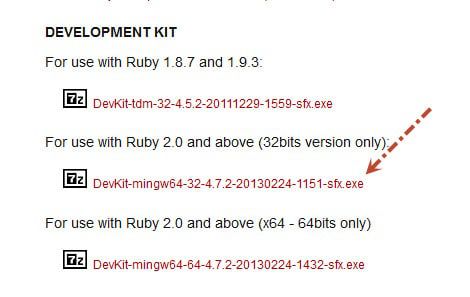
>>将其解压到C:\ DevKit文件夹中。
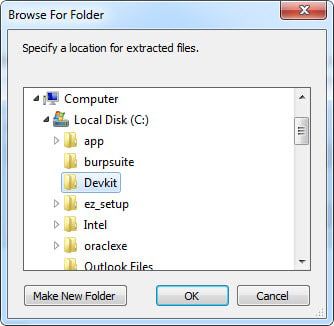
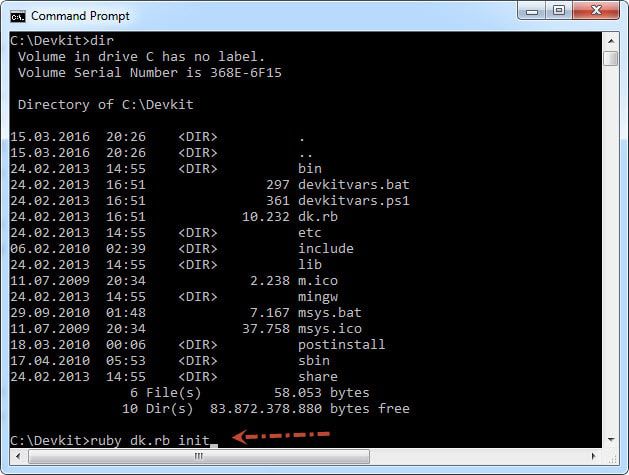
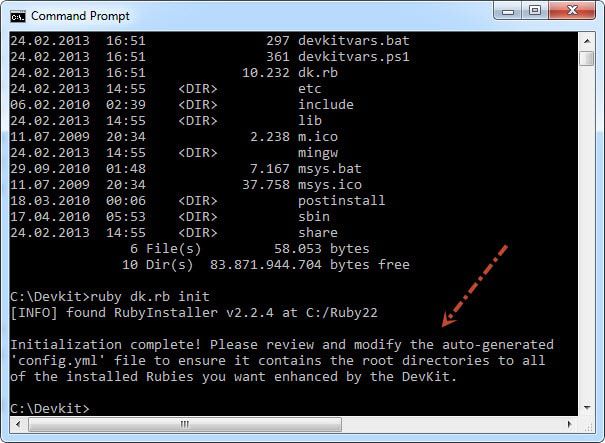
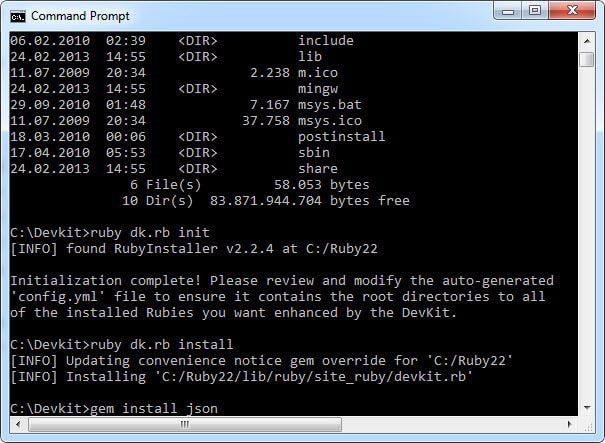
>>打开命令提示符,进入C:/ DevKit文件夹,运行ruby dk.rb init命令,生成稍后使用的config.yml文件。
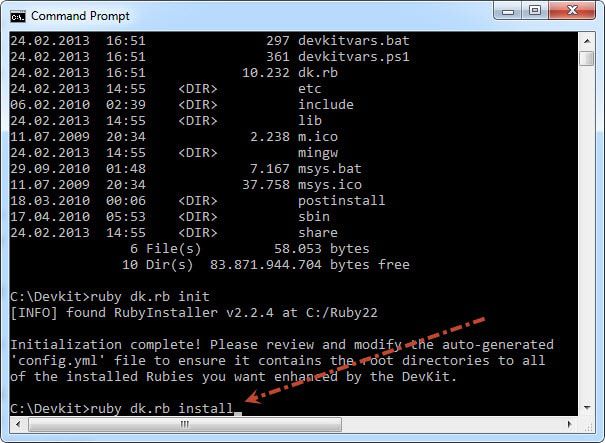
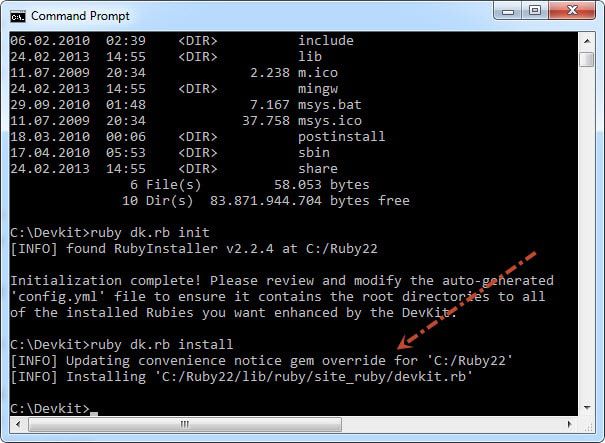
>>运行ruby dk.rb install这一步将一个operating_system.rb文件安装(或更新)到实现RubyGems pre_install钩子和devkit.rb辅助程序库文件到<RUBY_INSTALL_DIR> \ lib \ ruby \ site_ruby 所需的相关目录中。
>>为了测试你的安装,运行下面的命令。
gem install json -platform = ruby
如果JSON安装正确,您应该看到下面的屏幕。
第三步:安装黄瓜
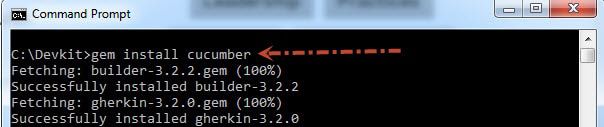
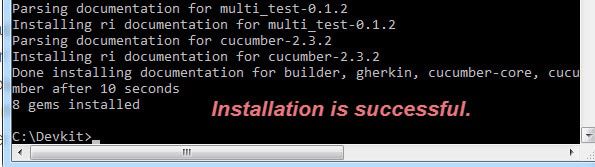
>>运行gem install cucumber命令自动下载并安装Cucumber。安装完成后,运行cucumber -help命令确认安装成功。
第四步:安装水豚
>>运行gem install capybara来下载并安装Capybara网页自动化库。
第5步:安装Selenium Webdriver
>>运行gem install selenium-webdriver来下载并安装Selenium网页自动化框架。
第6步:安装RSpec
>>运行gem install rspec下载并安装RSpec。这是一个广泛的断言库。(顺便说一句,在codeschool.com有一个非常好的教程,它的名字是“RSpec测试”,我建议你检查课程。)
第七步:安装Ansicon(可选)
如果要在运行黄瓜功能时着色命令提示符,则需要安装ANSICON,因为Windows不理解ANSI颜色转义序列。
· 为了下载最新版本的ANSICON,请访问https://github.com/adoxa/ansicon/downloads。
· 创建C:\ Ansicon目录并将下载文件解压缩到其中。
· 打开命令提示符并导航到C:\ Ansicon文件夹。
· 如果您的机器是64位,请导航到X64文件夹,否则请转到X86文件夹。
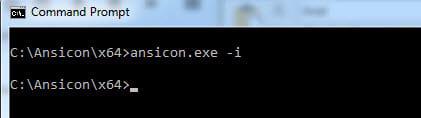
· 执行“ ansicon.exe -i ”来安装和添加ANSICON到你的Windows。
用Ruby&水豚和黄瓜开始自动化
>>首先,我们需要创建一个功能目录。我们将所有功能文件添加到此文件夹。
功能文件应该用黄瓜语法(Given-When-Then)编写。小黄瓜是一种特定于领域的语言(DSL),它可以让你描述软件的行为,而不用详细说明如何实现这个行为。
每个场景最多可以有三个部分:Givens,Whens和Thens:
· 给定 - 给定的行描述了什么前提条件应该存在。
· 何时 - 行描述您采取的行动。
· 然后 - 线条描述结果。
还有And行,可以做任何上面的行。例如:
1 2 3 4 |
Given I am on the product page And I am logged in Then I should see "Welcome!" And I should see "Personal Details" |
在这种情况下,第一行和第一行作为给定行,第二行作为第二行。
>>进入功能文件夹并创建test.feature文件。我们的测试场景是:
· 转到www.google.co.uk
· 搜索雅虎
· 在搜索结果中查看雅虎
· 点击雅虎链接
· 等待10秒钟
>>现在,用notepad ++或其他文本编辑器打开test.features文件,并将上面的测试场景写成Gherkin语法。
1 2 3 4 5 6 7 |
Feature: Find the Yahoo Website Scenario: Search a website in google Given I am on the Google homepage When I will search for "yahoo" Then I should see "yahoo" Then I will click the yahoo link Then I will wait for 10 seconds |
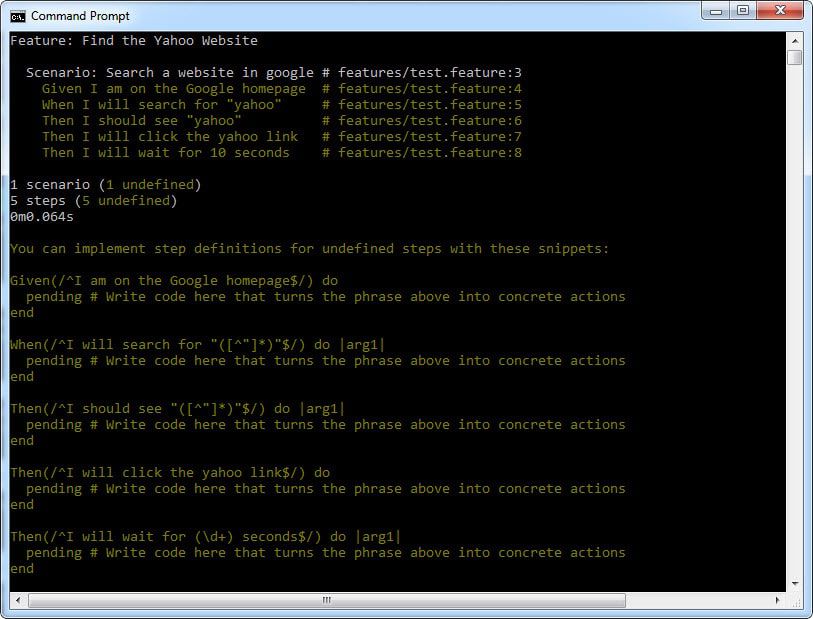
>>编写特征文件后,尝试使用以下命令运行测试。
黄瓜功能\ test.feature
我们还没有定义测试步骤。因此,测试执行后我们会得到下面的结果。
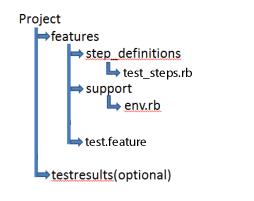
>>为了准备步骤定义文件,首先在features文件夹中创建一个名为step_definitions的文件夹,然后创建test_steps.rb文件。目录结构应该是这样的:
>>您可以复制测试结果的代码片段并粘贴到test_steps.rb文件中。现在,我们可以编写测试步骤。我想告诉你如何做,一步一步。
步骤1:首先,我们需要导航到google.co.uk网站。水豚提供此功能的访问方法。在Selenium中,我们可以使用driver.get()或driver.navigate()。()方法来实现。所以,我们应该添加下面的行去google.co.uk。
1 |
visit 'http://www.google.co.uk' |
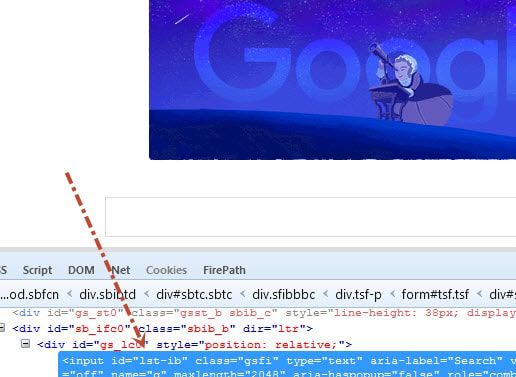
第二步:完成上述操作后,我们进入google.co.uk页面,现在是时候将搜索文本写入搜索栏。如下图所示,搜索栏的ID是“lst-ib ”。
水豚为我们提供fill_in方法进行文本入口操作。我们可以用下面的方法做这个操作。在硒,我们可以做到这一点textElement.sendKeys(字符串)会见 HOD。
1 |
fill_in 'lst-ib', :with => searchText |
第三步:然后,我们需要检查当前页面上的预期搜索结果。要做到这一点,我们可以使用page.should have_content方法。在Selenium中,我们可以用Junit,TestNG或Hamcrest断言来做到这一点。例如,assertThat(element.getText(),containsString(“yahoo”));
1 |
page.should have_content(expectedText) |
第四步:然后,点击雅虎链接。如下图所示,链接文字是“ 雅虎 ”。
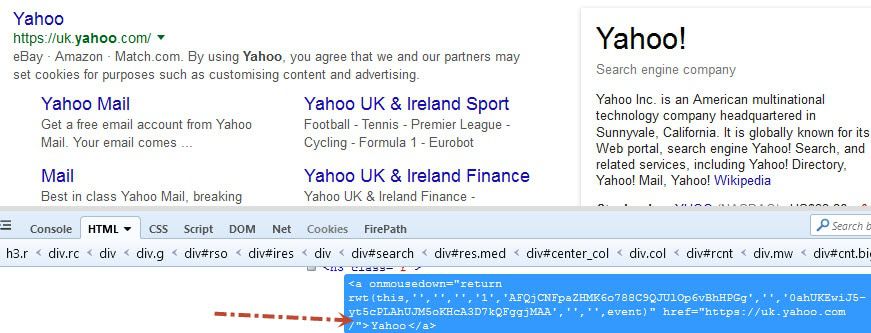
在水豚,我们可以使用click_link方法来做到这一点。在Selenium中,我们可以通过driver.findElement(By.linkText(“Yahoo”))来实现。
1 |
click_link('Yahoo') |
第五步:在最后一步,我们会静静地等待10秒,看看雅虎网站。要做到这一点,我们可以使用sleep(10)方法。在Selenium中,我们使用Thread.sleep(10000);
现在是把它们放在一起的时候了。我们的test_steps.rb代码如下所示。
test_steps.rb
Ruby
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#Navigate to google.co.uk Given(/^I am on the Google homepage$/) do visit 'https://www.google.co.uk/' end
#Write "yahoo" search text to the search bar When(/^I will search for "([fusion_builder_container hundred_percent="yes" overflow="visible"][fusion_builder_row][fusion_builder_column type="1_1" background_position="left top" background_color="" border_size="" border_color="" border_style="solid" spacing="yes" background_image="" background_repeat="no-repeat" padding="" margin_top="0px" margin_bottom="0px" class="" id="" animation_type="" animation_speed="0.3" animation_direction="left" hide_on_mobile="no" center_content="no" min_height="none"][^"]*)"$/) do |searchText| fill_in 'lst-ib', :with => searchText end
#In the current page, we should see "yahoo" text Then(/^I should see "([^"]*)"$/) do |expectedText| page.should have_content(expectedText) end
#Click the yahoo link Then(/^I will click the yahoo link$/) do click_link('Yahoo') end
#Wait 10 seconds statically to see yahoo website Then(/^I will wait for (\d+) seconds$/) do |waitTime| sleep (waitTime.to_i) end |
>>编写步骤定义之后,创建支持文件夹到要素文件夹中,并为环境设置创建一个env.rb文件。然后,将以下环境设置复制并粘贴到该文件中并保存。我从参考-3得到了这个设置。
env.rb
Ruby
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
require 'rubygems' require 'capybara' require 'capybara/dsl' require 'rspec'
Capybara.run_server = false #Set default driver as Selenium Capybara.default_driver = :selenium #Set default selector as css Capybara.default_selector = :css
#Syncronization related settings module Helpers def without_resynchronize page.driver.options[:resynchronize] = false yield page.driver.options[:resynchronize] = true end end World(Capybara::DSL, Helpers) |
>>最后,我们准备好运行我们的功能文件。首先,进入你的项目目录。它包含如下所示的功能文件夹。
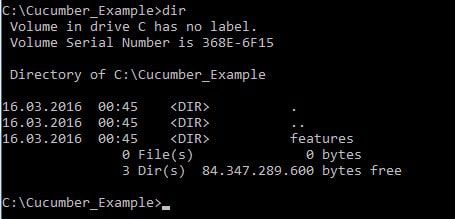
然后,运行下面的命令。
黄瓜功能\ test.feature

而且,喜欢看测试执行
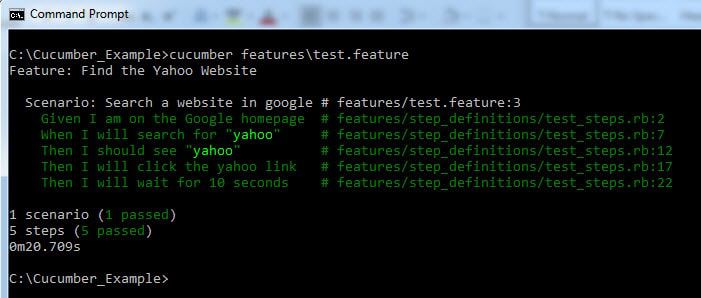
结论
在本文中,我想用Ruby,Cucumber和Capybara来描述测试自动化的第一步。我希望你们在这些指示中也是成功的。这篇文章只是这个话题的开始。你应该做更多的参考和官方网页的研究,以提高你的测试自动化技能和Ruby,黄瓜和水豚的知识。 如果您想提出更多的问题,请不要犹豫在评论部分写下您的意见。感谢您阅读我的文章。快乐的测试!
京鸿智武
让智慧和技能成就你我
点击阅读原文,了解更多精彩内容
以上是关于适用于Windows,Ruby,Cucumber和Capybara的无忧启动指南的主要内容,如果未能解决你的问题,请参考以下文章