Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
Posted 大数据学习与分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark在处理数据的时候,会将数据都加载到内存再做处理吗?相关的知识,希望对你有一定的参考价值。
对于Spark的初学者,往往会有一个疑问:Spark(如SparkRDD、SparkSQL)在处理数据的时候,会将数据都加载到内存再做处理吗?
很显然,答案是否定的!
对该问题产生疑问的根源还是对Spark计算模型理解不透彻。
对于Spark RDD,它是一个分布式的弹性数据集,不真正存储数据。如果你没有在代码中调用persist或者cache算子,Spark是不会真正将数据都放到内存里的。
此外,还要考虑persist/cache的缓存级别,以及对什么进行缓存(比如是对整张表生成的DataSet缓存还是列裁剪之后生成的DataSet缓存)(关于Spark RDD的特性解析参考
既然Spark RDD不存储数据,那么它内部是如何读取数据的呢?其实Spark内部也实现了一套存储系统:BlockManager。为了更深刻的理解Spark RDD数据的处理流程,先抛开BlockManager本身原理,从源码角度阐述RDD内部函数的迭代体系。
我们都知道RDD算子最终会被转化为shuffle map task和result task,这些task通过调用RDD的iterator方法获取对应partition数据,而这个iterator方法又会逐层调用父RDD的iterator方法获取数据(通过重写scala.collection.iterator的hasNext和next方法实现)。主要过程如下:
首先看ShuffleMapTask和ResultTask中runTask方法的源码:
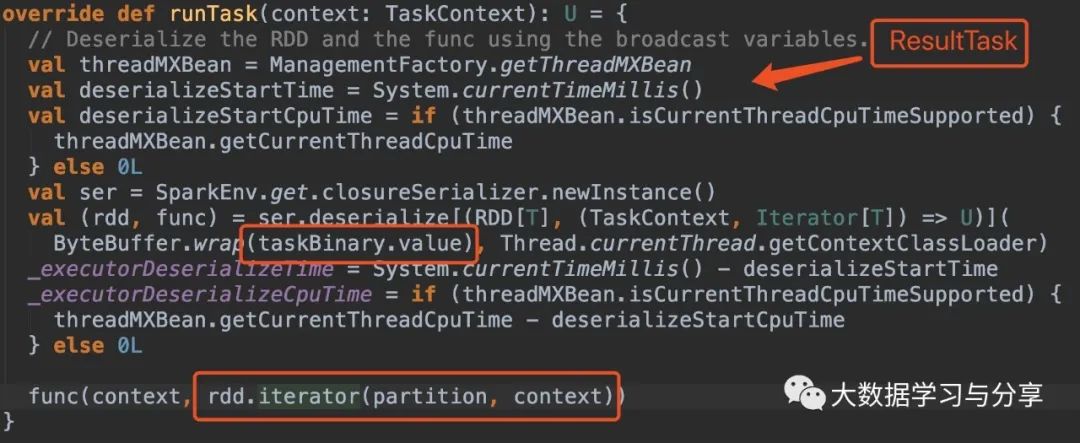
关键看这部分处理逻辑:
rdd.iterator(partition, context)
getOrCompute方法会先通过当前executor上的BlockManager获取指定blockId的block,如果block不存在则调用computeOrReadCheckpoint,如果要处理的RDD没有被checkpoint或者materialized,则接着调用compute方法进行计算。
compute方法是RDD的抽象方法,由继承RDD的子类具体实现。
以WordCount为例:
sc.textFile(input)
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile(output)
textFile会构建一个HadoopRDD
flatMap/map会构建一个MapPartitionsRDD
reduceByKey触发shuffle时会构建一个ShuffledRDD
saveAsTextFile作为action算子会触发整个任务的执行
以flatMap/map产生的MapPartitionsRDD实现的compute方法为例:
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
底层调用了parent RDD的iterator方法,然后作为参数传入到了当前的MapPartitionsRDD。而f函数就是对parent RDD的iterator调用了相同的map类函数以执行用户给定的函数。
所以,这是一个逐层嵌套的rdd.iterator方法调用,子RDD调用父RDD的iterator方法并在其结果之上调用Iterator的map函数以执行用户给定的函数,逐层调用直到调用到最初的iterator(比如上述WordCount示例中HadoopRDD partition的iterator)。
而scala.collection.Iterator的map/flatMap方法返回的Iterator就是基于当前Iterator重写了next和hasNext方法的Iterator实例。比如,对于map函数,结果Iterator的hasNext就是直接调用了self iterator的hasNext,next方法就是在self iterator的next方法的结果上调用了指定的map函数。
flatMap和filter函数稍微复杂些,但本质上一样,都是通过调用self iterator的hasNext和next方法对数据进行遍历和处理。
所以,当我们调用最终结果iterator的hasNext和next方法进行遍历时,每遍历一个数据元素都会逐层调用父层iterator的hasNext和next方法。各层的map函数组成一个pipeline,每个数据元素都经过这个pipeline的处理得到最终结果。
这也是Spark的优势之一,map类算子整个形成类似流式处理的pipeline管道,一条数据被该链条上的各个RDD所包裹的函数处理。
再回到WordCount例子。HadoopRDD直接跟数据源关联,内存中存储多少数据跟读取文件的buffer和该RDD的分区数相关(比如buffer*partitionNum,当然这是一个理论值),saveAsTextFile与此类似。MapPartitionsRDD里实际在内存里的数据也跟partition数有关系。ShuffledRDD稍微复杂些,因为牵扯到shuffle,但是RDD本身的特性仍然满足(记录文件的存储位置)。
说完了Spark RDD,再来看另一个问题:Spark SQL对于多表之间join操作,会先把所有表中数据加载到内存再做处理吗?
当然,肯定也不需要!
推荐文章:
以上是关于Spark在处理数据的时候,会将数据都加载到内存再做处理吗?的主要内容,如果未能解决你的问题,请参考以下文章