开窗函数之累积和,PySpark,Pandas和SQL版实现
Posted 数据思维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开窗函数之累积和,PySpark,Pandas和SQL版实现相关的知识,希望对你有一定的参考价值。
之前写过一篇,想更多了解开窗(窗口)函数,可以看看那篇文章。
今天主要是结合Pandas, Koalas和PySpark来介绍下开窗函数的累积和。
测试环境
Jupyter Notebook
iPython-sql
PySpark 3.0
Koalas
Pandas
名词解释
累积和(Cumulative Sum,CUSUM)是一种序贯分析法,由剑桥大学的 E. S. Page 于1954年首先提出。
累积和用以在某个相对稳定的数据序列中,检测出开始发生异常的数据点。所谓异常的数据点,比如说,从这点开始,整个数列的平均值或者均方差开始发生改变,进而影响到整组数据的稳定。所以累积和最典型的应用是在“改变检测”(Change Detection)中对参量变化的检测。由于累积和管制法能充分利用数据变化之顺序与大小,故相当适合用于侦测制程的微量变化(small shifts)
维基百科
测试数据
%%writefile winsales.csvsalesid,dateid,sellerid,buyerid,qty,qty_shipped30001, '8/2/2003', 3, 'b', 10, 1010001, '12/24/2003', 1, 'c', 10, 1010005, '12/24/2003', 1, 'a', 30,40001, '1/9/2004', 4, 'a', 40,10006, '1/18/2004', 1, 'c', 10,20001, '2/12/2004', 2, 'b', 20, 2040005, '2/12/2004', 4, 'a', 10, 1020002, '2/16/2004', 2, 'c', 20, 2030003, '4/18/2004', 3, 'b', 15,30004, '4/18/2004', 3, 'b', 20,30007, '9/7/2004', 3, 'c', 30,
把测试数据保存为winsales.csv
Pandas数据读取
import pandas as pdwinsales=pd.read_csv("winsales.csv",parse_dates=['dateid'],infer_datetime_format=True)winsales['dateid'] = winsales['dateid'].dt.date#winsales.dtypes
Pandas DataFrame保存到SQLite内存数据库
load_ext sqlsql sqlite://sql drop table if exists winsalessql -p winsales
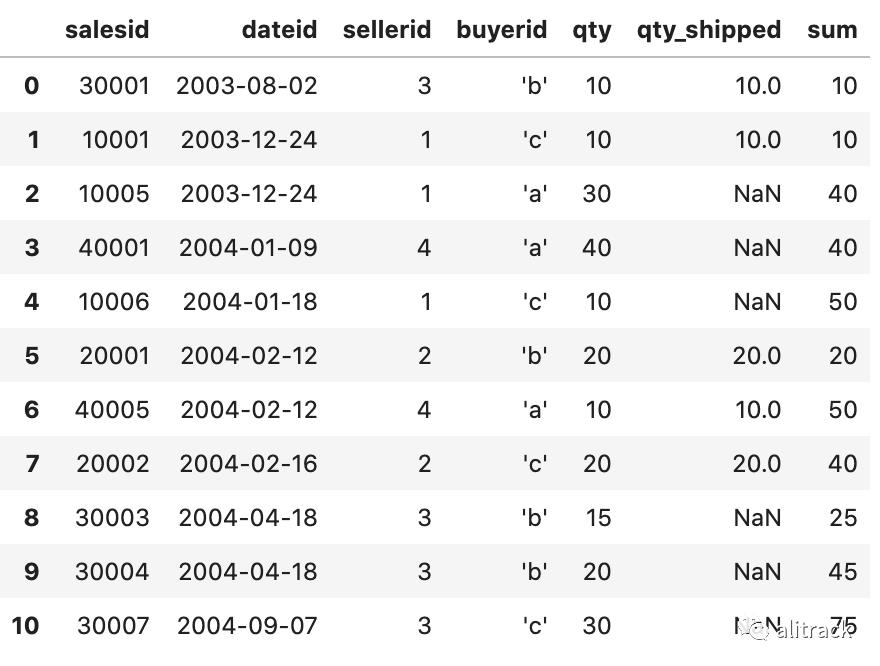
Pandas版本累积和
winsales['sum']=winsales.groupby('sellerid')['qty'].apply(lambda x:x.cumsum())winsales
Koalas版本累积和
import databricks.koalas as ksks.set_option('compute.ops_on_diff_frames',True)winsales_ks= ks.from_pandas(winsales)winsales_ks['sum']=winsales_ks.groupby('sellerid')['qty'].apply(lambda x:x.cumsum())winsales_ks.sort_values(by=['dateid','salesid'])
代码实现是不是和Pandas非常接近?
PySpark DataFrame版本
from pyspark import SparkConfconf=SparkConf()# Enable Arrow-based columnar data transfersconf.set("spark.sql.execution.arrow.enabled", "true")from pyspark.sql import SparkSessionspark=SparkSession.Builder()\.config(conf=conf).master("local[*]").getOrCreate()winsales_sp=spark.createDataFrame(winsales)
from pyspark.sql import functions as F, Windowwindow = Window.partitionBy("sellerid")\.rangeBetween(Window.unboundedPreceding, Window.currentRow)\.orderBy(['dateid','salesid'])winsales_sp0 = winsales_sp.withColumn("sum", F.sum("qty").over(window))winsales_sp0.orderBy(['dateid','salesid']).show()
PySpark SQL版本
winsales_sp.registerTempTable("winsales")spark.sql("""select salesid, dateid, sellerid, qty,sum(qty) over (partition by selleridorder by dateid, salesid rows unbounded preceding) as sumfrom winsalesorder by 2,1;""").show()
SQL版本
和PySpark SQL版本一致
select salesid, dateid, sellerid, qty,sum(qty) over (partition by selleridorder by dateid, salesid rows unbounded preceding) as sumfrom winsalesorder by 2,1;
(SQLite,Postgres或者redshift等可以执行通过)
如果有什么建议和意见,也欢迎留言,或者加我个人微信,
---------------- End ----------------
发求职介绍,联系小编!
发内推职位,联系小编!
直播分享经验,联系小编!
加群交流(禁广告),联系小编!
扫一扫,加小编
以上是关于开窗函数之累积和,PySpark,Pandas和SQL版实现的主要内容,如果未能解决你的问题,请参考以下文章