Spark查询优化之谓词下推 Posted 2021-04-27 DLab数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark查询优化之谓词下推相关的知识,希望对你有一定的参考价值。
下推是查询改写的一项重要优化。查询下推不仅可以降低数据的IO,而且能够节省内存,减少CPU的计算量等,特别是对于分布式的数据处理情境中,查询下推能够对查询性能有一个显著的提升。
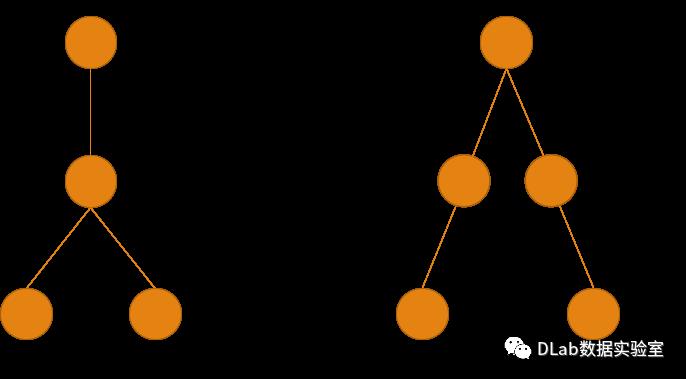
查询下推可以从两个两个方面来理解:从逻辑优化的角度来看,查询下推属于是将逻辑查询树中的一些节点下推到叶子结点或接近叶子结点,即更接近数据源的地方,从而使得上层节点的操作所涉及到的数据量大大减少,提高数据处理效率,如图1所示为一个简单的条件下推;
图1 条件下推
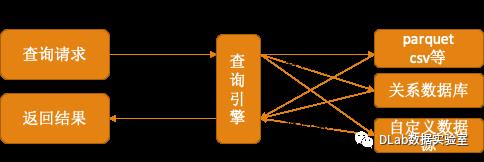
从物理计划执行的角度来看,查询下推是将查询的条件下推到数据源,让数据源直接过滤掉与查询结果无关的数据,从而降低数据IO,提高数据的传输和处理效率;如图2所示
图2 投影和条件下推
下推主要有一下四种:投影下推,条件下推,聚合下推和order by/limit类下推。
投影下推:投影下推即列裁剪,通过将需要的列下推到数据源,这样可以使数据源只返回所需要的列数据给查询引擎,这样可以大大减小数据的传输IO,尤其是对于列存数据源,可以极大的提高查询速率;
条件下推:条件下推即将过滤条件下推到数据源,数据源先进行预过滤,将复合条件的数据返回给查询引擎;
聚合下推:聚合下推是将聚合函数Count,Max,Min,Sum,avg进习惯下推给数据源,利用数据源自己本身的聚合功能进行聚合求值,将求值结果返回给查询引擎,可以极大的减小数据传输开销,同时可以大大节省内存的使用;
OrderBy,Limit下推:这两个下推的意义与上述类似,对于这两个谓词下推到数据源,使数据源在进行数据返回的时候,返回一系列有序的元组或者是所要求的前几条元组,这样便可以节省查询引擎进行复杂的排序开销以及获取不必要的数据量。
当前的一些大数据处理引擎如Hadoop,SparkSQL,Impala,Presto等都支持条件和投影(剪枝)下推。
上述讲到,主流的计算引擎大都只支持到条件下推和投影下推,由于聚合下推比较复杂,而且不同场景的需求程度也各不相同,甚至还需要数据源具有优秀的聚合能力,因此聚合下推并没有被通用的实现在各个存储引擎中。
但有时候,如果一些业务场景涉及较多的简单查询和聚合计算,而且底层数据源用的时候分布式的具有聚合能力的系统,那么进行聚合下推将会大大减少计算引擎与数据源之间的数据IO,从而对查询性能有很大的帮助。
下面以SparkSQL为例,介绍聚合下推的实现方法。
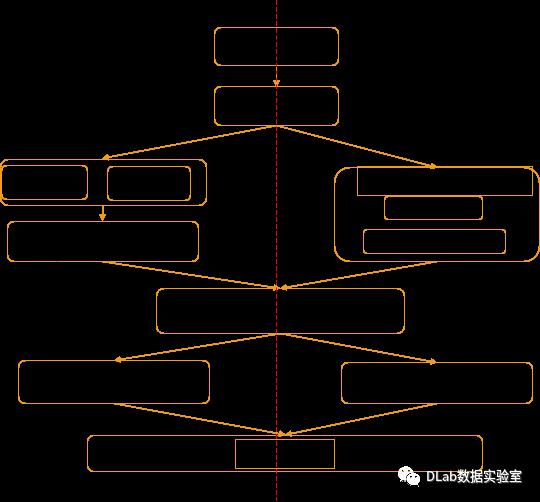
图3是一个Spark SQL进行SQL语句从解析到查询的完整流程,想要进行聚合谓词的下推,就是在Optimized Logical Plan转为Physical Plan的过程中,修改转换策略,使得生成的物理计划能够将聚合谓词和数据扫描(获取)合并;
例如:示例sql语句:select count(*) from info where fuin > 100174;
聚合下推后的Physical Plan
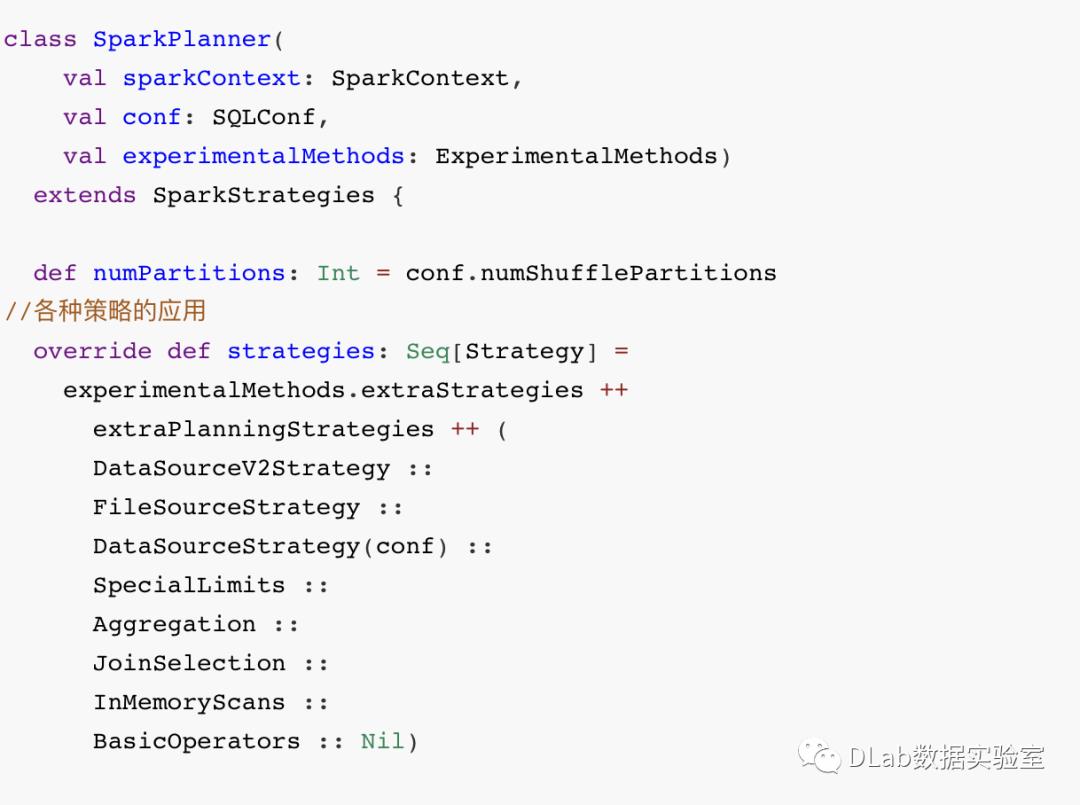
在Spark SQL中,优化后的逻辑计划转化为物理计划的时候,会在Spark Planner中应用一些列的策略,如下:
通过应用各种策略,从而一步步将逻辑计划转换成物理计划;
因此,如果要想进行聚合下推,就可以在进行聚合的策略中进行修改以改变最后生成的物理执行计划;
· 在Aggregate策略进行应用的时候,通过条件判断来开启一个新的分支:如果我们在进行查询的时候,设置了开启查询下推的功能,则在这里进行判断后则会进入一个新的分支AggPushDownUtils,该分支的作用是进行数据扫描和初步聚合的结合,即将聚合函数下推到数据源,直接返回聚合结果;
· AggPushDownUtils在PhysicalOperation进行了聚合和数据读取两方面的物理计划
·当最后执行到数据读取的时候,则会调用JDBCRelation和JDBCRDD_AGG两个类,JDBCRDD_AGG是为聚合下推重写的一个数据读取的类;
这样的聚合下推优化在数据量比较小的时候,下推的性能没有太大的提升,但是随着数据量的增大,下推的效果逐步明显,甚至会出现性能翻倍的效果。同时,采用下推的方式,还可以大大节省内存,下推的方式不会因为数据量的增大而增加计算引擎对内存的需求量,但是反观无下推的执行方式,随着数据量的增大甚至会OOM。
由上图可以看出,查询下推之后的性能性能影响因素主要由数据源决定,聚合下推的关键是将聚合函数下推到数据源,由数据源执行完聚合计算后返回聚合结果。因此数据源的聚合性能直接影响了聚合查询的效率。
以上是关于Spark查询优化之谓词下推的主要内容,如果未能解决你的问题,请参考以下文章
hive sql 优化
spark那些情况下不会渭词下推
大数据SparkSql连接查询中的谓词下推处理
谓词下推
如何防止谓词下推?
SparkSQL调优