细数Spark3.0的那些新特性
Posted DLab数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细数Spark3.0的那些新特性相关的知识,希望对你有一定的参考价值。
前言
Apache Spark在6月份分布了3.0.0版本,增加了许多性能优化方面的新特性。作为大数据分析的重要引擎,在SQL查询优化方面的新特性值得期待和使用。Spark在SQL查询方面的性能优化主要分为四个方向七个方面:
开发交互方向
新的Explain格式
所有join支持hints
动态优化
自适应查询执行
动态分区裁剪
Catalyst提升
增强嵌套列的裁剪和下推
增强聚合的代码生成
基础设施更新
支持新的Scala和Java版本

新特性介绍

这7个方面最值得关注的在于动态优化方向的更新,下面来着重讲一下。
自适应查询执行
自适应查询执行通过使用运行时的统计信息进行三个方面的优化:
根据统计信息设置reducer的数量来避免内存和I/O资源的浪费
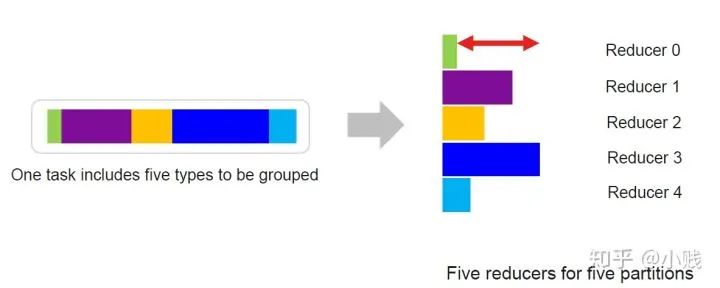
Spark2.4的版本中,Reducer的个数是通过配置文件中的shuffle.partition来设置的,如图有五个分区就有五个reducer来进行处理,由上图可以看到,reducer0的任务量较小,reducer3的任务量较大,这样整个任务的效率瓶颈就在reducer3上,任务分配的不平衡浪费了资源,降低了处理效率。
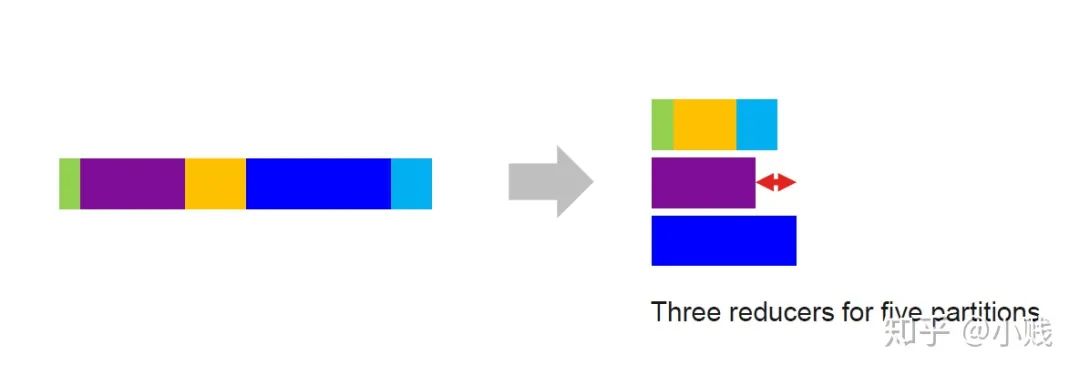
Spark3.0中,Reducer的个数进行了优化,同样的五个分区任务最后只用了三个reducer进行了处理,这样就不会造成上述reducer0空转的资源浪费情况。
选择更优的join策略来提高连接查询性能
在大数据中,join策略可以大致分为三种,分别是HashJoin,BroadCastJon和MergeJoin。Spark会根据表数据的大小选择合适的Join策略,但是当前的选择都是基于静态统计信息的。
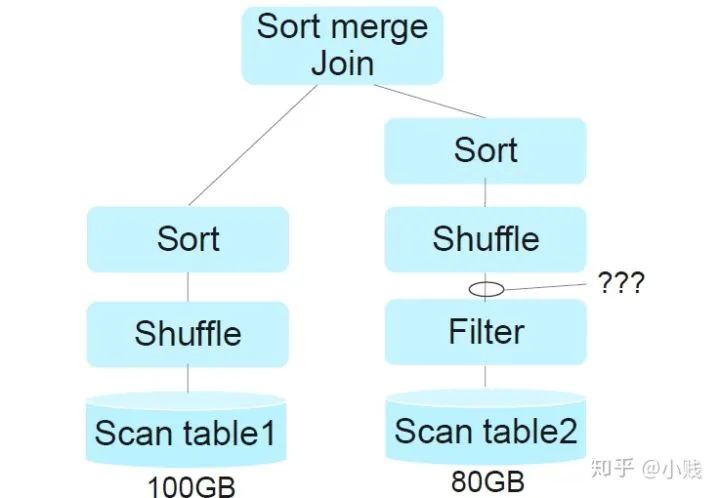
例如在Spark2.4中,如上两种表的大小分别为100GB和80GB,通过静态信息统计,Spark在最后选择了SortMergeJoin的策略。但是这个方案是基于两个join表的大小为100和80GB大小的前提下的,并没有参考table2经过条件过滤之后的大小。
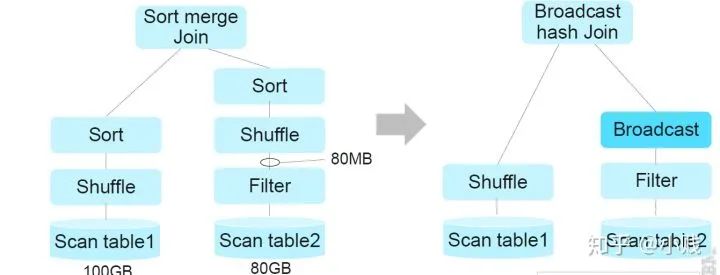
在Spark3.0中,加入了动态信息统计,引擎不仅会掌握table1和table2的静态统计信息,还会在执行过程中,适时收集两表的数据量的变化,及时调整策略。如上例子,table2原本有80GB的数据参与join操作,但是经过过滤操作,有效的参与join的数据只有80MB,因此这样的数据量更适合Broadcast Join策略,所以在Spark3.0中会及时调整。
优化join数据来避免不平衡查询造成的数据倾斜
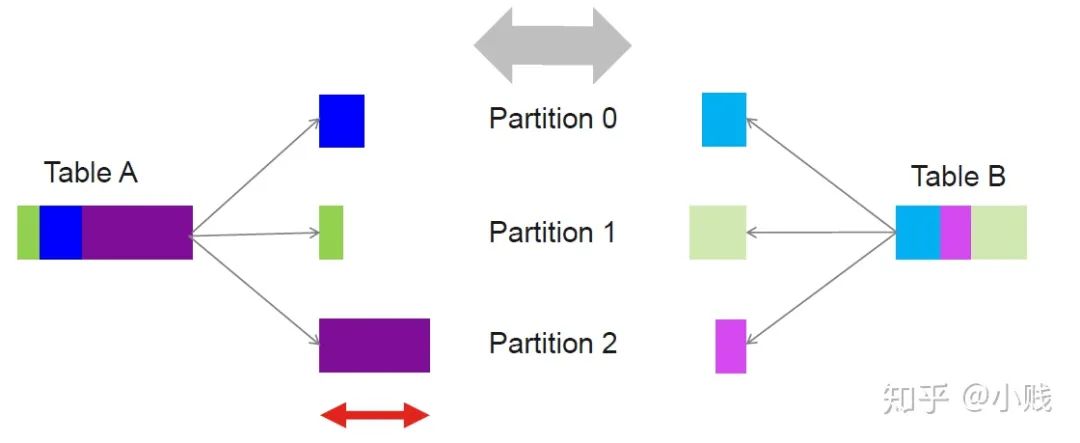
Join的时间取决于最大的分区join时间,因此如上图所示,TableA和TableB的join时间取决于partition2,因为TableA中的数据倾斜导致了整个表连接任务的耗时操作。
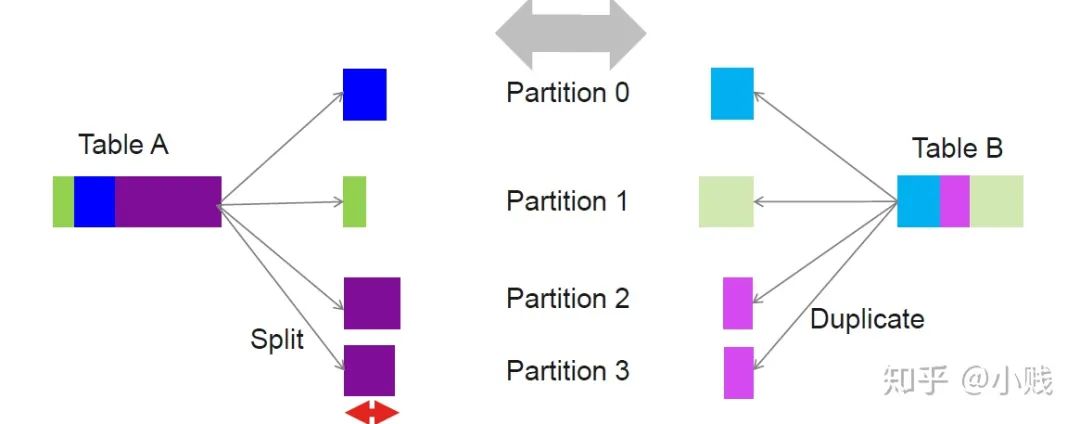
在Spark3.0中,通过对倾斜数据的自适应重分区,解决了倾斜分区导致的整个任务的性能瓶颈,提高了查询处理效率。
动态分区裁剪
动态分区裁剪是从下推演化而来,下推数据静态裁剪,通过将条件下推至数据源,从而减小了上层算子计算的数据量(下推可以参考我之前的文章)。动态裁剪是在静态裁剪的基础上,加入了运行时的数据裁剪。
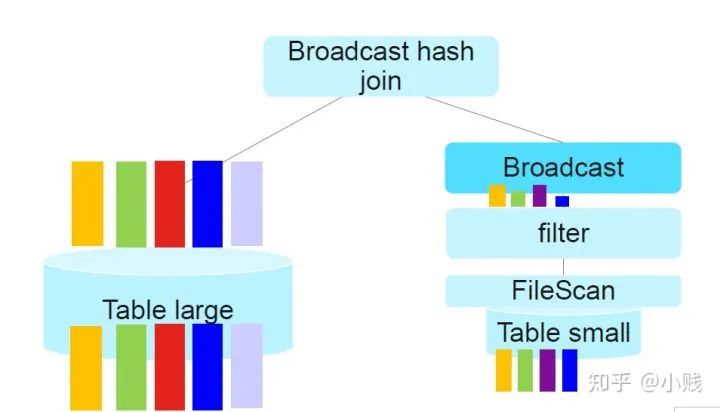
在Spark2.4中的静态裁剪(条件下推)如上图所示,通过将条件下推到join操作之前,减小参与连接操作的数据量从而达到性能的优化。
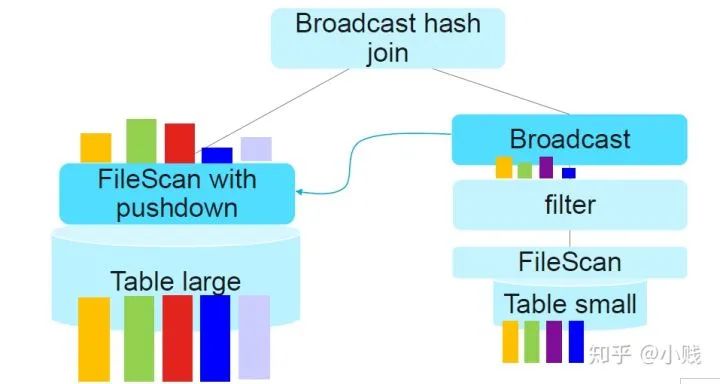
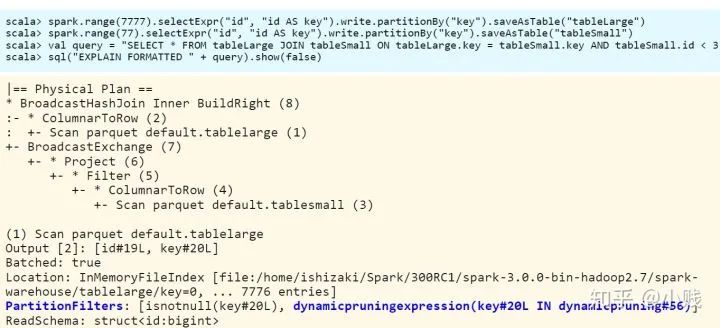
但是对于参与连接的左表来说,并没有起到提前过滤数据的作用,这样性能提升并不大。在Spark3.0中,加入了动态分区裁剪优化,将其中一个表(本例中的小表)过滤后的数据作为新的过滤条件下推到另一个表(本例中的大表)中,从而起到对大表的运行时过滤作用。这样就大大减少了两表参与join的数据量,从而提高了查询性能。
总结
Spark3.0的优化性能远不止这些,当然也不意味着所有的场景都适合进行优化或者能够产生明显的性能提升,还需要结合业务和数据进行探索和使用。
参考:SQL Performance Improvements At a Glance in Apache Spark3.0 , Kazuaki Ishizaki, IBM Research


长按二维码识别关注

文章都看完了不点个 吗
以上是关于细数Spark3.0的那些新特性的主要内容,如果未能解决你的问题,请参考以下文章
JDK的前世今生:细数 Java5 - 15 的那些经典特性