优化一下 Spark 读 Kafka 的UI
Posted Apache Committer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化一下 Spark 读 Kafka 的UI相关的知识,希望对你有一定的参考价值。
我们学习一个项目的时候,一开始只能有一个了解整体架构和使用方法,很难熟悉到具体细节,我们学习的过程也是一个从一个点开始,以点带面的逐渐深入。接下来我们通过优化 spark 的一个 ui,熟悉 spark streaming 操作 kafka 的流程和原理。
引出问题
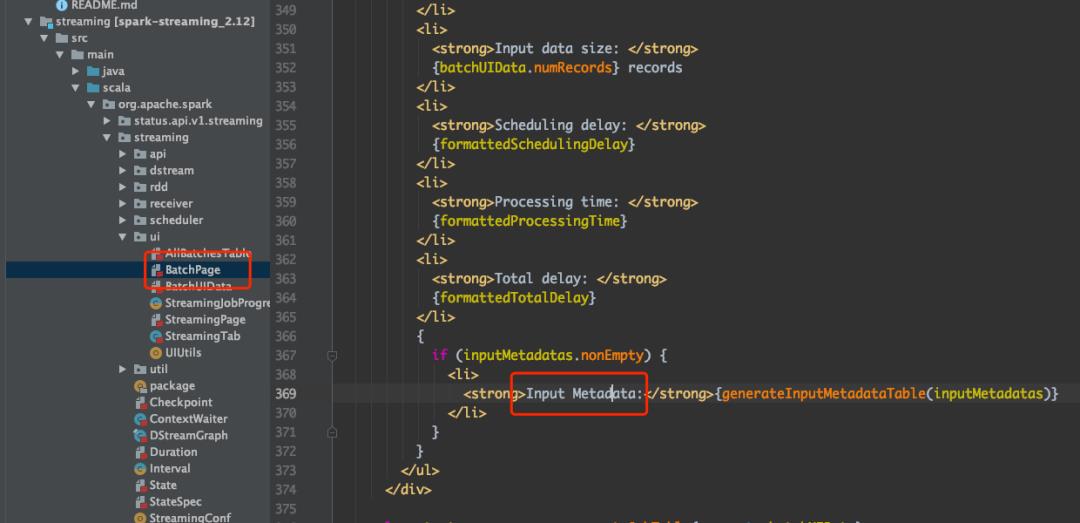
使用 spark streaming 读 Kafka 数据的时候,web 界面会展示分配到每个 Executor 的 partitions,以及每个 partition 的 offset,方便开发人员观察负载,如下图:
通过 Metadata 可以看出某个 batch 处理的所有的 partition 的 offset 详情,也就知道了每个 Executor 大概的整个负载,但是这个看起来挺乱的,我希望能够按照记录数排个序,看起来就比较分析意义。
分析代码
在动手之前要熟悉一下这部分对应的代码,可以全局搜索这些字符串找到对应代码的位置,搜索 “Details of batch” 可以找到一个 BatchPage 的类,然后在类里面搜索 “Input Metadata” 可以找到这里展示的信息对应的类是 BatchUIData 的 streamIdToInputInfo 字段,也就是一个 StreamInputInfo 类:
通过代码分析工具找到相关的代码,也就是 DirectKafkaInputDStream 的 compute 方法:
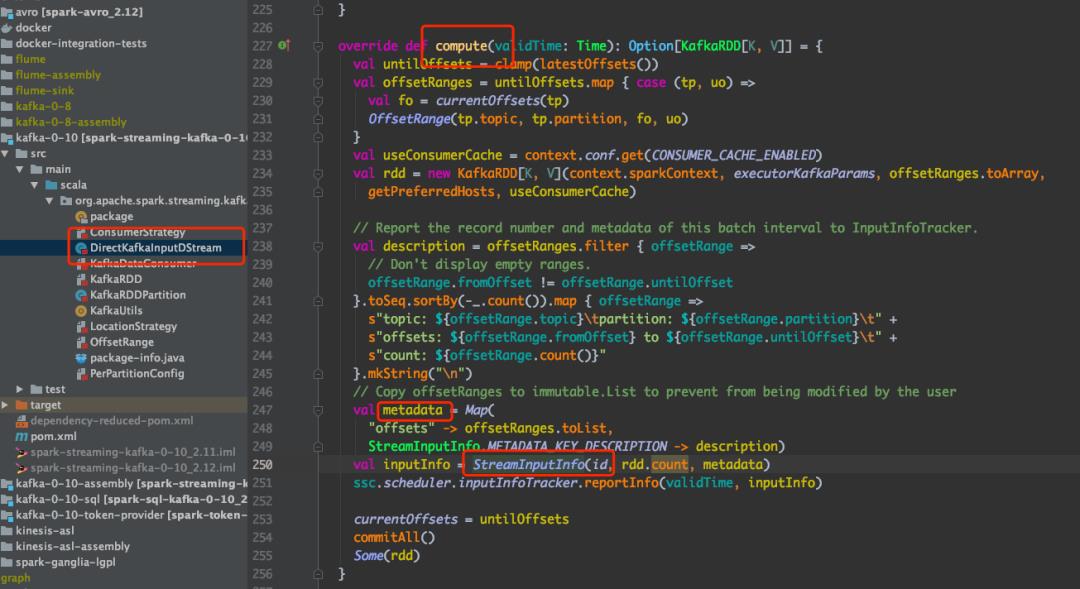
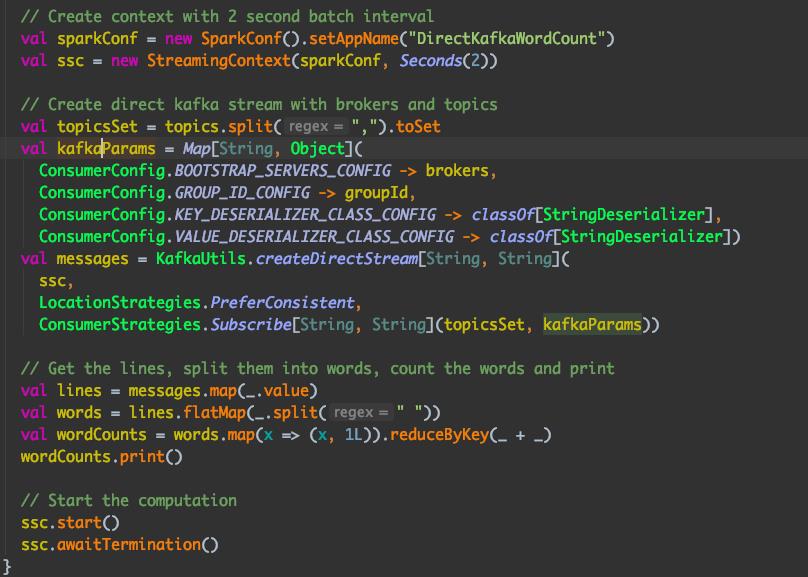
看到这里很多人就比较熟悉了,Spark streaming 消费 Kafka 数据是通过 KafkaUtils.createDirectStream 方法实现,进一步查看可以发现 是通过 DirectKafkaInputDStream 类实现的:
DirectKafkaInputDStream 继承自 InputDStream,读取 Kafka 的核心方法是 compute,compute 方法会发送到 Executor 执行,每次执行都会将对应的 partition 的元数据发送到 web ui。
修改代码
知道了代码的结构就可以修改代码了,我们要做的就是在 metadata 里面算下每个 partition 的 count,然后按照 count 排序展示,代码如下:
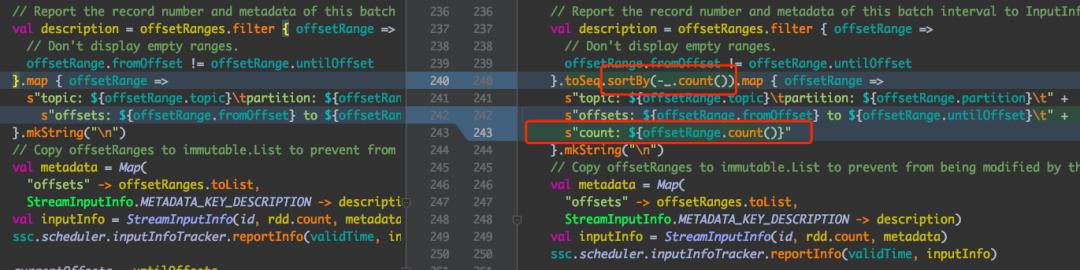
首先 offsetRanges 数组按照 count 排序,最后展示的时候加一个 count 字段。
然后可以在本地启动验证一下,本地启动的时候由于 spark 自带的依赖都是 provided 的可能失败,需要勾选一下启动配置:
本地运行 spark 程序,当然要启动一下 kafka 插入测试数据,访问 Web 界面:
说明已经成功了,然后就可以把代码提交到 spark 官方库,由于第一次给 spark 贡献代码很多注意事项不清楚,过了很久才满足了需求,详情可以查看:https://github.com/apache/spark/pull/26266
总结
一开始接触一个项目很难有大的架构方面的贡献,只能在一些细节上优化,通过这个小的细节优化,我们也熟悉了 Spark 消费 Kafka 的方法和原理。如果希望给一些开源项目贡献代码,也可以从优化 Web UI 开始。
以上是关于优化一下 Spark 读 Kafka 的UI的主要内容,如果未能解决你的问题,请参考以下文章
Spark Streaming 基于 Direct API 优化与 Kafka 集成
Spark Streaming 基于 Direct API 优化与 Kafka 集成
Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化