spark windows idea开发环境搭建
Posted 编程修仙传
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark windows idea开发环境搭建相关的知识,希望对你有一定的参考价值。
1. 安装 scala sdk
a. 下载 scala 免安装包 https://www.scala-lang.org/download/2.11.12.html, scala 版本分为 2.11.x 和 2.12.x 两种,此处选择 2.11.x,在开发过程中,选择 maven 中的 jar 包时,也要注意使用的 scala 版本,需要版本对应。
https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.zip
a. 解压到本地目录,并配置环境变量
2. 安装 hadoop 环境
spark 本地开发需要 hadoop 环境支持
a. 下载 hadoop 3.x 环境
# hadoop 版本列表
# https://archive.apache.org/dist/hadoop/common/
# 选择 hadoop3.0.0
https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
b. 配置环境变量
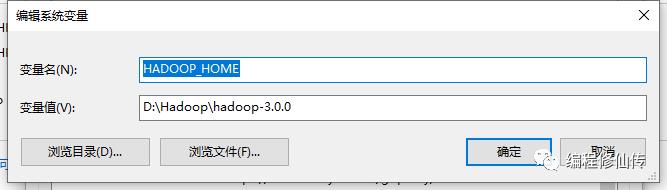

c. hadoop bin 目录增加 winutils.exe 工具
winutils 是 windows 下的 hadoop 二进制工具,在本地运行 spark 的时候,是必不可少的组件。
# 从 gitee 进行下载
https://gitee.com/saterr/winutils?utm_source=alading&utm_campaign=repo
3. idea 安装scala 插件
idea 设置 -> 插件 里面下载 scala 插件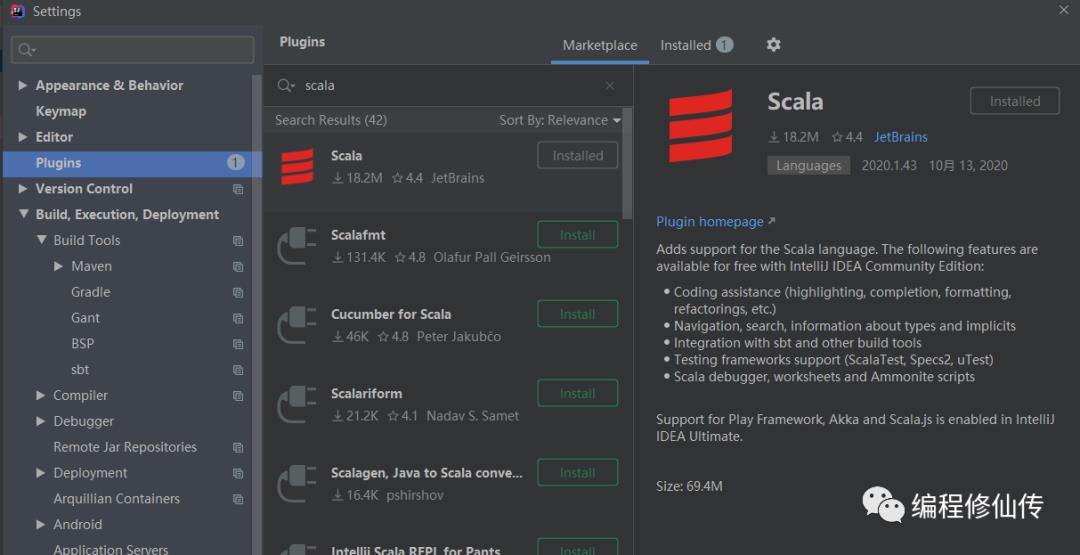
4. 创建 maven 项目
a. 直接创建 scala 项目,和我们平时组织的代码不太一样,可以通过创建一个 maven 项目,然后改成 scala 项目。
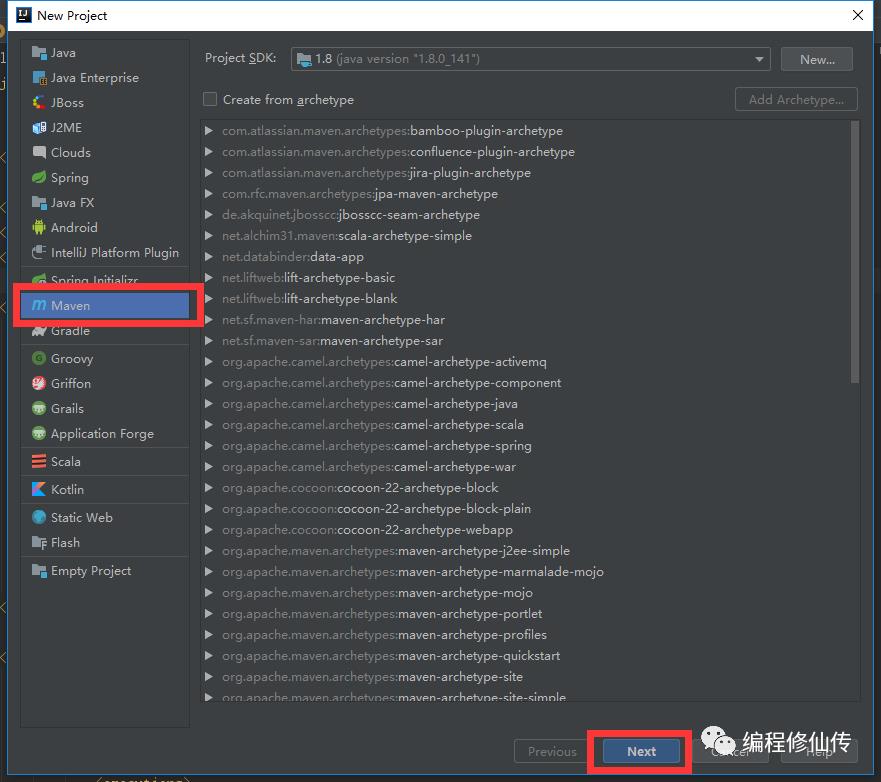
b. 修改代码根目录名称为 scala
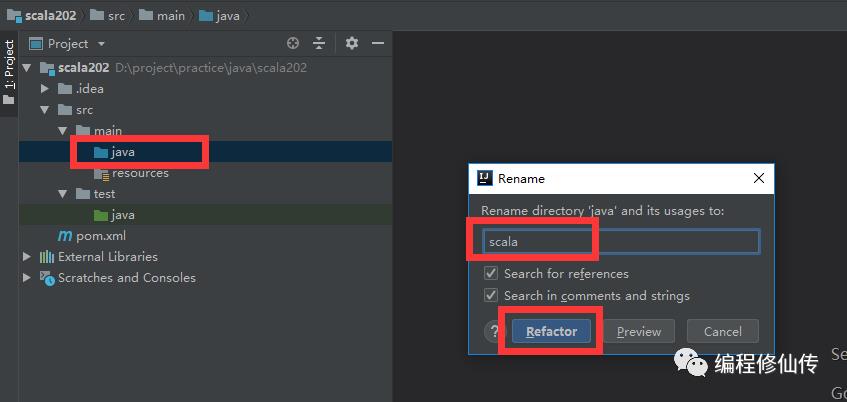
c. 修改测试代码根目录名称为 scala
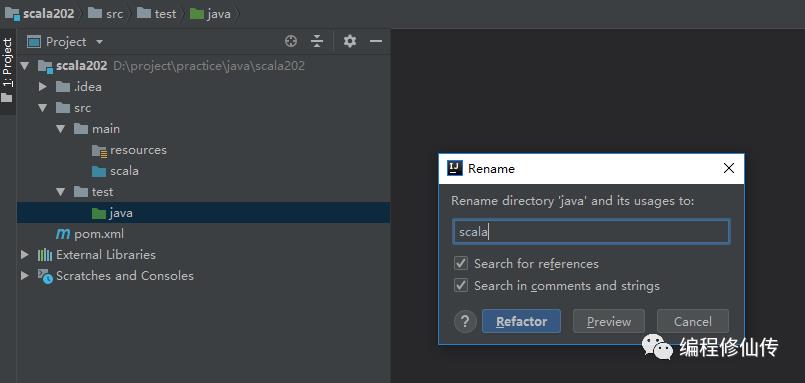
d. 添加框架支持
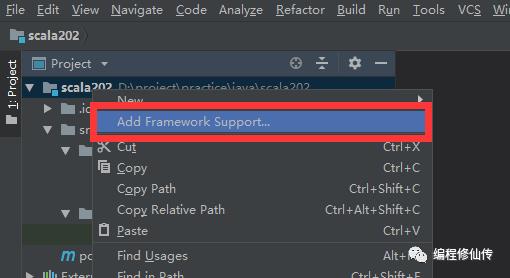
e. 选择 scala 框架
5. 引入 maven 依赖
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.4</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
6. 编写 wordcount 测试
object Application {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
sc.textFile("D:\\data\\word.txt")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
.foreach(println)
sc.stop()
}
}
7. 修改 VM 参数
在写完 spark 代码进行测试运行的时候,很容易出现以下问题
Exception in thread "main" java.lang.IllegalArgumentException: System memory 259522560 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
此问题提示我们需要修改 java 虚拟机运行参数,打开Run/Debug 配置界面,修改 VM 参数
-Xms256m -Xmx1024m
以上是关于spark windows idea开发环境搭建的主要内容,如果未能解决你的问题,请参考以下文章