Win7安装PySpark
Posted 鲍教授
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Win7安装PySpark相关的知识,希望对你有一定的参考价值。
不上spark已经不能解决问题了,根据网上的资料以及自己的实践,确认如下方法是可行的,供参考。
一、概要
Spark的框架是用Scala编写的,而Scala是一种运行在Java虚拟机上实现和Java类库互联互通的面向对象及函数式编程语言,PySpark使用Python开发所以需要使用Py4J(用Python和Java编写的库,通过Py4J,Python程序能够动态访问Java虚拟机中的Java对象,Java程序也能够回调Python对象。),最后需要Hadoop(Spark的版本需要与Hadoop版本相匹配)。
Java JDK: jdk-8u261-windows-x64,需要注册账号
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
Scala: scala-2.12.8,网络问题可能下载很慢,尝试手机热点很快,下载windows安装版本
https://www.scala-lang.org/download/2.12.8.html
Spark:spark-2.4.7-bin-hadoop2.7
http://spark.apache.org/downloads.html
Hadoop: hadoop-2.7.7.tar
http://hadoop.apache.org/releases.html
hadooponwindows-master,能支持在windows运行hadoop的工具
https://pan.baidu.com/s/1o7YTlJO?errmsg=Auth+Login+Sucess&errno=0&ssnerror=0&
winutils,在window系统上安装hadoop时所需要的winutils文件
https://github.com/cdarlint/winutils
三、安装
3.1 JDK安装
安装没有难度,安装完成后配置环境变量,计算机右键-属性-高级系统设置-环境变量-系统变量,新建如下系统变量
新建完成后在path变量中添加:%JAVA_HOME%\bin
配置好后开启cmd窗口,验证是否安装成功。
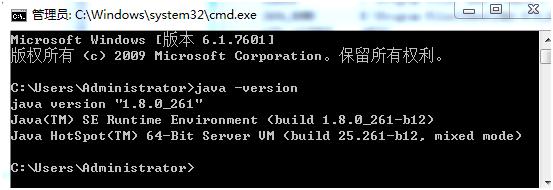
3.2 Scala安装
安装没有难度,安装完成后配置环境变量,计算机右键-属性-高级系统设置-环境变量-系统变量,新建如下系统变量
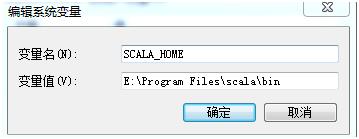
新建完成后在path变量中添加:%SCALA_HOME%
配置好后开启cmd窗口,验证是否安装成功。
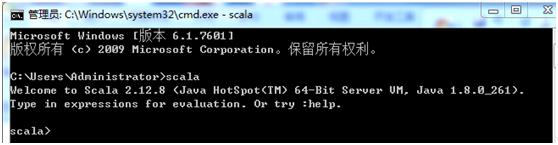
3.3 Spark安装
解压后直接配置环境变量,不需要安装。特别注意:Spark解压文件放置的路径不能有空格,否则报错!
新建完成后在path变量中添加:%SPARK_HOME%\bin
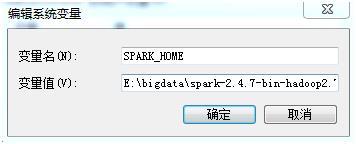
3.4 Hadoop安装
解压后直接配置环境变量,不需要安装。
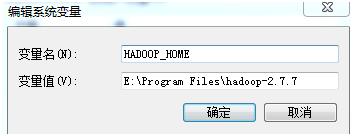
建完成后在path变量中添加:%HADOOP_HOME%\bin 把hadooponwindows-master的bin覆盖hadoop-2.7.7的bin
将winutils.exe文件放到Hadoop的bin目录下(我的是E:\spark\spark-2.1.0-bin-hadoop2.7\bin),然后以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:winutils.exe chmod 777 c:\tmp\Hive
需要提前新建c:\tmp\Hive文件夹
3.5 Python安装
Anaconda安装python3.7
将spark所在目录下(比如我的D:\IT\bigdata\soft\spark-2.4.3-bin-hadoop2.7\python)的pyspark文件夹拷贝到python文件夹下(我的是D:\IT\python\Python\Lib\site-packages)
安装Py4J pip install py4j
3.6 启动PySpark
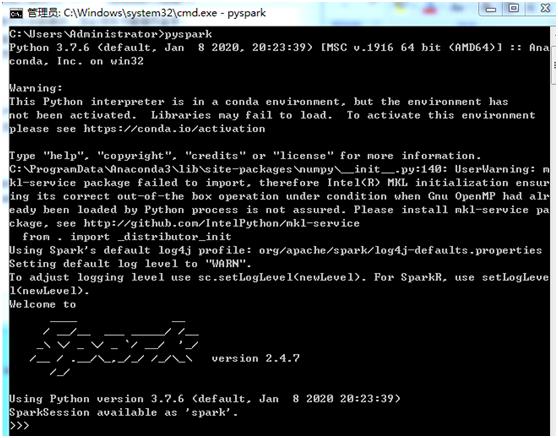
安装成功
3.7 在python中验证
祝学习愉快。
以上是关于Win7安装PySpark的主要内容,如果未能解决你的问题,请参考以下文章