Spark On Zeppelin
Posted 大数据杂烩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark On Zeppelin相关的知识,希望对你有一定的参考价值。
一、背景介绍
为了提高数据处理能力,突破单机在计算与资源上的瓶颈,如Hadoop、Spark、Flink 等分布式计算框架和基于HDFS的分布式存储系统成为大多数选择。实际工作中,大部分时间我们都在研发、部署和维护批处理、流处理程序,完成相应的业务需求,但是需要对一批数据做探索性分析,所谓探索性即尚且没有明确的思路,需要不断的尝试,这时你无法形成完整方案写到代码文件、打包、正式部署,临时有个任务需要验证一下,特别针对研发人员,你为这个任务写个正式代码文件、打包、部署显然过于繁琐,并且很多线上环境是不允许随便传代码的。这里的问题就是,如何在分布式计算框架之上实现交互式运行代码? Notebook 显然成为首选。Notebook 是一类基于 Web 的交互式数据分析工具,比较流行的有 Jupyter、Zeppelin 等。Jupyter 是基于 Python 的,前身是 IPython,在单机数据分析上表现非常优异,特别是结合 pandas 库。而 Zeppelin 则以插件的形式对大多数分布式计算引擎提供了友好的支持,尤其是 Spark。
二、组件版本
zeppelin-0.9.0-preview2-bin-all.tgz
CDH 5.16.2
Spark 2.4.0 (自行编译放入CDH,原本版本是1.6.0)
三、搭建
1.解压zeppelin-0.9.0-preview2-bin-all.tgz
2.进入conf下配置zeppelin-env.sh
3.进入conf下配置shiro.ini

左边是用户名右边是密码admin是权限
4.进入conf写配置zeppelin-site.xml
<!-- 将Notebook repo更改为HDFS存储 -->
<property>
<name>zeppelin.notebook.storage</name>
</property>
<!-- Notebook在HDFS上的存储路径 -->
<property>
<name>zeppelin.notebook.dir</name>
<value>/zeppelin/notebook</value>
</property>
<!-- 启用Zeppelin的恢复功能。当Zeppelin服务挂掉并重启之后,能连接到原来运行的Interpreter -->
<property>
<name>zeppelin.recovery.storage.class</name>
<value>org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage</value>
</property>
<!-- Zeppelin恢复元数据在HDFS上的存储路径 -->
<property>
<name>zeppelin.recovery.dir</name>
<value>/zeppelin/recovery</value>
</property>
<!-- Zeppelin禁止莫名用户登录 -->
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
</property>
四、启动验证
1.进入配置目录下执行 bin/zeppelin-daemon.sh start
2.创建NoteBook使用默认配置
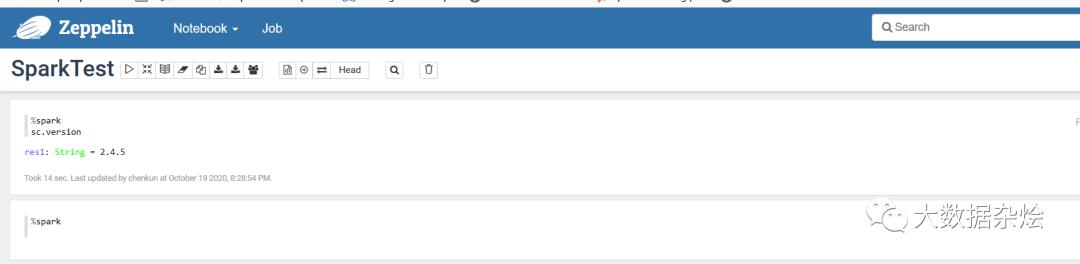
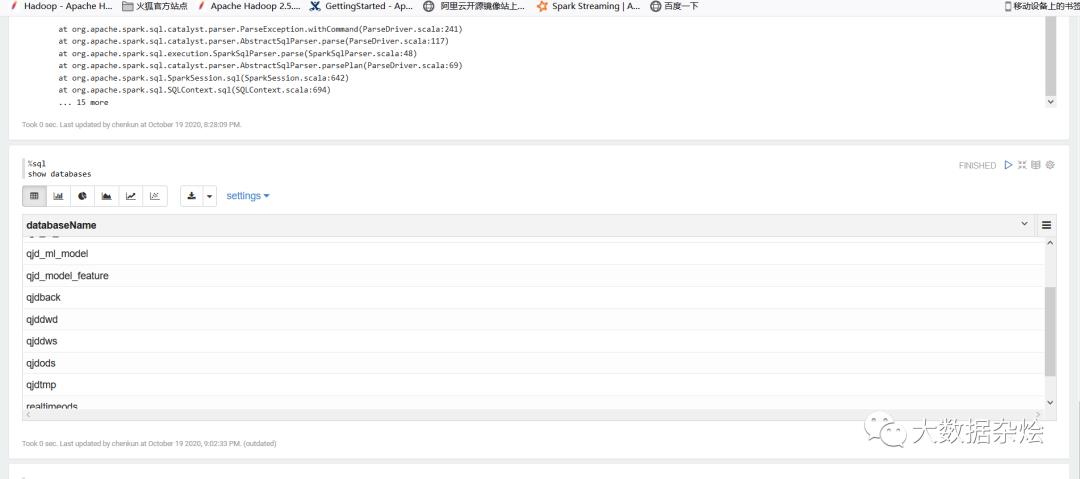
上述操作查看hive库表,并查询数据都是OK,因为没有配置使用Spark版本默认自带编译Spark2.4.5,如果需要改动也很简单,打开编译器编辑相对应的spark版本和conf文件目录,在对应配置上运行模式即可。
时间仓促如有错误恳请大家原谅。
以上是关于Spark On Zeppelin的主要内容,如果未能解决你的问题,请参考以下文章
SparkSQL & Spark on Hive & Hive on Spark
mac spark和hive整合(spark on hive)
Apache Spark支持三种分布式部署方式 standalonespark on mesos和 spark on YARN区别