Spark部署一spark安装
Posted 沐濯的大数据之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark部署一spark安装相关的知识,希望对你有一定的参考价值。
哈喽,同学们好,继上篇文章《Hive部署一hive安装》,我们安装好了
Hive。我们现在开始安装部署spark,开启spark之旅。
一、下载安装包
spark官网:http://spark.apache.org/
https://mirrors.aliyun.com/apache/spark/spark-3.0.1/
二、解压spark安装包(只在bigdata01做)
1、通过rz,把spark安装包spark-3.0.1-bin-hadoop3.2.tgz文件上传到bigdata01机器的/home/bigdata/install_pkg目录(为了方便,我们把安装包都放置同一个目录哈)。
2、执行解压缩命令:
tar -zxvf spark-3.0.1-bin-hadoop3.2.tgz
3、把解压后的spark目录,移动到安装目录/usr/local/soft目录下:

4、在/usr/local/soft/spark-3.0.1-bin-hadoop3.2/conf目录中,修改配置文件:
(1) cp spark-env.sh.template spark-env.sh
(2) vim spark-env.sh
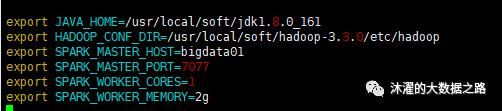
# 配置JAVA_HOMEexport JAVA_HOME=/usr/local/soft/jdk1.8.0_161# 配置Hadoopexport HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.3.0/etc/hadoop# 设置Master的主机名export SPARK_MASTER_HOST=bigdata01# 提交Application的端口,默认就是这个,万一要改呢,改这里export SPARK_MASTER_PORT=7077# 每一个Worker最多可以使用的cpu core的个数export SPARK_WORKER_CORES=1# 每一个Worker最多可以使用的内存export SPARK_WORKER_MEMORY=2g
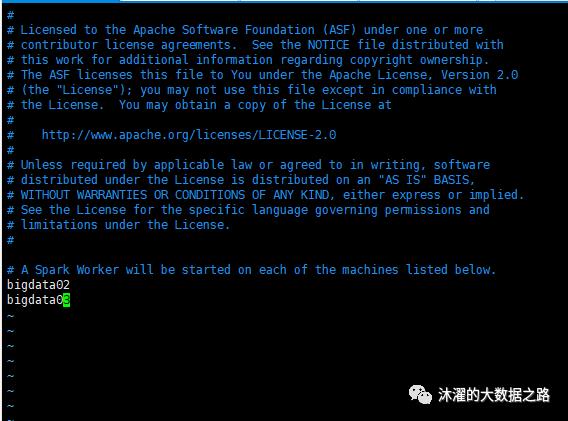
(3) cp slaves.template slaves
(4) vim slaves(配置从节点)
三、三台机器配置spark
1、在bigdata01上,复制spark到其余两台机器
scp -r /usr/local/soft/spark-3.0.1-bin-hadoop3.2
bigdata@bigdata02:/usr/local/soft
scp -r /usr/local/soft/spark-3.0.1-bin-hadoop3.2
bigdata@bigdata03:/usr/local/soft
2、在三台机器上,配置环境变量
(1)vi ~/.bash_profile
(2)以下内容追加到文件的尾部:
# SPARK_HOMEexport SPARK_HOME=/usr/local/soft/spark-3.0.1-bin-hadoop3.2export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin
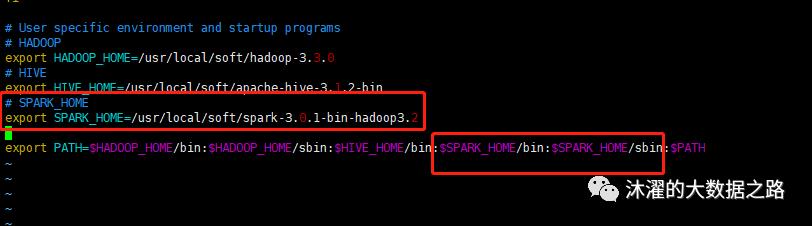
(3)执行命令,使得配置生效:
source ~/.bash_profile
6、启动spark集群:
(1)由于Hadoop集群启动时,也是start-all.sh以及stop-all.sh,以防冲突,在三台机器上,修改/usr/local/soft/spark-3.0.1-bin-hadoop3.2/sbin目录下文件名:
mv start-all.sh start-spark-all.sh
mv stop-all.sh stop-spark-all.sh
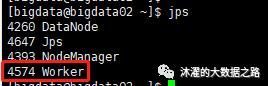
(2)在bigdata01上,输入start-spark-all.sh,后再输入jps,出现Master:

(3)启动后,在bigdata02、bigdata03机器上,输入jps,出现worker,则OK啦:
(4)启动,spark-sql:

如图,我们可以看到,spark已经安装好了,但是却没有和hive打通,hive中应该是有个tmp库的(我偷偷建的),但是spark中却没有显示,是因为元数据没有打通,接下来我们开始与hive进行打通。
四、打通hive
1、在bigdata01上,启动hive元数据服务:
hive --service metastore &
hive --service hiveserver2 &
2、在三台机器上,进行spark配置:
cp /usr/local/soft/apache-hive-3.1.2-bin/conf/hive-site.xml /usr/local/soft/spark-3.0.1-bin-hadoop3.2/conf/
cp /usr/local/soft/apache-hive-3.1.2-bin/lib/mysql-connector-java-8.0.22.jar /usr/local/soft/spark-3.0.1-bin-hadoop3.2/jars/
3、重启spark集群:
stop-spark-all.sh
start-spark-all.sh
再次输入spark-sql:

五、配置pyspark
1、在三台机器上,确认是否有Python:
whereis python

由于存在了,我们便不安装了,如果没有的话,安装Python3:
sudo yum -y install python36
2、启动pyspark:

报错,则是因为,机器上没有Python,但是有Python3:

因此,我们在三台机器上,修改/usr/local/soft/spark-3.0.1-bin-hadoop3.2/bin/pyspark,将PYSPARK_PYTHON=python修改为PYSPARK_PYTHON=python3:
vi usr/local/soft/spark-3.0.1-bin-hadoop3.2/bin/pyspark
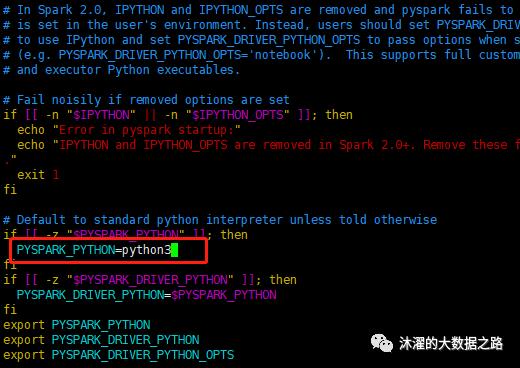
然后我们再次启动pyspark:
如此,我们就弄好啦。
访问WEB页面:
http://192.168.211.128:8080/
同学们,经过以上操作后,我们已经安装好了spark。可以开始初步学习大数据啦。
以上是关于Spark部署一spark安装的主要内容,如果未能解决你的问题,请参考以下文章