Spark中的join策略
Posted 算法工程师的自我修养
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中的join策略相关的知识,希望对你有一定的参考价值。
背景
join是SQL中最常见的操作,写SQL最经常的场景就是几张表各种join,join操作也是各种操作中最耗时的操作之一。
作为一个Spark SQL Boy,有必要详细了解一下Spark的join策略。
MR中的join
介绍Spark的join策略之前,先介绍一下MR中是如何实现join操作的。
MR中的join分为Map端join和Reduce端join。
数据准备如下:
订单表
1001 01 11002 02 21003 03 31004 01 41005 02 51006 03 6
商品表
01 小米02 华为03 格力
Map join:
1. 加载阶段:把小表加载到内存里面;
2. Hash join:构建Hash表做查询。
只在Map端处理数据,没有Reduce,优点是并行度非常高,没有Shuffle,不会出现数据倾斜。
Mapper类
public class JoinMapper extends Mapper<LongWritable, Text, TableBean, NullWritable> {HashMap<String,String> pdMap=new HashMap<>();TableBean k = new TableBean();protected void setup(Context context) throws IOException, InterruptedException {URI[] cacheFiles = context.getCacheFiles();String path = cacheFiles[0].getPath().toString();InputStreamReader inputStream = new InputStreamReader(new FileInputStream(path));BufferedReader bis = new BufferedReader(inputStream);String line;while((line=bis.readLine())!=null){String[] fields = line.split("\t");pdMap.put(fields[0],fields[1]);}bis.close();inputStream.close();}protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = line.split("\t");String pId = fields[1];String pdName = pdMap.get(pId);k.setAmount(Integer.parseInt(fields[2]));k.setId(fields[0]);k.setPid(fields[1]);k.setPname(pdName);k.setFlag("order");context.write(k, NullWritable.get());}}
Reduce join:
1. Map阶段:分片做循环,join的key为进入Reduce Task的key,value是一个对象;
2. Reduce阶段:同一个key进入同一个Reduce Task,封装输出对象。
Mapper类
public class TableBeanMapper extends Mapper<LongWritable, Text, Text, TableBean> {FileSplit filesplit;String name;TableBean v = new TableBean();Text k = new Text();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {InputSplit inputSplit = context.getInputSplit();filesplit = (FileSplit) inputSplit;Path path = filesplit.getPath();name = path.getName();}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String s = value.toString();if (name.startsWith("order")) {String[] split = s.split("\t");v.setId(split[0]);v.setPid(split[1]);v.setAmount(Integer.parseInt(split[2]));v.setPname("");v.setFlag("order");k.set(split[1]);} else {String[] split = s.split("\t");v.setId("");v.setPid(split[0]);v.setAmount(0);v.setPname(split[1]);v.setFlag("pd");k.set(split[0]);}context.write(k, v);}}
Reducer类
import org.apache.commons.beanutils.BeanUtils;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;import java.lang.reflect.InvocationTargetException;import java.util.ArrayList;public class TableBeanReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {ArrayList<TableBean> tableBeanArrayList = new ArrayList<TableBean>();TableBean tableBean = new TableBean();for (TableBean value : values) {if (value.getFlag().equals("order")) {TableBean tableBean1 = new TableBean();try {BeanUtils.copyProperties(tableBean1, value);tableBeanArrayList.add(tableBean1);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}} else {try {BeanUtils.copyProperties(tableBean, value);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}}}for (TableBean bean : tableBeanArrayList) {bean.setPname(tableBean.getPname());context.write(bean, NullWritable.get());}}}
Spark join策略
Spark SQL执行引擎最常使用的3种策略,分别是Broadcast Hash join,Shuffle Hash join和Sort merge join,剩下两种分别是Nested loop join和Cartesian product join。
Broadcast Hash join
相当于MR中的Map join,分为两个阶段。
1. 广播阶段:把小表广播到大表数据所在的executors上
2. Hash join:在每个executor上做Hash join
Broadcast Hash join计算发生在本地的executors上,不需要shuffle,并行度也非常的高。
Spark通过spark.sql.autoBroadcastJoinThreshold参数(默认10MB),将小表广播出去。
以下是某个Spark SQL的执行计划,在该SQL中Spark选择logdate_xxx_t2表作为广播表。
== Physical Plan ==Execute CreateHiveTableAsSelectCommand CreateHiveTableAsSelectCommand [Database:default},TableName: logdate_xxx_dwd, InsertIntoHiveTable]+- *(1) Project [x3#29, x4#30, x5#31, x6#33, CASE WHEN isnotnull(x7#35) THEN 1 ELSE 0 END AS flag#26]+- *(1) BroadcastHashJoin [x4#30, x3#29], [x4#35, x3#34],LeftOuter, BuildRight:- HiveTableScan [x3#29, x4#30, x5#31, x6#33], HiveTableRelation `default`.`logdate_xxx_ods`,org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [x3#29, x4#30, x5#31, x6#33], [x6#33]+- BroadcastExchange HashedRelationBroadcastMode(List(input[1, string, true], input[0, string, true]))+- HiveTableScan [x1#34, x2#35], HiveTableRelation`default`.`logdate_xxx_t2`,org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [x1#34, x2#35]
Shuffle Hash join
1. shuffle阶段:根据join的key,把参与join的表的数据分为若干个区(默认使用的是hash partitonner),使得两个表相同的key进入同一个partition;
2. Hash join阶段:每个分区做基本的Hash join。
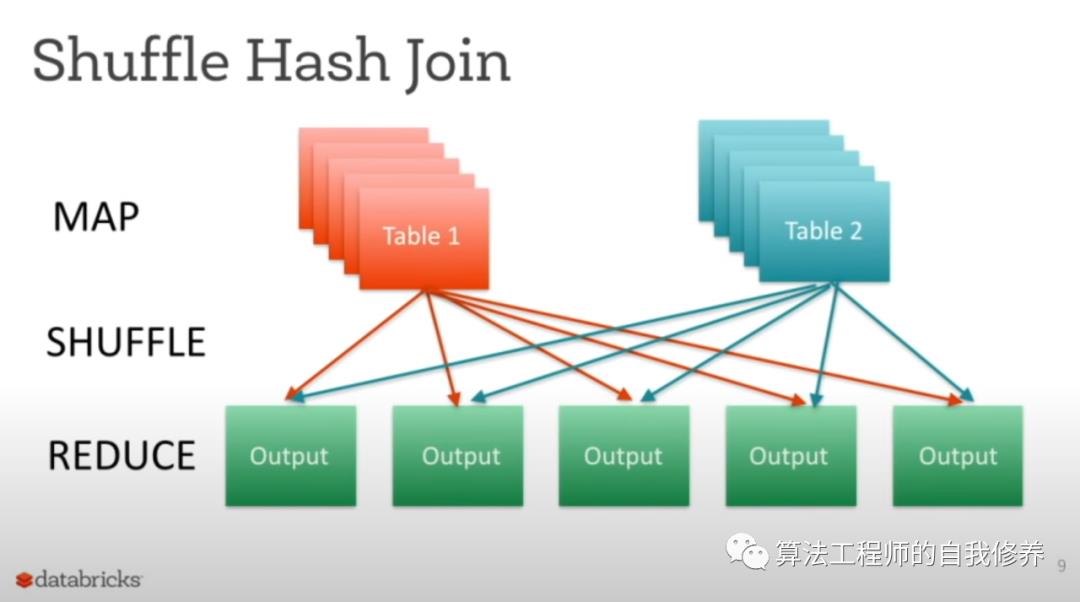
Shuffle Hash join存在数据倾斜的问题。数据倾斜是在实践中碰到最多的问题之一。
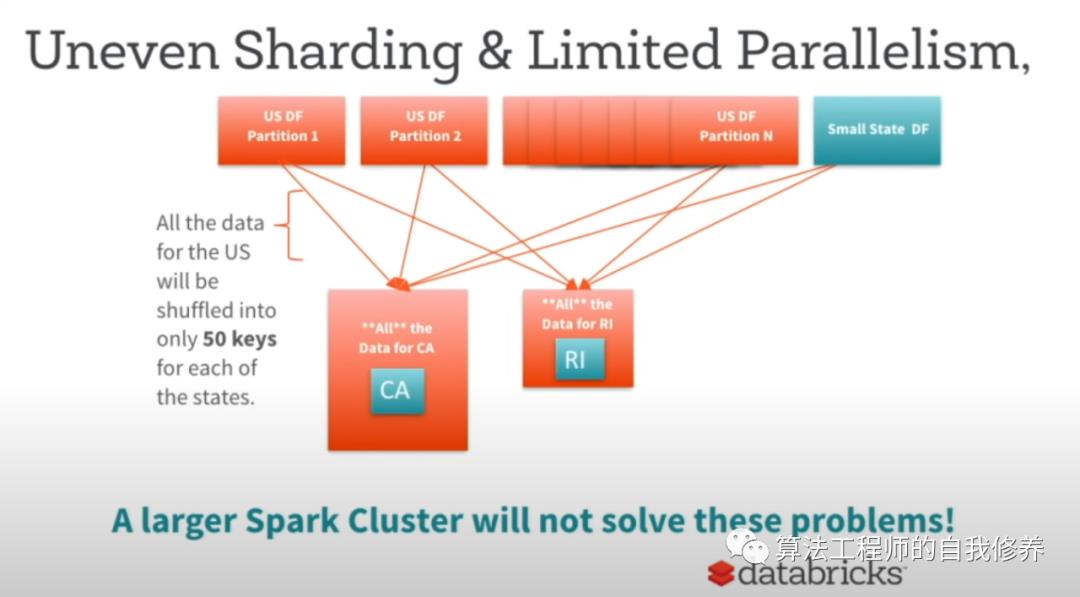
如何使得Shuffle Hash join更高效?首先要明白Shuffle Hash join的瓶颈在哪里:
1. 数据分布,准确来说应该是参与join的key的分布,对Shuffle Hash join性能有极大的影响,具体表现在大部分Task执行的速度非常快,而某个Task执行地非常慢,Spark UI中可以观察到该任务Shuffle的数据量非常的大
2. Shuffle Hash join存在并行度不够的问题。
databricks的工程师在演讲中提到如下几种方法:
Shuffle Hash join有非常多优化的手段,比如在数据储存方面,Spark 推荐使用parquet文件格式,parquet文件格式能够让Spark非常高效自动地识别用Shuffle join还是Broadcast join,而且parquet格式对重复数据的encoding非常地友好,输出的数据量会小一点;Spark默认的并行度为200,把key的分区重新打乱,增大并行度;Spark的新特性adaptive shuffling,动态地调整执行计划和分区数。
Sort Merge join
跟MR中Reduce join非常相似,回顾MR的执行过程。
1. shuffle阶段:跟Shuffle Hash join一样;
2. sort阶段:每个分区对key进行排序(MR框架中,默认会在溢写阶段对分区内的数据进行排序,这是为了方便后续同一个key进入一个分区);
3. merge阶段:两个sorted 的数据进行查找,线性复杂度。
Spark SQL 默认的join策略为Sort Merge join。该策略要求key要可排序,基本数据类型都是可排序的。
当Hash表无法放入内存或者构建Hash表的时间比排序时间长的时候,使用Sort Merge join是一种好的选择。
Nested Loop Join & Cartesian join
对参与join的所有表做Cartesian的遍历,适用范围最广,复杂度最高,速度最慢。
感悟
刚学Spark的时候,总是能搜到databricks的博客,最近懵懵懂懂看了一两篇,写得真的不错,尽管大部分内容还是不太懂。
老祖宗说的好呀,知其然,知其所以然,深入之后才发现,掌握的知识水平测度为零。
PS:放上代码,就是为了凑篇幅。
以上是关于Spark中的join策略的主要内容,如果未能解决你的问题,请参考以下文章