Spark高频面试题(建议收藏)
Posted 大数据肌肉猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark高频面试题(建议收藏)相关的知识,希望对你有一定的参考价值。
一、你是怎么理解Spark,它的特点是什么?
Spark是一个基于内存的,用于大规模数据处理(离线计算、实时计算、快速查询(交互式查询))的统一分析引擎。
它内部的组成模块,包含SparkCore,SparkSQL,SparkStreaming,SparkMLlib,SparkGraghx等...
它的特点:
-
快
Spark计算速度是MapReduce计算速度的10-100倍
-
易用
MR支持1种计算模型,Spsark支持更多的计算模型(算法多)
-
通用
Spark 能够进行离线计算、交互式查询(快速查询)、实时计算、机器学习、图计算
-
兼容性
Spark支持大数据中的Yarn调度,支持mesos。可以处理hadoop计算的数据。
二、Spark有几种部署方式,请分别简要论述
1) Local:运行在一台机器上,通常是练手或者测试环境。
2)Standalone:构建一个基于Mster+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark自身的一个调度系统。
3)Yarn: Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
4)Mesos:国内大环境比较少用。
三、Spark提交作业的参数
因为我们Spark任务是采用的Shell脚本进行提交,所以一定会涉及到几个重要的参数,而这个也是在面试的时候容易被考察到的“细节”。
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个,我们企业是4个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
四、简述Spark的作业提交流程
Spark的任务提交方式实际上有两种,分别是YarnClient模式和YarnCluster模式。大家在回答这个问题的时候,也需要分类去介绍。千万不要被冗长的步骤吓到,一定要学会总结差异,发现规律,通过图形去增强记忆。
-
YarnClient 运行模式介绍
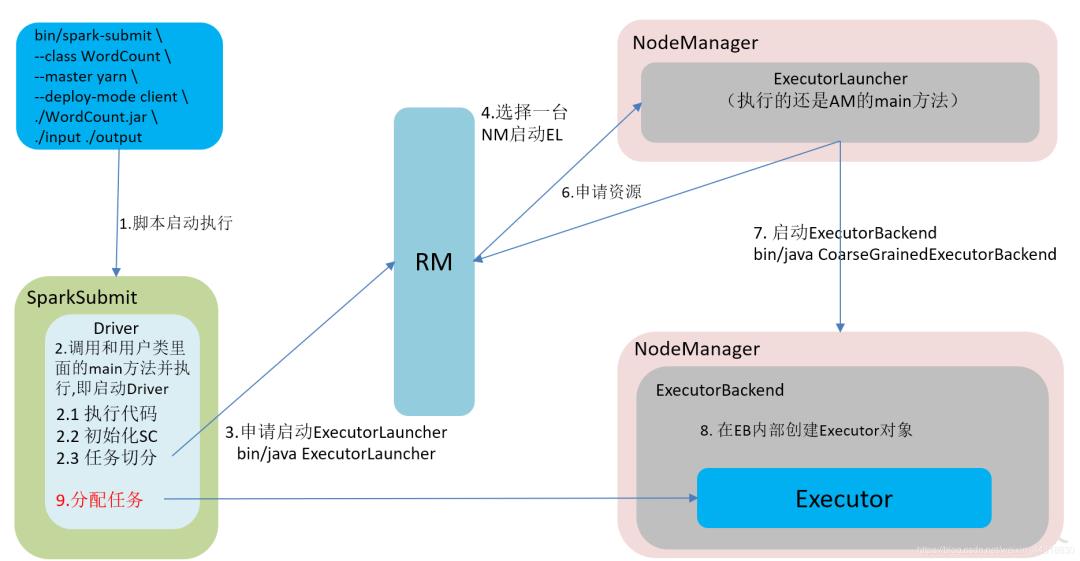 在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
-
YarnCluster 模式介绍
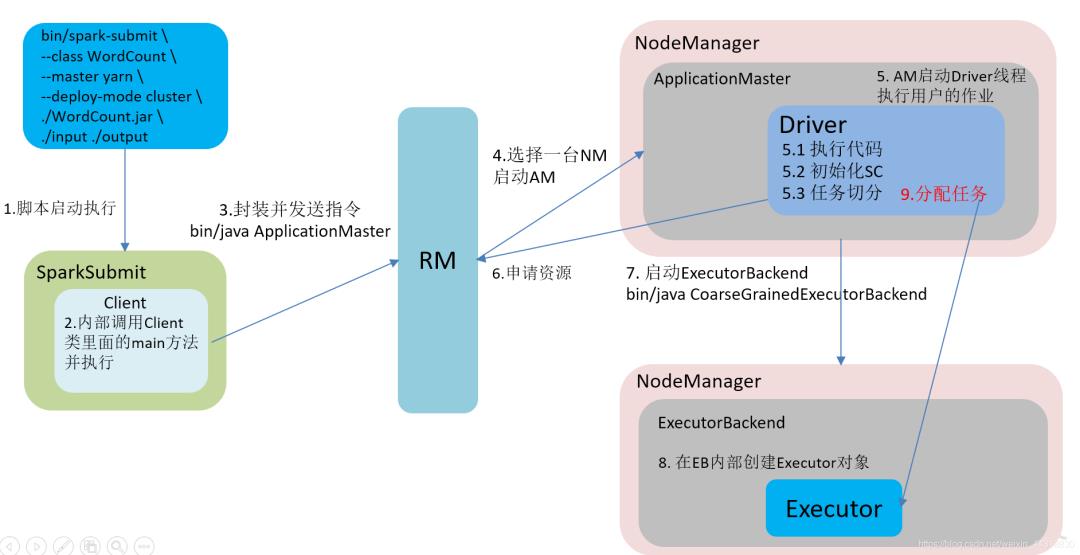 在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
五、你是如何理解Spark中血统(RDD)的概念?它的作用是什么?
RDD 可是Spark中最基本的数据抽象,我想就算面试不被问到,那自己是不是也应该非常清楚呢!
下面提供菌哥的回答,供大家参考:
-
概念
RDD是弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算 的集合。
-
作用
提供了一个抽象的数据模型,将具体的应用逻辑表达为一系列转换操作(函数)。另外不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy...)
如果还想锦上添花,可以添上这一句:
“RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies,用来解决数据容错时的高效性以及划分任务时候起到重要作用
”
六、简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
Spark的宽窄依赖问题是SparkCore部分的重点考察内容,多数出现在笔试中,大家需要注意。
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
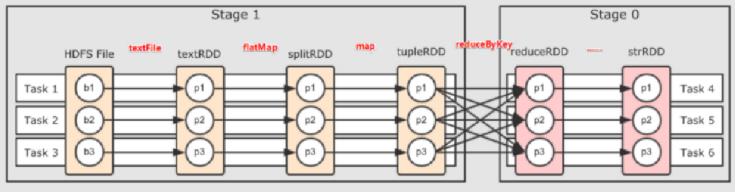
那Stage是如何划分的呢?
根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
每个stage又根据什么决定task个数?
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
这里为了方便大家理解,贴上一张过程图
七、列举Spark常用的transformation和action算子,有哪些算子会导致Shuffle?
我们在Spark开发过程中,避不开与各种算子打交道,其中Spark 算子分为transformation 和 action 算子,下面列出一些常用的算子,具体的功能还需要小伙伴们自行去了解。
transformation
-
map
-
mapRartition
-
flatMap
-
filter
-
...
action
-
reduce
-
collect
-
first
-
take
-
...
如果面试官问你,那小伙几,有哪些会引起Shuffle过程的Spark算子呢?
你只管自信的回答:
-
reduceByKey -
groupByKey -
...ByKey
八、reduceByKey与groupByKey的区别,哪一种更具优势?
既然你上面都提到 reduceByKey 和groupByKey ,那哪一种更具优势,你能简单分析一下吗?
能问这样的问题,已经暗示面试官的水平不低了,那么我们该如何回答呢:
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle
所以,在实际开发过程中,reduceByKey比groupByKey,更建议使用。但是需要注意是否会影响业务逻辑。
九、Repartition和Coalesce 的关系与区别,能简单说说吗?
这道题就已经开始掺和有“源码”的味道了,为什么呢?
1)关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce 根据传入的参数来判断是否发生shuffle。
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce。
十、简述下Spark中的缓存(cache和persist)与checkpoint机制,并指出两者的区别和联系
关于Spark缓存和检查点的区别,大致可以从这3个角度去回答:
-
位置
Persist 和 Cache将数据保存在内存,Checkpoint将数据保存在HDFS
-
生命周期
Persist 和 Cache 程序结束后会被清除或手动调用unpersist方法,Checkpoint永久存储不会被删除。
-
RDD依赖关系
Persist 和 Cache,不会丢掉RDD间的依赖链/依赖关系,CheckPoint会斩断依赖链。
十一、简述Spark中共享变量(广播变量和累加器)的基本原理与用途
关于Spark中的广播变量和累加器的基本原理和用途,答案较为固定,大家无需刻意去记忆。
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
广播变量是在每个机器上缓存一份,不可变,只读的,相同的变量,该节点每个任务都能访问,起到节省资源和优化的作用。它通常用来高效分发较大的对象。
十二、当Spark涉及到数据库的操作时,如何减少Spark运行中的数据库连接数?
嗯,有点“调优”的味道,感觉真正的“风暴”即将到来,这道题还是很好回答的,我们只需要减少连接数据库的次数即可。
使用foreachPartition代替foreach,在foreachPartition内获取数据库的连接。
十三、能介绍下你所知道和使用过的Spark调优吗?
恐怖如斯,该来的还是会来的,庆幸自己看了菌哥的面试杀招,丝毫不慌: 
资源参数调优
-
num-executors:设置Spark作业总共要用多少个Executor进程来执行 -
executor-memory:设置每个Executor进程的内存 -
executor-cores:设置每个Executor进程的CPU core数量 -
driver-memory:设置Driver进程的内存 -
spark.default.parallelism:设置每个stage的默认task数量 -
...
开发调优
-
避免创建重复的RDD -
尽可能复用同一个RDD -
对多次使用的RDD进行持久化 -
尽量避免使用shuffle类算子 -
使用map-side预聚合的shuffle操作 -
使用高性能的算子
“①使用reduceByKey/aggregateByKey替代groupByKey
②使用mapPartitions替代普通map
③使用foreachPartitions替代foreach
④使用filter之后进行coalesce操作
⑤使用repartitionAndSortWithinPartitions替代repartition与sort类操作
”
-
广播大变量
“在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能。
”
-
使用Kryo优化序列化性能 -
优化数据结构
“在可能以及合适的情况下,使用占用内存较少的数据结构,但是前提是要保证代码的可维护性。
”
如果能够尽可能的把这些要点说出来,我想面试官可能就一个想法:
十四、如何使用Spark实现TopN的获取(描述思路或使用伪代码)?
能让你使用伪代码来描述这已经非常“苛刻”了,但是不慌,这里提供3种思路供大家参考:
-
方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)
注意:当数据量太大时,会导致OOM
-
方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
-
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
--end--
以上是关于Spark高频面试题(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章
急急急!高频面试题 数据库必问——MySQL篇(基本已完结,建议收藏)
❤️五万字❤️离职后一天4面,总结了204道高频Java面试题,已拿阿里offer(建议收藏)
不积跬步无以至千里,不积小流无以成江海,大数据高频面试题——Hive篇用心整理23题,建议收藏!