大咖聊技术 | 浅谈Spark数据倾斜
Posted 百威亚太数据科学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大咖聊技术 | 浅谈Spark数据倾斜相关的知识,希望对你有一定的参考价值。
前言
无论是Machine Learning,Data Analysis,还是其他跟数据打交道的工作,都绕不开数据处理这个环节;而处理的数据量难免会增大到超出单机处理的极限,这时候就需要计算机集群来帮我们解决问题,也就需要用到大数据技术。
Spark介绍
为了解决Hadoop大数据作业处理过程中由于频繁读写HDFS等原因导致的耗时过长的缺点,UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)于2009年开发并于2010年初开源了类Hadoop MapReduce的通用并行框架Spark,该项目于2013年成为了Apache基金会下的项目,进入高速发展期。2014年成为Apache顶级项目。到目前为止已经有大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。
什么是数据倾斜
Hadoop,Spark等大数据计算框架的优势在于对数据分而治之,利用物理分离的多台机器并发处理同一计算任务,从而达到成倍缩减总耗时。例如一个在单机上需要180分钟才能计算完成的任务,如果交给一个有3个节点的分布式系统,理论上总的耗时应该在180/3=60分钟左右。
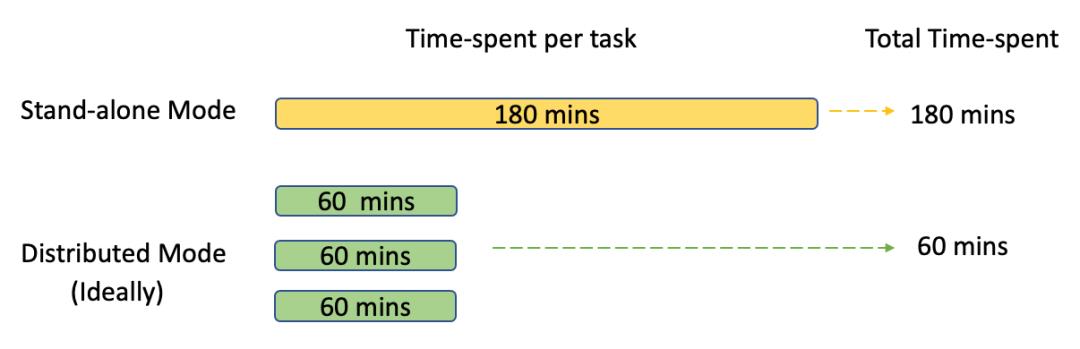
然而实际上,由于各种原因导致分配到每个节点的计算任务不一定是一样的,有时甚至会相差,所以上述例子的实际耗时可能是130分钟。
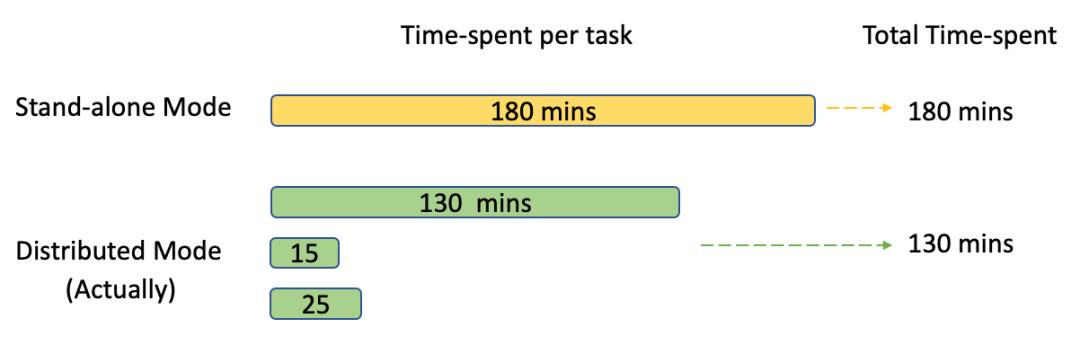
这些原因有的是来自集群节点的计算资源管理不均衡导致,往往在实际应用中一个集群机器不止部署一种大数据框架,每一个大数据系统也可能同时处理多个提交上来的计算任务。针对这些Spark也有超时重算机制来应对这种特殊情况,另外也有很多资源管理框架能集中管理各种大数据框架并存的情况。还有一些原因是来自节点接收到的数据量大小有所差异造成的。
由于各种原因导致的每个数据分片(Spark里的Partition)里的数据量有着显著的差异,这种情况就叫数据发生倾斜问题,简称数据倾斜。
出现数据倾斜的原因
数据倾斜来源于数据源
Spark的一个数据来源是读取数据文件,这些文件可分为可切分的文件(例如:文本文件)和不可切分的文件(例如:压缩文件)。对于可切分的文件,Spark会根据框架配置的blocksize大小对这些文件进行切分,每一份是一个blocksize大小;而对于不可切分的文件,Spark只能启动一个task单独完成该文件的计算任务。
如果Spark的数据源是对接一些流数据框架,例如Kafka等。由于Kafka里的Partition跟Spark一一对应,因此Kafka里相关Topic的各个Partition之间如果出现数据分布不均衡,那么就会造成Spark数据倾斜问题。
Shuffle过程导致数据倾斜
MapReduce框架在Map阶段结束,Reduce开始前会根据需要对Map Output结果做Shuffle操作,将数据块输送到对应的Reduce节点。
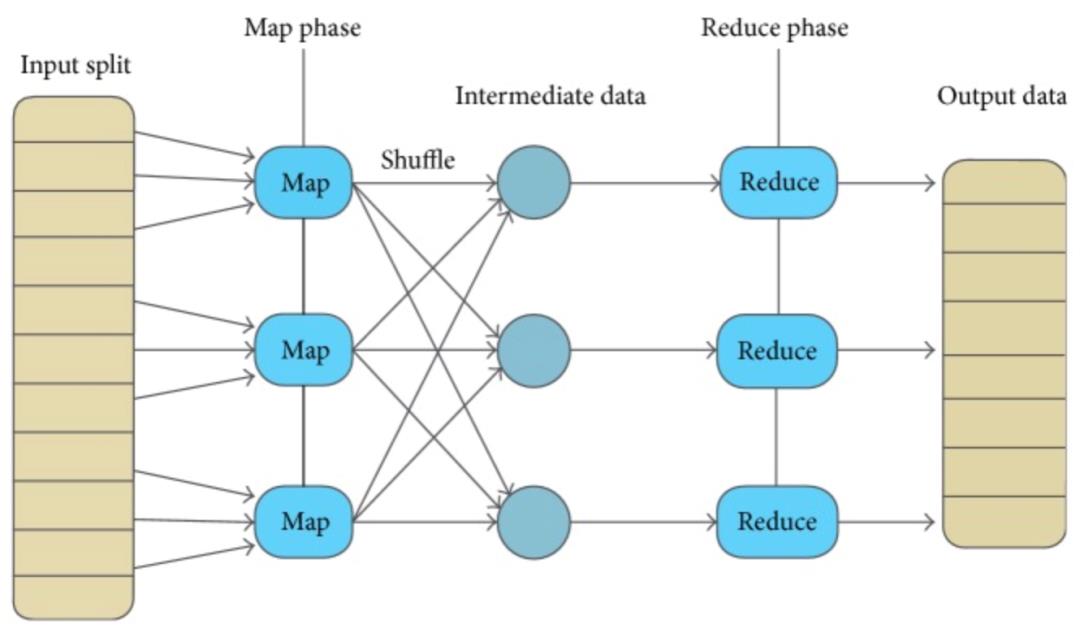
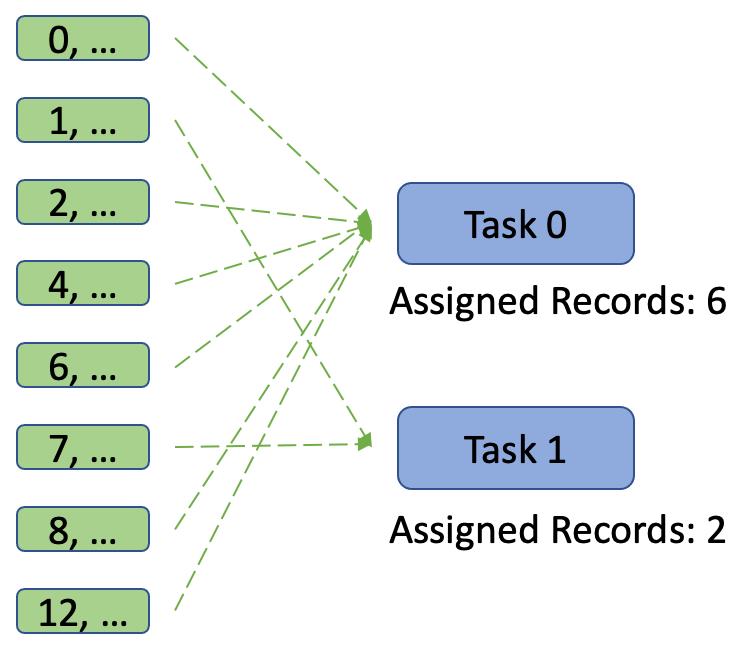
Spark的Shuffle默认使用HashPartitioner对数据进行分区,这时如果Reduce并行度设置不恰当的话,就有可能导致大量不同Key的数据被分配到同一个reduce task上,从而造成数据倾斜。
解决方案
解决Spark系统发生的数据倾斜,需要结合数据的特点:数据源、数据分布、数据结构,从数据倾斜刚发生的环节着手。
对于数据源导致的数据倾斜,在数据生成端,尽量使用支持可切分的文件格式,例如可在开始处理前先将压缩文件解压成可切分的文本文件。或确保各文件包含的数据量大致相同。对于数据源来源于外部系统的则需要外部系统(如:Kafka等)的支持。
对于Shuffle过程导致的数据倾斜,一般都是具体问题具体分析,采用的方法也没有固定,以下总结一些比较实用的方法:
修改并行度
例如上一节提到的例子,由于Key的分布问题导致partition后的任务分布不均匀的问题,可以通过修改并行度的方式分散原本分布在同一个task的数据。可通过修改Spark集群的有些配置选项来变更集群的并行度,如spark.default.parallelism、spark.sql.shuffle.partitions等。
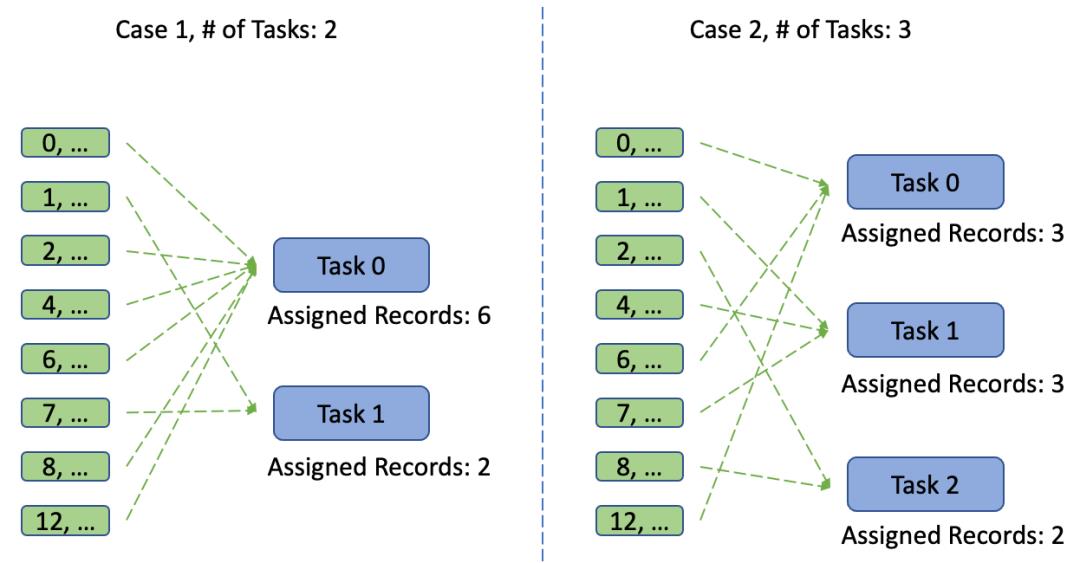
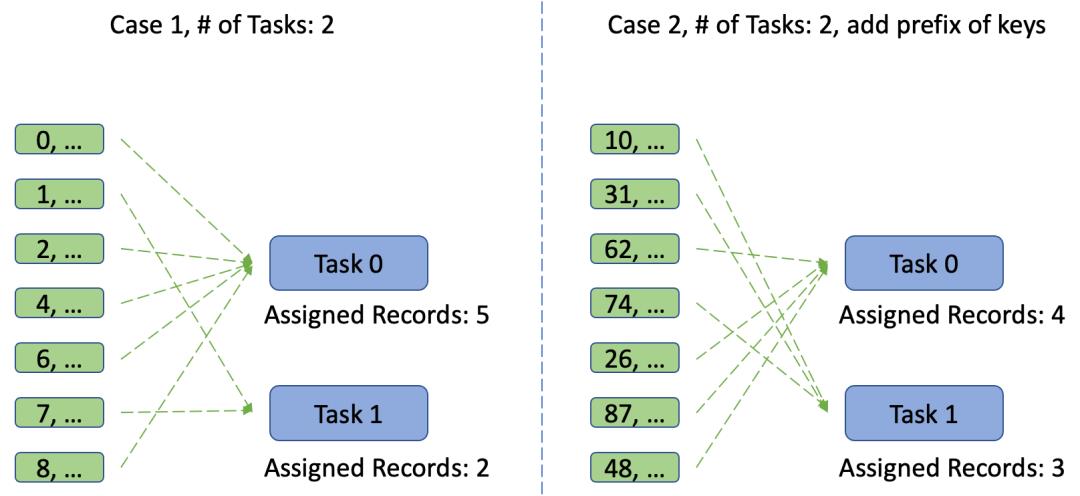
添加随机前缀
另外,上述例子也可以通过增加随机前缀的方式解决这样的数据倾斜问题,这样一来我们不需要修改系统的并行度设置,只是通过对key添加随机的前缀,即使使用默认的HashPartitioner对数据进行分片,也不再出现数据倾斜的问题了。
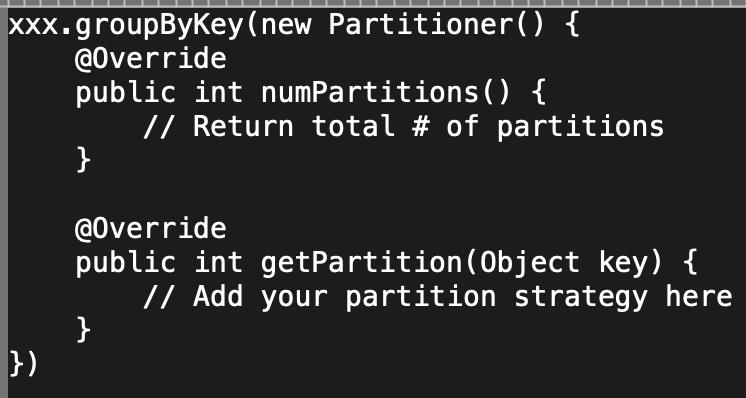
自定义分片器Partitioner
当然,还可以修改默认的Partitioner分片器,构造自己的分片器,覆盖里面的getPartition方法,实现自定义的分配策略,也能解决这些数据倾斜的问题。
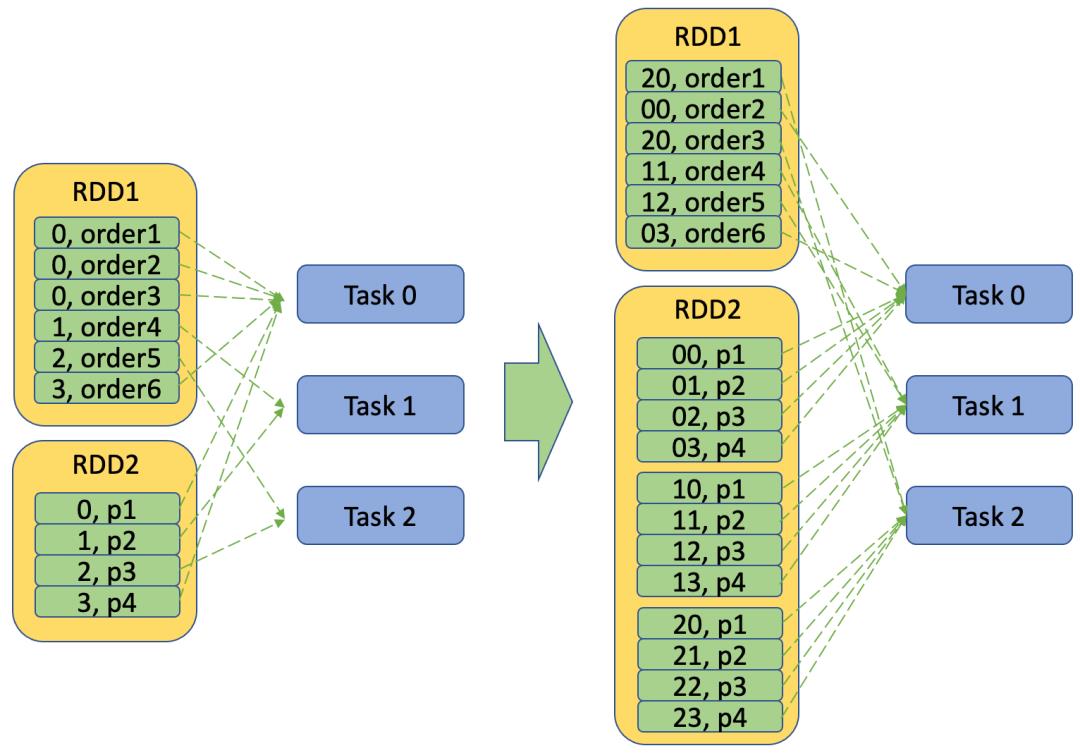
大表join小表,大表随机添加N种前缀,小表复制N倍
当大表 join小表,且出现数据倾斜的key比较多的时候,这时就可以对大表随机添加N种前缀,N是节点个数,目的就是为了能较均匀地重新分配到各个节点,同时对于小表可以随机扩张N倍,相当于Broadcast到各个节点,这样一来虽然会造成数据冗余,但却能让join操作在本地进行,缩短任务的时间消耗。
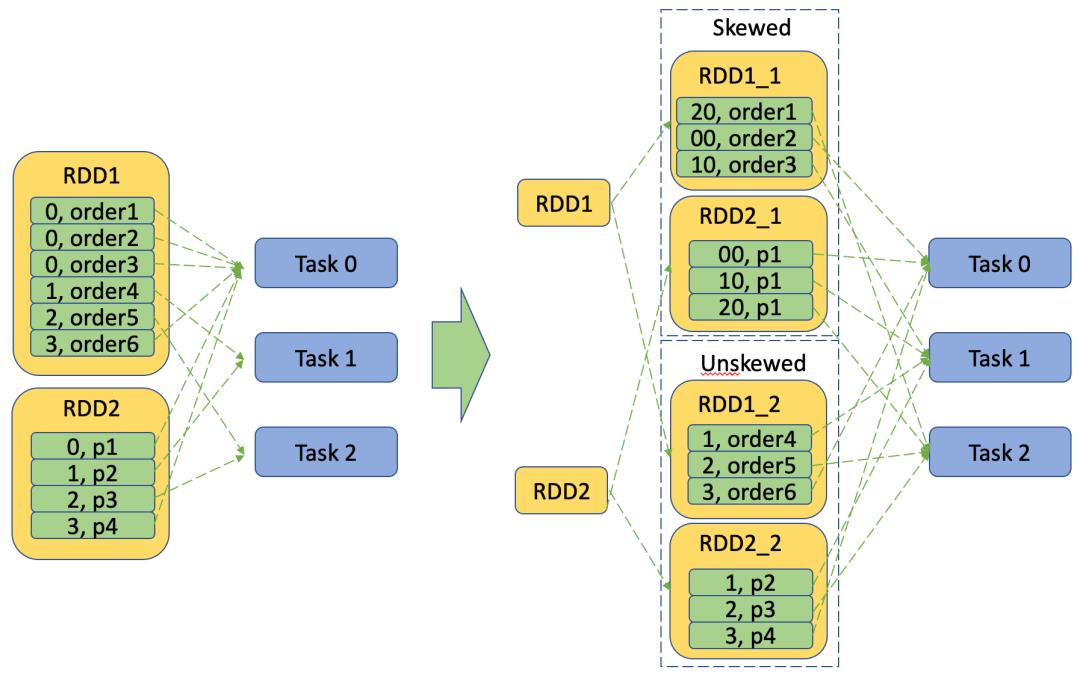
数据倾斜的Key单独处理,随机增加前缀重新平衡压力
当发生倾斜的key数量不多的时候,可以单独分裂成2个RDD,一个是所有Skewed Key的数据,另一个是所有Unskewed Key的数据集,并对要与之Join的数据集也做相应的RDD裂变,再分别Join,最后将最终结果集Merge成一个Output数据集。对于倾斜数据集则采用方法四进行Join,而对非倾斜数据集则采用普通的Join方式。这样一来倾斜数据集也可与非倾斜数据集并行处理,提升整体效率。
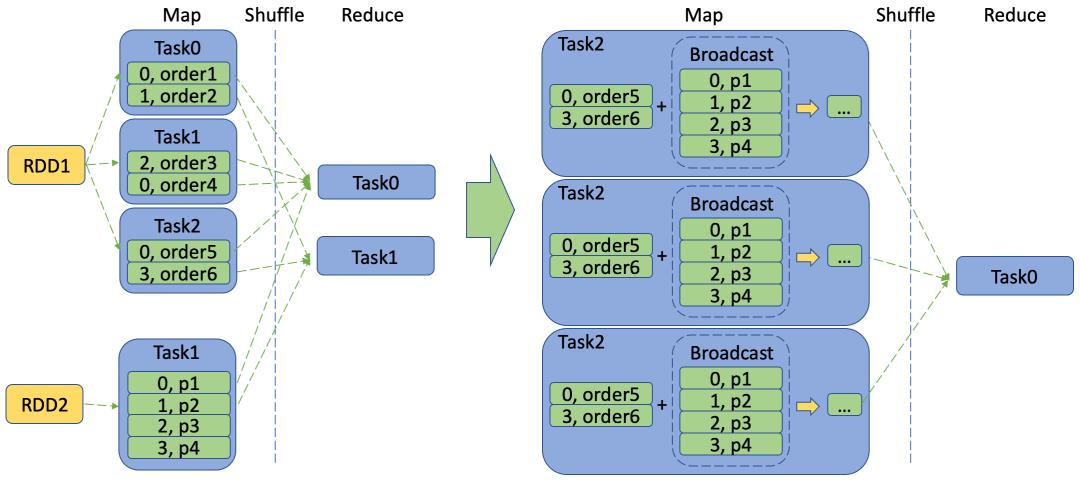
将 reduce join 转化为 map join
当大表 join小表的时候,例如订单表和商品表,订单表通常都是千万级甚至亿级的,而商品表通常只有几百数千条记录,通常都是对这两张表按照他们的关联字段(商品ID)做Partition,然后将相应的分片分发到对应的Reduce节点去(Shuffle阶段),最后再在各个Reduce节点上启动job执行相关的计算任务(将各个Reduce节点上的订单表数据块和商品表数据块按商品ID关联成一张表,再合并各个节点的结果成为一张完整表作为输出结果)。
这个过程可能会存在两个性能问题:一个是可能会有大量的订单关联同一款商品(比如大促的热门商品),这时候可以通过上述几种方法对热门key进行分拆的方式分摊节点计算压力;另一个性能问题是大量的订单由于需要通过网络通道shuffle到相应的reduce节点,大数据量会给集群网络造成巨大的传输压力,时间开销也因此剧增。如果能在shuffle前先减少数据量,将会大大缩短任务的时间开销。
Spark集群提供了Broadcast机制,允许用户将小表复制到各个Map节点上,这样一来就能在map阶段将各自Map节点上的订单表与商品表执行join操作,再截取需要的字段作为map阶段的output输出到reduce,这样就能解决由于shuffle造成的数据倾斜,也大大减少shuffle需要传输的数据量,从而缩减任务计算时间。
解决数据倾斜的好处
更好地优化计算任务,避免了由于数据分布不均导致少数几个task的执行时间过长,从而影响整个任务的总运行时间。
也避免了某个节点由于处理的数据过多而导致的OutOfMemory异常退出。
- END -
本期员工大咖
Mr. Songmao Wu
Bachelor, Information and Computation Science, Hubei Normal University
以上是关于大咖聊技术 | 浅谈Spark数据倾斜的主要内容,如果未能解决你的问题,请参考以下文章