Spark原理与实战-- Spark核心数据抽象RDD
Posted DLab数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark原理与实战-- Spark核心数据抽象RDD相关的知识,希望对你有一定的参考价值。
导读:前面三节分别从SparkCore、SparkStreaming以及GraphX三个组件角度讲解了Spark不同核心组件的入门案例实战,通过这三个案例可以迅速run起来一个Spark程序,并且大致了解Spark的运行机制。从本节开始,将会从头开始来构建一个Spark学习体系。
数据抽象
RDD
本节首先来讲RDD,RDD诞生早于SparkSQL, 属于Core Spark. 他的入口是SparkContext. 在Spark各种语言中都可以使用,包括Scala,python,java。DataFrame和Dataset是RDD的更高级抽象,RDD是他们的基础。
一、RDD介绍
1.RDD(Resilient Distributed Dataset)
Resilient: 如果内存中数据丢失,可以方便重建
Distributed: 数据分布于集群各节点
Dataset: 初始数据可以来自外部文件系统或者内存数据结构
2.RDD是非结构化数据
没有Schema文件来定义他的行或者列的类型,可以包含各种类型的数据
不像数据表,不能执行类似SQL的查询,使用函数
RDD的执行计划没有被Catalyst优化器优化过,所以一般手写代码效率没有DataFrame效率高
3.RDD的数据类型
原始类型比如integers, characters, Booleans
集合类型比如: sting, list, array, tuple, dictionaries
嵌套集合类型
Scala/Java对象
混合类型
4.RDD的数据源
文件,textfile或者其他类型的文件.
使用textFile或者wholeTextFile读取text文件
使用hadoopFile或者newAPIHadoopFile来读取其他格式的文件
内存中数据结构
其他RDD
DataFrame或者Dataset
二、RDD创建
1.通过本地集合序列化创建
val rdd = spark.sparkContext.parallelize(Seq(
Row(1,"mark",27),
Row(2,"shie",43),
Row(3,"yuli",39)
))
或
val rdd = spark.sparkContext.parallelize(Array(1,2,3,4))
rdd.foreach(println)
结果:
[1,mark,27]
[2,shie,43]
[3,yuli,39]
2.通过读取外部数据文件
val rdd = spark.sparkContext.textFile("file:///D:/projSrc/data/wordcount.txt")
rdd.foreach(println)
结果:
id,name,age
1,mark,27
2,jony,34
3,july,23
3.通过RDD变换,从一个RDD转为另一个新的RDD
val rdd2 = rdd1.map(x=>x)
4.从DataFrame转为RDD
(需要引入spark.implicit._隐式转换)
DataFrame.toRDD
三、RDD使用
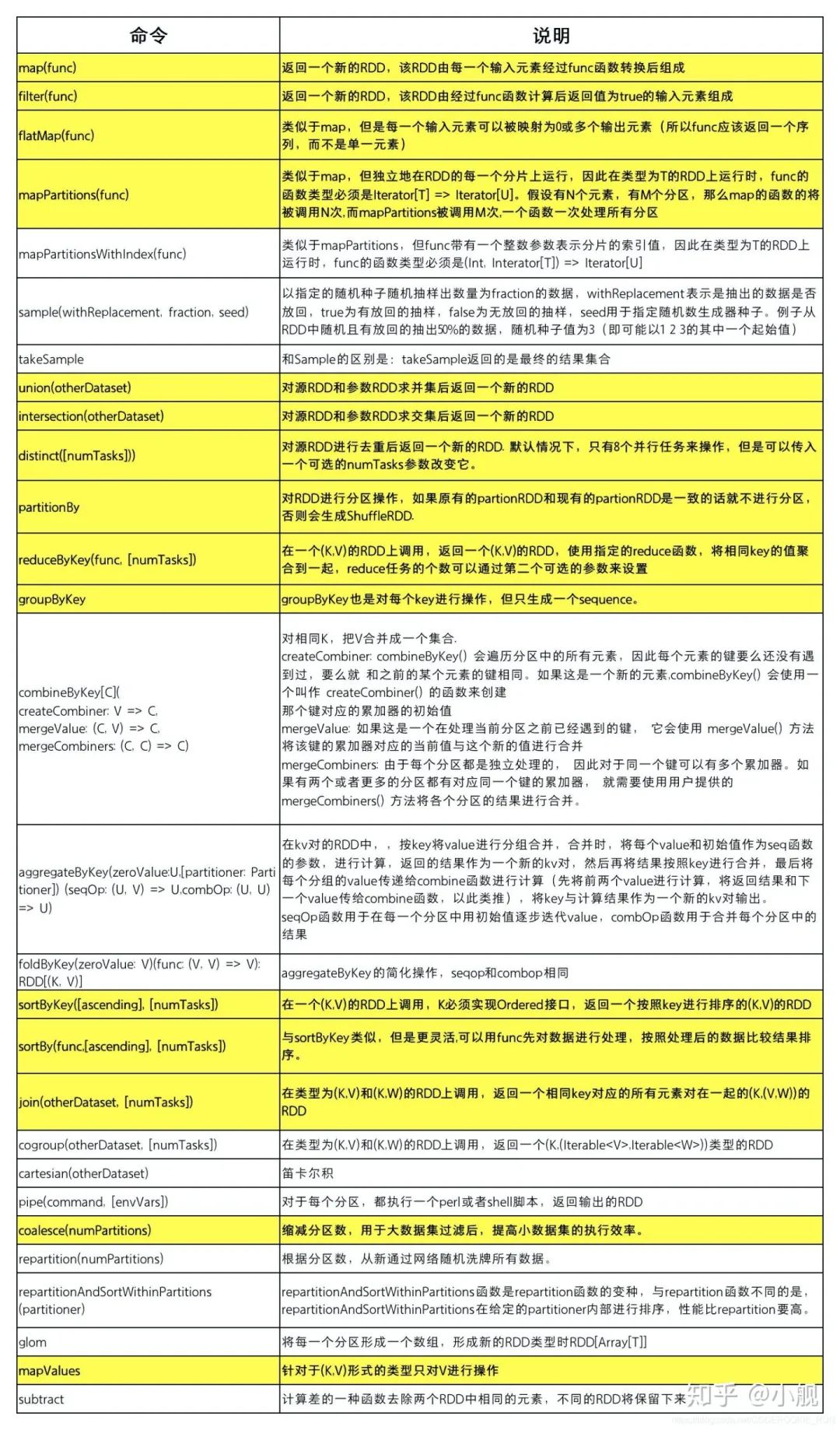
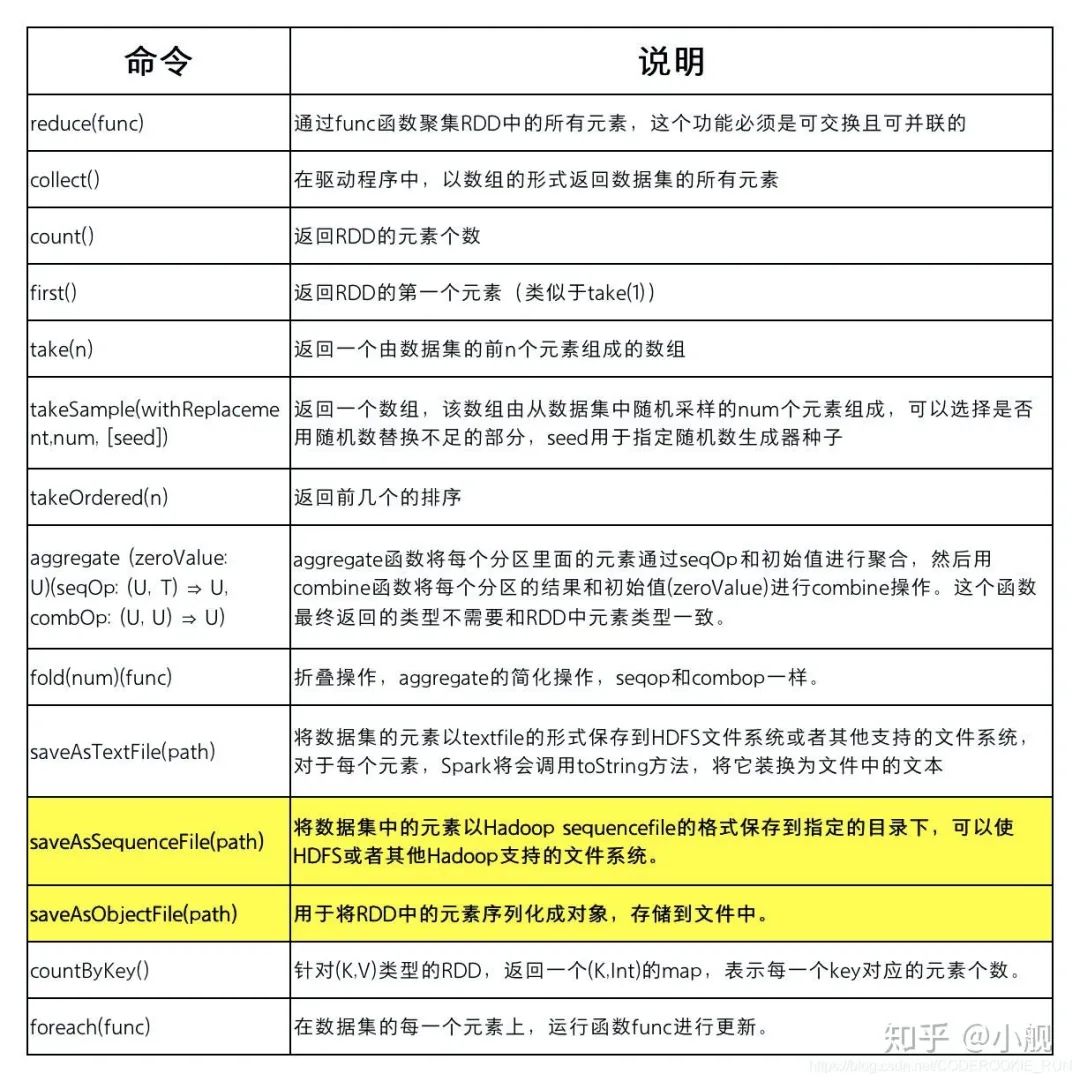
RDD的操作主要分为Transformation算子和Action算子两类。我们在使用的时候,可以参照下面的两张表来根据不同的处理需要选取不同的处理算子。
1.Transformation算子
RDD中所有转换算子都是延迟加载,从一个RDD到另一个RDD转换没有立即转换,仅记录数据的逻辑操作,只有要求结果还回到Driver时的动作时才会真正运行。
2.Action算子
Action操作执行,会触发一个spark job的运行,从而触发这个Action之前所有的Transformation的执行。这是Action的特性。
以上就是Spark最重要的数据抽象之一RDD的介绍。我们在实际编程的时候,不必太关注RDD底层是如何进行数据分片和数据管理的,我们只需要在逻辑上把数据看作一个整体,然后调用各种算子进行业务逻辑处理即可。下一期,将继续介绍Spark的另一个重要的数据抽象DataFrame,欢迎关注!


文章都看完了不点个 吗
欢迎 点赞、在看、分享 三连哦~~
以上是关于Spark原理与实战-- Spark核心数据抽象RDD的主要内容,如果未能解决你的问题,请参考以下文章