Spark 中 JobStageTask 的划分+源码执行过程分析
Posted zhisheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 中 JobStageTask 的划分+源码执行过程分析相关的知识,希望对你有一定的参考价值。
系列文章
来源:https://blog.csdn.net/hjw199089/article/details/77938688


job、stage、task
-
Worker Node:物理节点,上面执行executor进程 -
Executor:Worker Node为某应用启动的一个进程,执行多个tasks -
Jobs:action 的触发会生成一个job, Job会提交给DAGScheduler,分解成Stage, -
Stage:DAGScheduler 根据shuffle将job划分为不同的stage,同一个stage中包含多个task,这些tasks有相同的 shuffle dependencies。有两类shuffle map stage和result stage: -
shuffle map stage:case its tasks' results are input for other stage(s) -
result stage:case its tasks directly compute a Spark action (e.g. count(), save(), etc) by running a function on an RDD,输入与结果间划分stage -
Task:被送到executor上的工作单元,task简单的说就是在一个数据partition上的单个数据处理流程。小结:
action 触发一个 job (task 对应在一个 partition 上的数据处理流程)
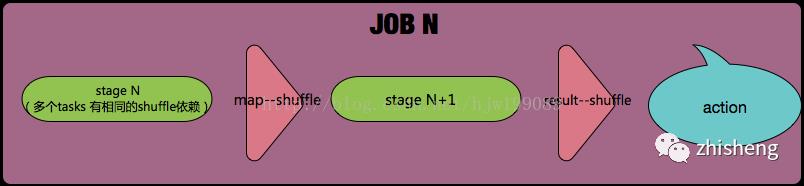
------stage1(多个tasks 有相同的shuffle依赖)------【map--shuffle】------- stage2---- 【result--shuffle】-----
【样例说明】
已下面的一段样例分析下具体的执行过程,为了分析,将map和reduce没有写成链式 data.txt数据如下,分别表示event uuid pv
1 1001 0
1 1001 1
1 1002 0
1 1003 1
2 1002 1
2 1003 1
2 1003 0
3 1001 0
3 1001 0
计算每个事件的uv和pv,即实现,event维度下,count(distinct if(pv > 0,uuid,null)) ,sum(pv)
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hjw on 17/9/11.
*
**/
/*
event uuid pv data.txt的数据
1 1001 0
1 1001 1
1 1002 0
1 1003 1
2 1002 1
2 1003 1
2 1003 0
3 1001 0
3 1001 0
计算 event,count(distinct if(pv > 0,uuid,null)) ,sum(pv)
2 UV=2 PV=2
3 UV=0 PV=0
1 UV=2 PV=2
为了分析,将map和reduce没有写成链式
*/
object DAG {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("test")
conf.setMaster("local")
val sc = new SparkContext(conf)
val txtFile = sc.textFile(".xxxxxx/DAG/srcFile/data.txt")
val inputRDD = txtFile.map(x => (x.split("\t")(0), x.split("\t")(1), x.split("\t")(2).toInt))
//val partitionsSzie = inputRDD.partitions.size
//这里为了分析task数先重分区,分区前partitions.size = 1,下面每个stage的task数为1
val inputPartionRDD = inputRDD.repartition(2)
//------map_shuffle stage 有shuffle Read
//结果:(事件-用户,pv)
val eventUser2PV = inputPartionRDD.map(x => (x._1 + "-" + x._2, x._3))
//结果: (事件,(用户,pv))
val PvRDDTemp1 = eventUser2PV.reduceByKey(_ + _).map(x =>
(x._1.split("-")(0), (x._1.split("-")(1), x._2))
)
//-------map_shuffle stage 有shuffle Read 和 有shuffle Write
//结果: (事件, Tuple2(Tuple2(用户,是否出现),该用户的pv) )
val PvUvRDDTemp2 = PvRDDTemp1.map(
x => x match {
case x if x._2._2 > 0 => (x._1, (1, x._2._2))
case x if x._2._2 == 0 => (x._1, (0, x._2._2))
}
)
//结果:(事件,Tuple2(uv,pv))
val PVUVRDD = PvUvRDDTemp2.reduceByKey(
(a, b) => (a._1 + b._1, a._2 + b._2)
)
//------result_shuffle stage 有shuffle Read
//--------触发一个job
val res = PVUVRDD.collect();
//------result_shuffle stage 有shuffle Read
//--------触发一个job
PVUVRDD.foreach(a => println(a._1 + "\t UV=" + a._2._1 + "\t PV=" + a._2._2))
// 2 UV=2 PV=2
// 3 UV=0 PV=0
// 1 UV=2 PV=2
while (true) {
;
}
sc.stop()
}
}
日志中拣选出关键分析点如下:
17/09/11 22:46:19 INFO SparkContext: Running Spark version 1.6.
17/09/11 22:46:21 INFO SparkUI: Started SparkUI at http://192.168.2.100:4040
17/09/11 22:46:21 INFO FileInputFormat: Total input paths to process : 1
17/09/11 22:46:22 INFO SparkContext: Starting job: collect at DAG.scala:69
17/09/11 22:46:22 INFO DAGScheduler: Registering RDD 3 (repartition at DAG.scala:42)
17/09/11 22:46:22 INFO DAGScheduler: Registering RDD 7 (map at DAG.scala:46)
17/09/11 22:46:22 INFO DAGScheduler: Registering RDD 10 (map at DAG.scala:55)
17/09/11 22:46:22 INFO DAGScheduler: Got job 0 (collect at DAG.scala:69) with 2 output partitions
17/09/11 22:46:22 INFO DAGScheduler: Final stage: ResultStage 3 (collect at DAG.scala:69)
17/09/11 22:46:22 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at repartition at DAG.scala:42), which has no missing parents
17/09/11 22:46:22 INFO DAGScheduler: ShuffleMapStage 0 (repartition at DAG.scala:42) finished in 0.106 s
17/09/11 22:46:22 INFO DAGScheduler: waiting: Set(ShuffleMapStage 1, ShuffleMapStage 2, ResultStage 3)
17/09/11 22:46:22 INFO DAGScheduler: Submitting ShuffleMapStage 1 (MapPartitionsRDD[7] at map at DAG.scala:46), which has no missing parents
17/09/11 22:46:22 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 1 (MapPartitionsRDD[7] at map at DAG.scala:46)
17/09/11 22:46:22 INFO DAGScheduler: ShuffleMapStage 1 (map at DAG.scala:46) finished in 0.055 s
17/09/11 22:46:22 INFO DAGScheduler: waiting: Set(ShuffleMapStage 2, ResultStage 3)
17/09/11 22:46:22 INFO DAGScheduler: Submitting ShuffleMapStage 2 (MapPartitionsRDD[10] at map at DAG.scala:55), which has no missing parents
17/09/11 22:46:22 INFO DAGScheduler: ShuffleMapStage 2 (map at DAG.scala:55) finished in 0.023 s
17/09/11 22:46:22 INFO DAGScheduler: Submitting ResultStage 3 (ShuffledRDD[11] at reduceByKey at DAG.scala:63), which has no missing parents
17/09/11 22:46:22 INFO DAGScheduler: ResultStage 3 (collect at DAG.scala:69) finished in 0.009 s
17/09/11 22:46:22 INFO DAGScheduler: Job 0 finished: collect at DAG.scala:69, took 0.283076 s
17/09/11 22:46:22 INFO SparkContext: Starting job: foreach at DAG.scala:74
17/09/11 22:46:22 INFO DAGScheduler: Got job 1 (foreach at DAG.scala:74) with 2 output partitions
17/09/11 22:46:22 INFO DAGScheduler: Final stage: ResultStage 7 (foreach at DAG.scala:74)
17/09/11 22:46:22 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 6)
17/09/11 22:46:22 INFO DAGScheduler: Submitting ResultStage 7 (ShuffledRDD[11] at reduceByKey at DAG.scala:63), which has no missing parents
17/09/11 22:46:22 INFO DAGScheduler: ResultStage 7 (foreach at DAG.scala:74) finished in 0.010 s
17/09/11 22:46:22 INFO DAGScheduler: Job 1 finished: foreach at DAG.scala:74, took 0.028036 s
line 69 collect() 和 line 74 行 foreach()触发两个job
val res = PVUVRDD.collect();
PVUVRDD.foreach(a => println(a._1 + "\t UV=" + a._2._1 + "\t PV=" + a._2._2))
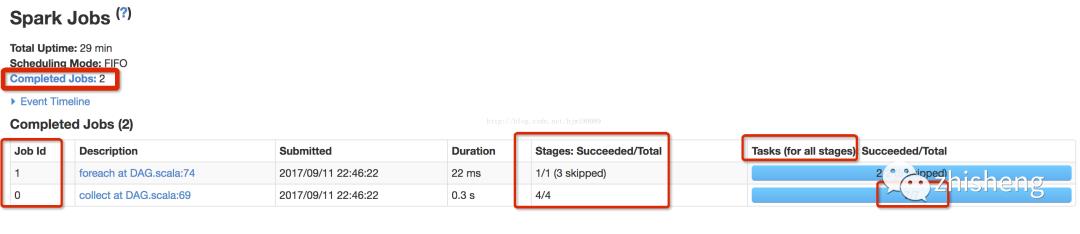
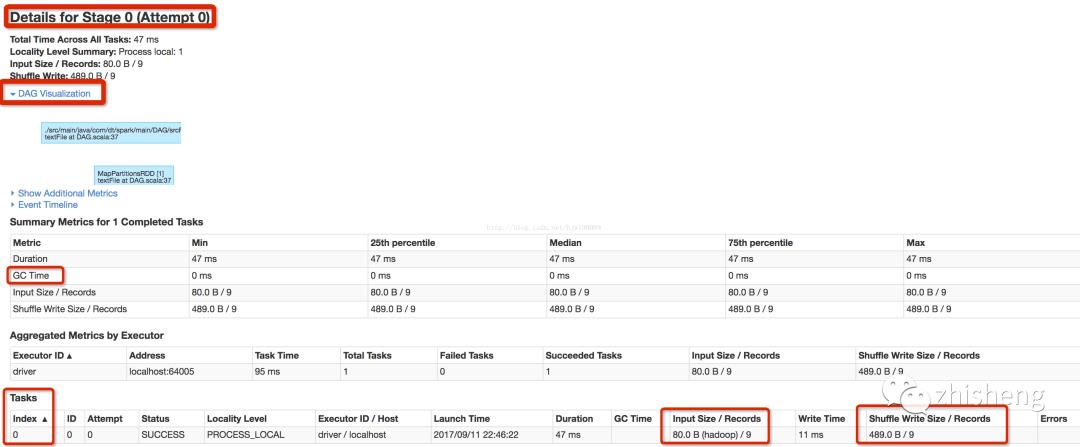
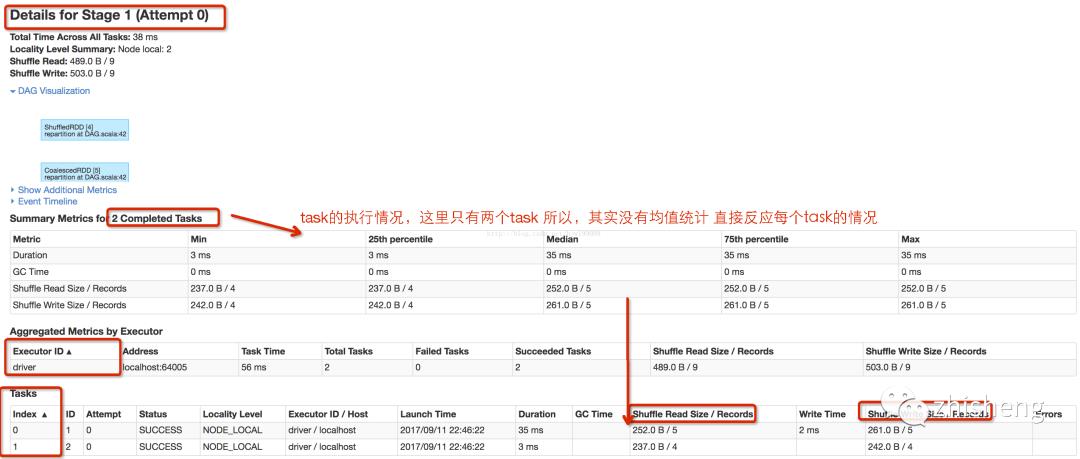
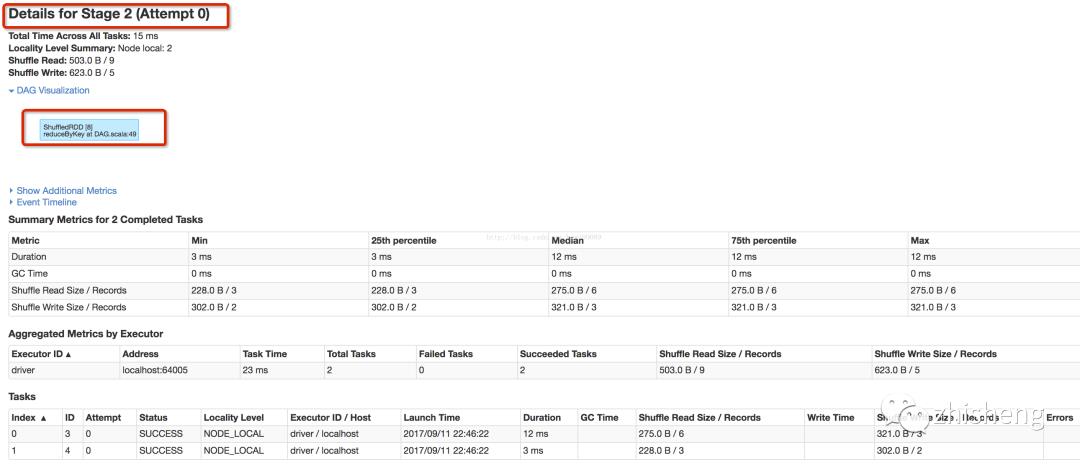
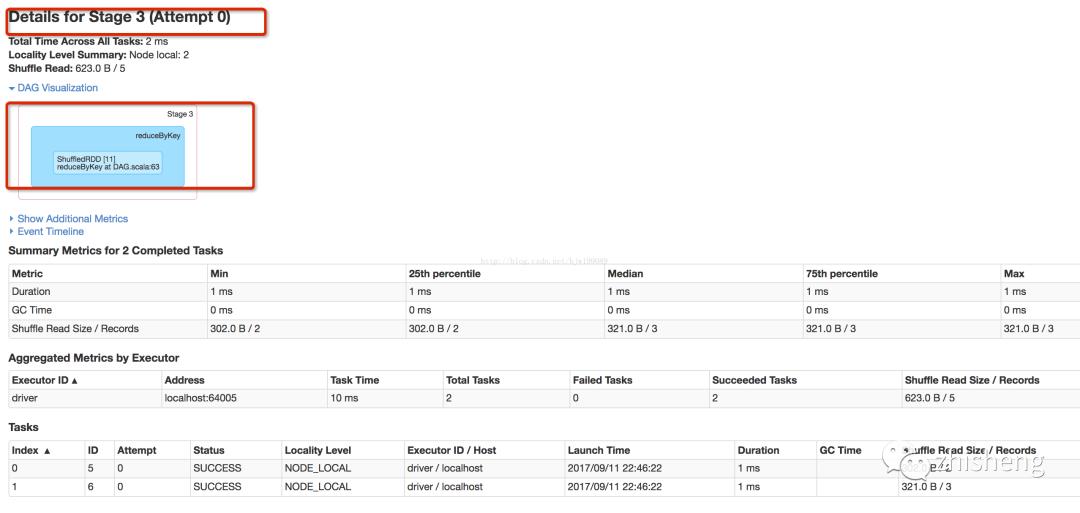
基于下图知
job0有4个stage,共7个task
-
stage0:1个分区有1个task执行 -
stage1--3:各有2个分区,各有2个task执行,共6个task
job1有1个stage(复用job0的RDD),有2个task
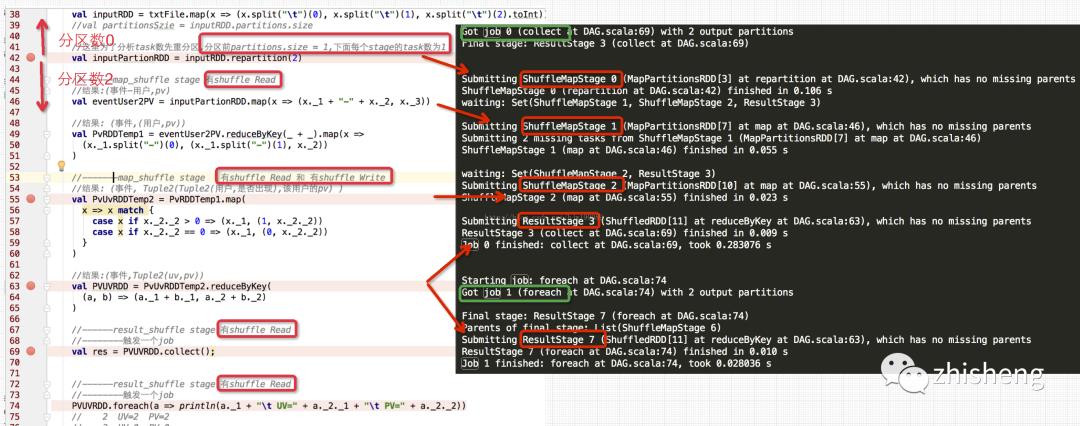
具体job0的细节
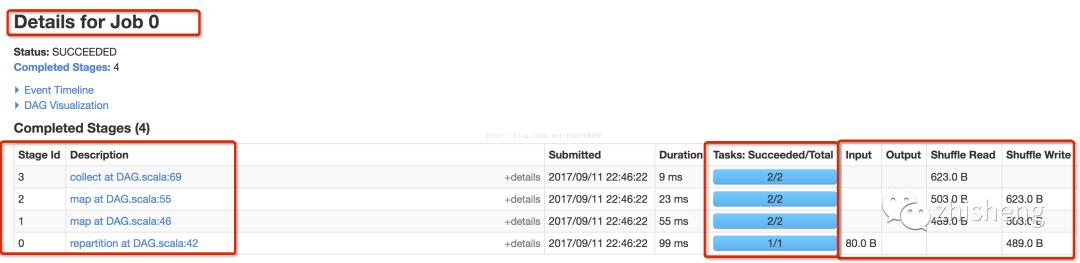
具体job0-stage0
1 1001 0
1 1001 1
1 1002 0
1 1003 1
2 1002 1
2 1003 1
2 1003 0
3 1001 0
3 1001 0
输入9条记录,只要一个分区,有一个task执行,想repartion进行shuffle写数据
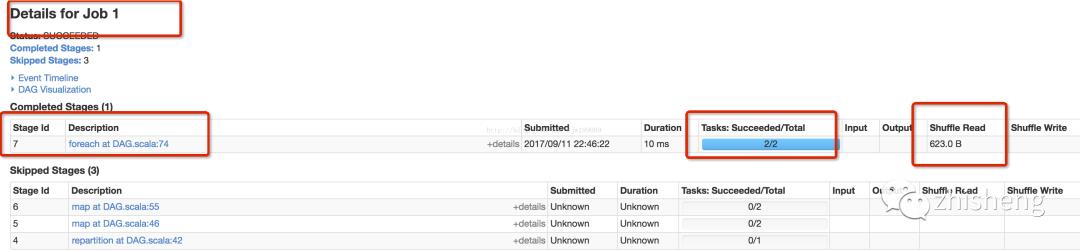
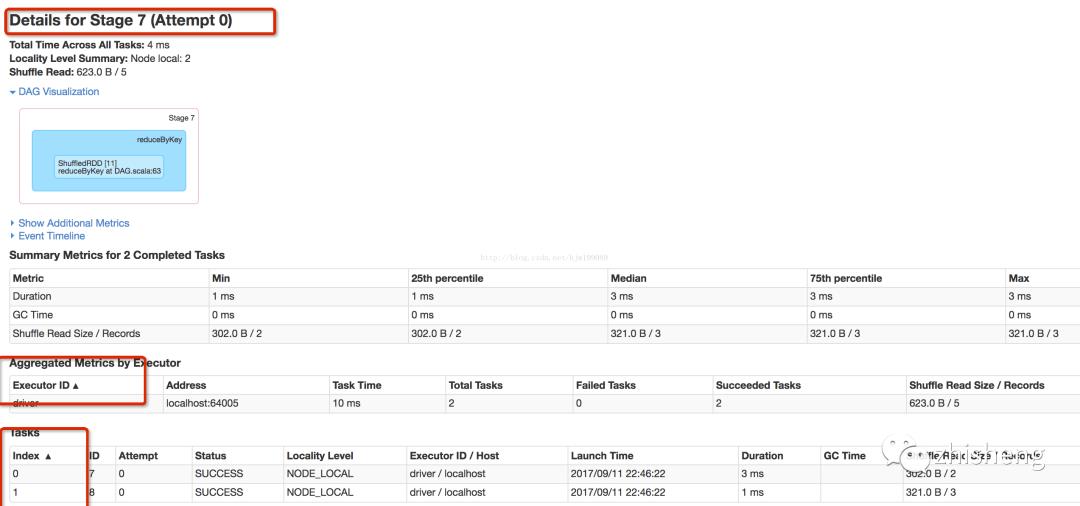
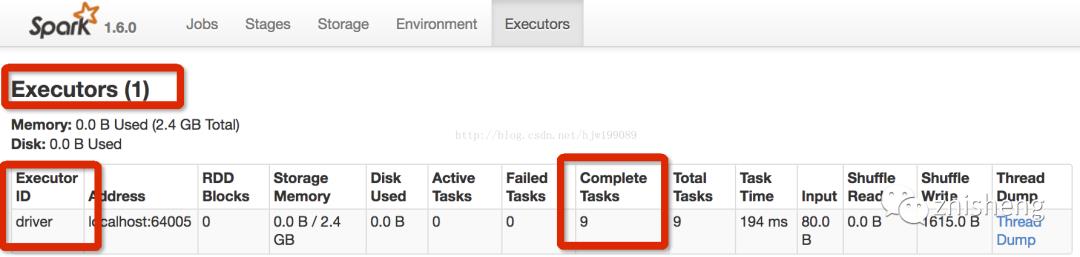
执行过程分析:
Action触发Job,如从(1)中的collect 动作val res = PVUVRDD.collect(),开始逆向分析job执行过程
Action中利用SparkContext runJob()调用–dagScheduler.runJob(rdd,func,分区数,其他)提交Job作业
DAGScheduler的runJob中调用submitJob()并返回监听waiter,生命周期内监听Job状态
runJob()内部
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties),监听waiter(存在原子jobId)的状态也即Job是否完成
submitJob()内部
返回值waiter是JobWaiter(JobListener)
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
将该获取到的Job(已有JobId),插入到LinkedBlockingDeque结构的事件处理队列中eventProcessLoop
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop
EventLoop是LinkedBlockingDeque
eventProcessLoop(LinkedBlockingDeque类型)放入新事件后,调起底层的DAGSchedulerEventProcessLoop.onReceive(),执行doOnReceive()
doOnReceive(event: DAGSchedulerEvent)内部
根据DAGSchedulerEvent的具体类型如JobSubmitted事件或者MapStageSubmitted事件,调取具体的Submitted handle函数提交具体的Job
如 event case JobSubmitted=>dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
handleJobSubmitted()内部
返回从ResultStage 建立stage 建立finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
finalStage激活Job val job = new ActiveJob(jobId, finalStage, callSite, listener, properties),同时开始逆向构建缺失的stage,getMissingParentStages(finalStage)(待补充看)
DAG构建完毕,提交stage,submitStage(finalStage)
submitStage中stage提交为tasks,submitMissingTasks()
submitMissingTasks,根据ShuffleMapStage还是ResultStage--new ShuffleMapTask 或 ResultTask
taskScheduler.submitTasks()开始调起具体的task
private def submitStage(stage: Stage) {
val missing = getMissingParentStages(stage).sortBy(_.id)//====在这里开始反向划分,具体划分见下方
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
private def getMissingParentStages(stage: Stage): List[Stage] ={}
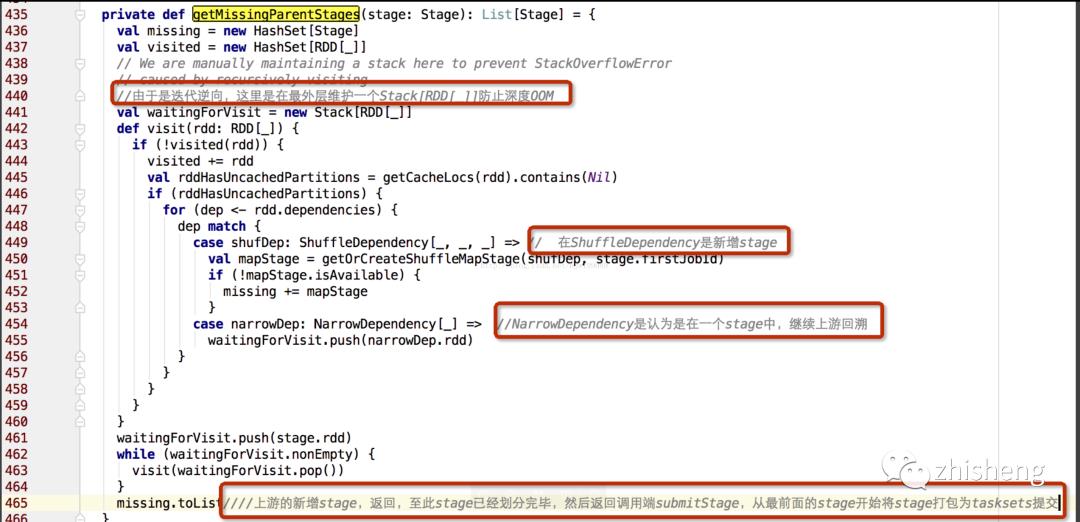
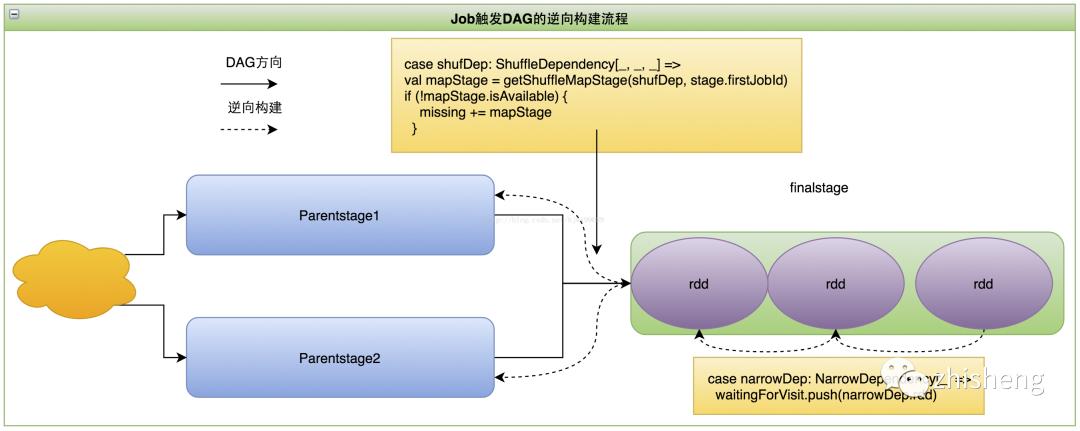
taskScheduler.submitTasks 待续。。。
从Job逆向分析TaskScheduler工作原理
DAGScheduler将stage提交task,然后stage逆向执行该stage的中rdd,这些rdds被打包成tasksets,也即每个partition为一个task,在rdd上执行对应的function函数。
细节如下:
接上部分最后一部分,DAGScheduler中的submitStage-submitMissingTasks(stage, jobId.get)如下,提交每个stage
private def submitStage(stage: Stage) {
val missing = getMissingParentStages(stage).sortBy(_.id)//====在这里开
始反向划分,具体划分见下方
submitMissingTasks()按照stage的类型,调用不同的stageStart的重载类型

点个赞+在看,少个 bug 以上是关于Spark 中 JobStageTask 的划分+源码执行过程分析的主要内容,如果未能解决你的问题,请参考以下文章