spark初识+案例
Posted 六便士买个月亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark初识+案例相关的知识,希望对你有一定的参考价值。
一、初识
1、Spark的特点:
1)速度快:因为支持内存计算,且通过DAG(有向无环图)执行引擎支持无环数据流, 在内存中,比MR快100倍;在磁盘中,比MR快10倍
2)易于使用:支持java、scala、python、R等多种语言
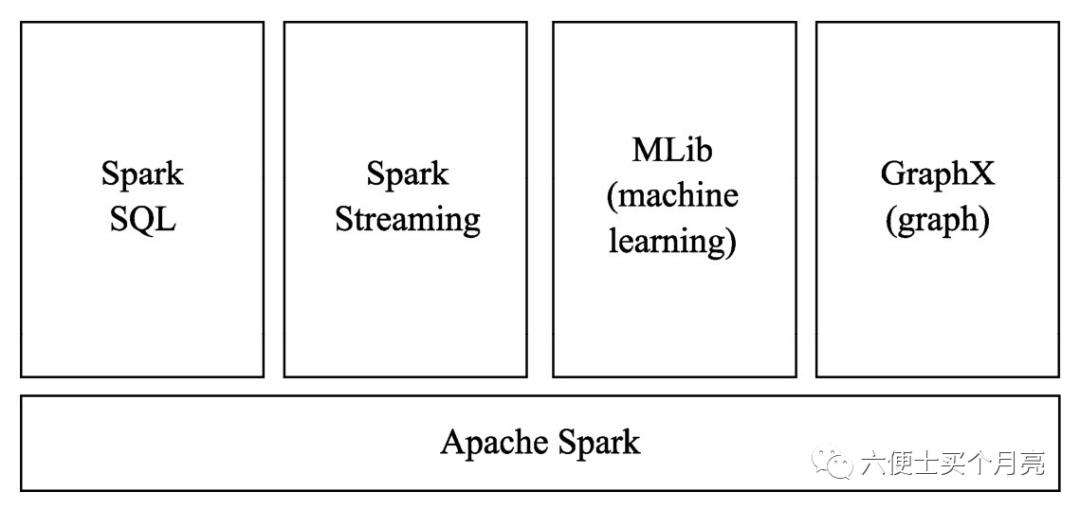
3)通用性强:在Spark的基础上,还提供了Spark SQL、Spark Streaming、MLib以及GraphX在内的多个工具库。
Spark SQL :提供结构化的处理方式
Spark Streaming:主要针对流处理任务
MLib:提供很多机器学习 算法库
GraphX:提供图形和图形并行化计算
4)运行方式:支持多种运行方式,包括在hadoop(yarn调度)和mesos上。也支持Standlone(spark自己的调度框架)的独立运行模式。对于数据源, Spark支持从HDFS、HBase、Kafka等多种途径获取数据。
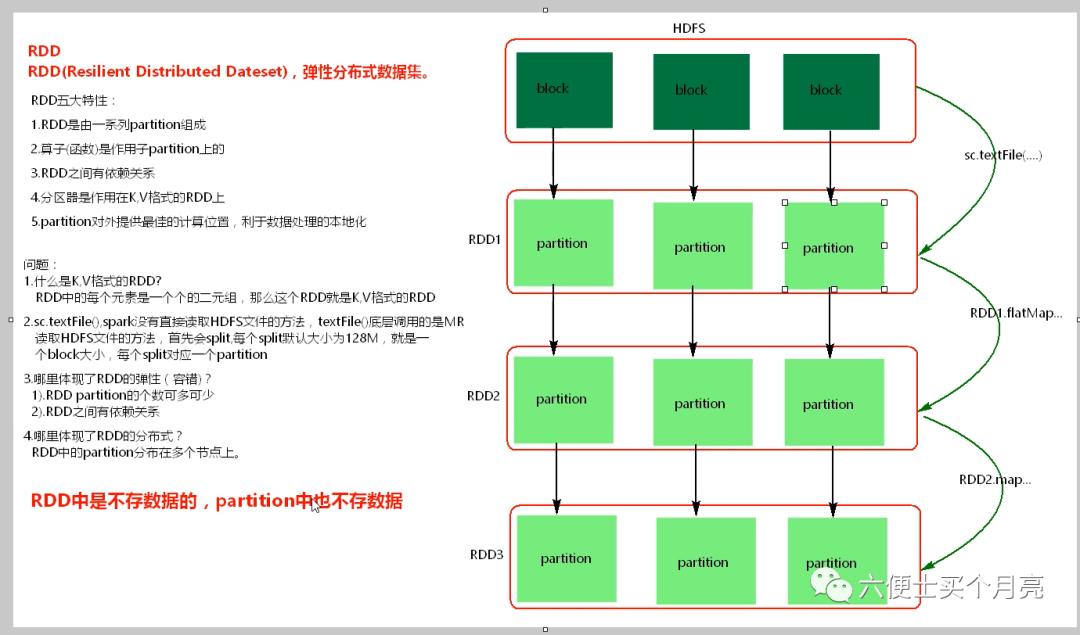
2、RDD( Resiliennt Distributed Datasets) :弹性分布式数据集
Spark 内部引入了RDD, 在数据结构之间利用DAG(有向无环图)进行数据结构变化的记录,这样可以方便的将公共数据共享,且数据发生丢失时,可以依赖这种继承结构(血统Lineage),进行数据重建,有很强的容错性。
RDD是Spark的核心数据结构,Spark整个平台都是围绕着RDD进行。
RDD的五大特性
RDD是由一系列partition组成
算子函数是作用在partition上的
RDD之间有依赖关系
分区器是作用在K,V格式的RDD上的
partition对外提供最佳的计算位置,利于数据处理的本地化
问题:
1、什么是K,V格式的RDD
RDD中的每个元素是一个二元组
2、sc.textFile() , spark没有直接读取HDFS文件的方法,textFile()底层调用的是MR读取HDFS文件的
方法,首先会split,每个split默认大小为128M,就是一个block大小。
每个split对应一个partition
3、哪里体现了RDD的弹性(容错)?
1)RDD的partition的个数可多可少
2) RDD之间有依赖关系
4、哪里体现了RDD的分布式?
RDD中的partition分布在多个节点上
二、环境搭建
环境:
java8
scala-2.11.12
windows
1、下载spark
https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
解压,配置环境变量SPARK_HOME
2、下载Hadoop
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
解压, 配置环境变量HADOOP_HOME
下载后,控制台 spark-shell 启动后,会报错

码云中,找到对应版本的hadoop的bin目录下,下载winutils.exe
https://gitee.com/lroyplus/winutils?_from=gitee_search

将下载的winutils.exe放置本地hadoop/bin目录下
控制台执行命令
D:\my-soft\hadoop-2.7.0\bin\winutils.exe chmod 777 /tmp/hive
3、给spark文件夹授权,window环境直接点击文件属性,赋予用户完全控制权限,不然会报错

4、控制台,输入 spark-shell命令启动spark
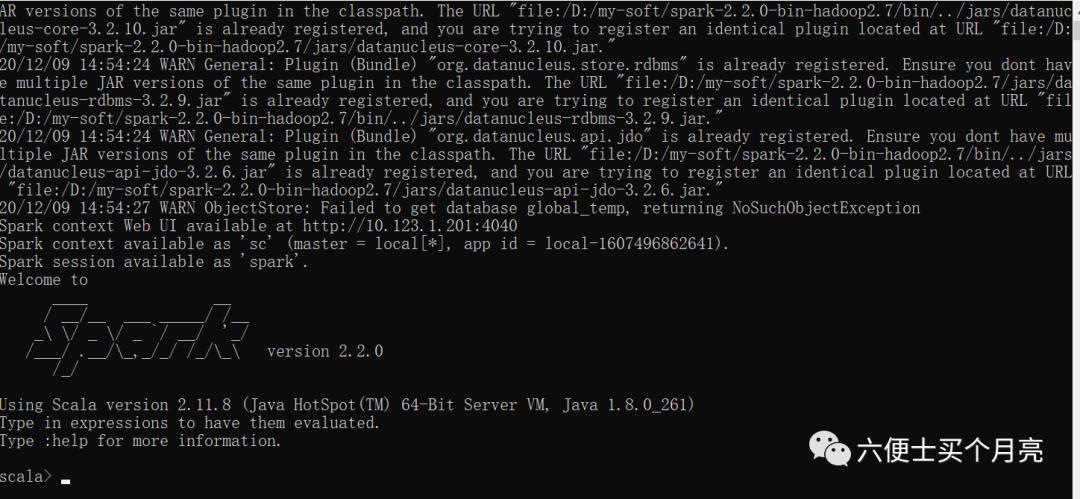
http://10.123.1.201:4040
三、IDEA环境搭建 (直接引入spark-jars的方式)
1) 创建maven工程
2) 导入spark所需的jars
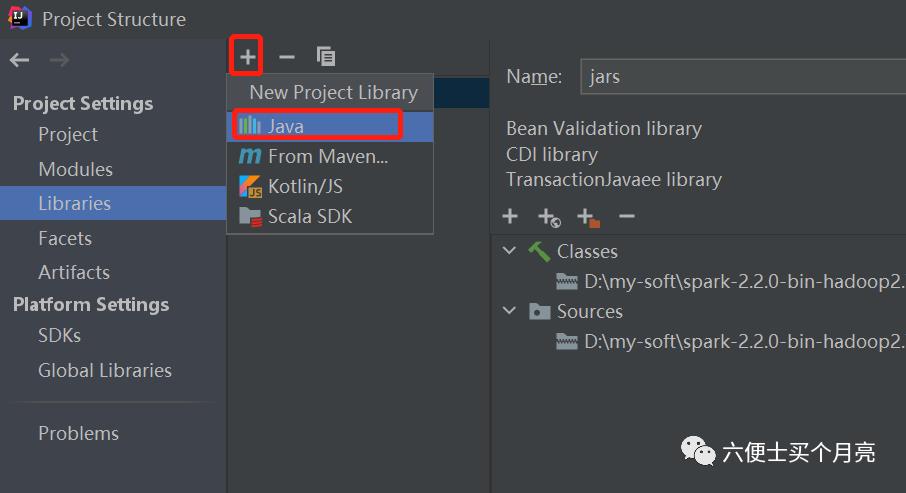
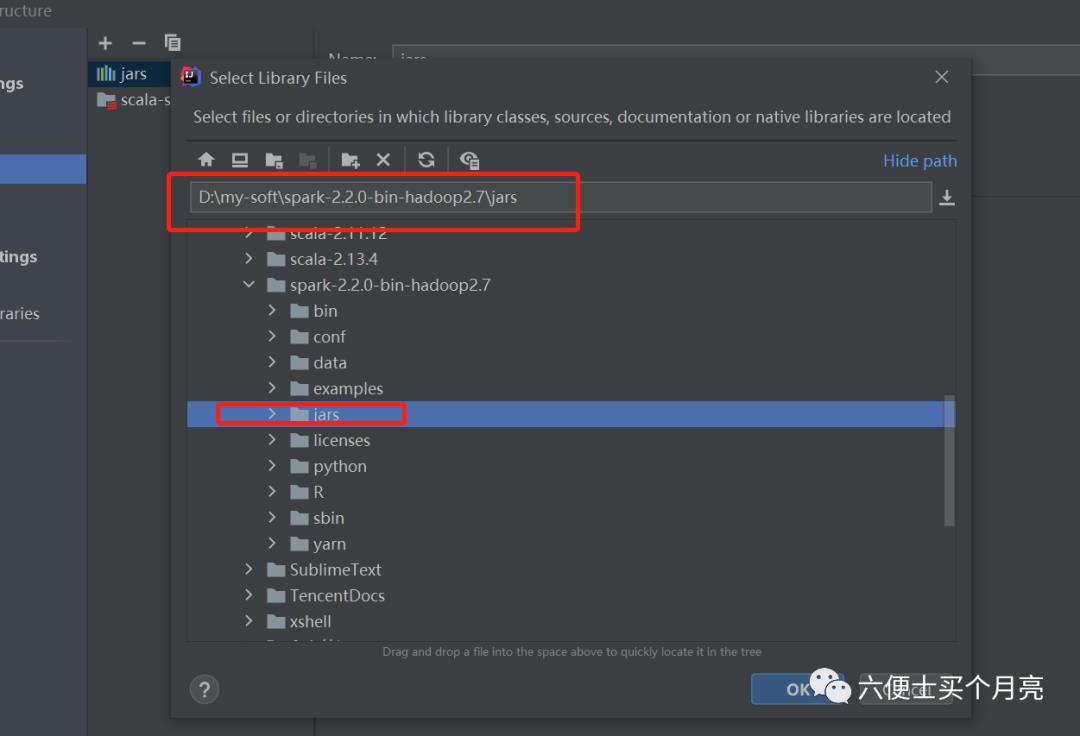
3)创建scala资源目录
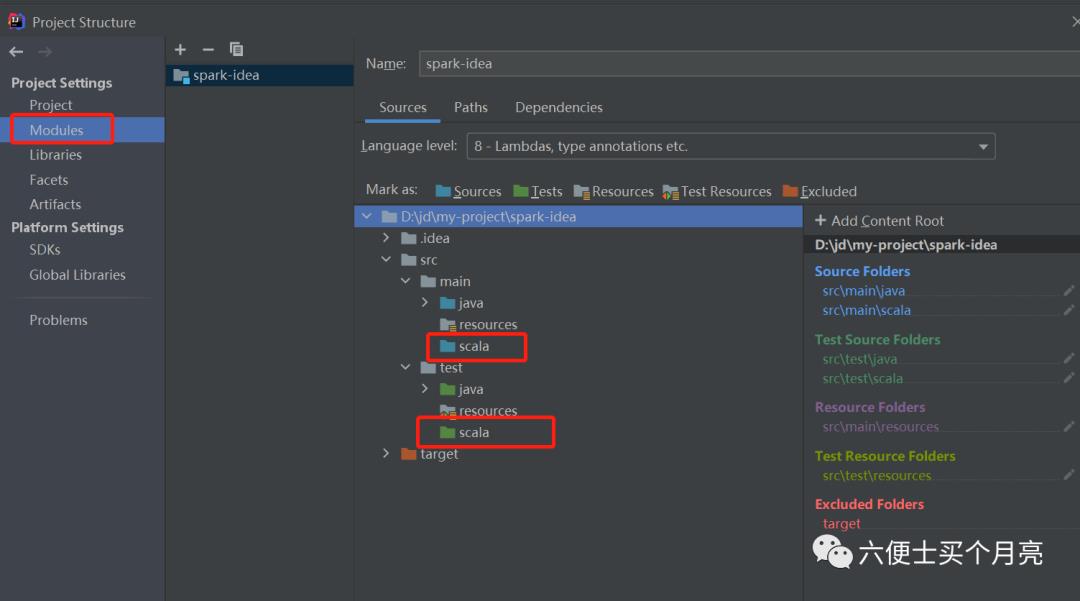
四、wordCount案例
1、创建配置对象 SparkConf,存放任务的参数,比如运行方式,任务名称,指定运行内存等
2、创建上下文对象SparkContext, 参数为 SparkConf
3、通过SparkContext读取数据
4、计算数据
import org.apache.spark.{SparkConf, SparkContext}object WordCountDemo {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf()sparkConf.setMaster("local")sparkConf.setAppName("wordCountDemo")val sparkContext = new SparkContext(sparkConf)sparkContext.textFile("demo.txt").flatMap(line => line.split(" ")).map(word => Tuple2(word, 1)).reduceByKey((x:Int, y:Int) => x + y ).foreach(println)sparkContext.stop()}}简化版:object WordCountDemo {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local").setAppName("wordCountDemo")new SparkContext(sparkConf).textFile("demo.txt").flatMap( _.split(" ")).map((_, 1)).reduceByKey( _ + _ ).foreach(println)}}
文件内容:
hello scalahello worldhello java
运行结果:

java代码:
package org.example;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;import scala.tools.nsc.doc.model.Object;import java.util.Arrays;import java.util.Iterator;/*** @ClassName WordCountByJava* @Description TODO* @Author caogang* @Date 2020/12/9*/public class WordCountByJava {public static void main(String[] args) {// 创建配置类SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local");sparkConf.setAppName("wordCountAppByJava");// 创建上下文:通往spark的唯一通道JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);JavaRDD<String> lines = sparkContext.textFile("./demo.txt");JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {public Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).stream().iterator();}});JavaPairRDD<String, Integer> pairRDD = words.mapToPair(new PairFunction<String, String, Integer>() {public Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<String, Integer>(word, 1);}});JavaPairRDD<String, Integer> reduce = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {public Integer call(Integer o, Integer o2) throws Exception {return o + o2;}});reduce.foreach(new VoidFunction<Tuple2<String, Integer>>() {public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {System.out.println(stringIntegerTuple2);}});reduce.foreach(tuple ->System.out.println(tuple));}}
简化后的java代码
package org.example;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.PairFunction;import scala.Tuple2;import java.util.Arrays;/*** @ClassName WordCountByJava* @Description TODO* @Author caogang* @Date 2020/12/9*/public class WordCountByJava {public static void main(String[] args) {// 创建配置类SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local");sparkConf.setAppName("wordCountAppByJava");// 创建上下文:通往spark的唯一通道JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);JavaRDD<String> lines = sparkContext.textFile("./demo.txt");JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).stream().iterator());JavaPairRDD<String, Integer> pairRDD = words.mapToPair( (String word) -> new Tuple2<String, Integer>(word, 1));JavaPairRDD<String, Integer> reduce = pairRDD.reduceByKey( (Integer o, Integer o2) -> o + o2);reduce.foreach(tuple ->System.out.println(tuple));}}
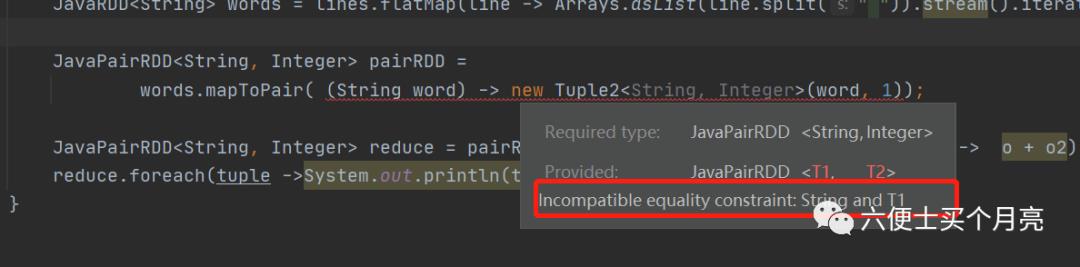
idea编译报错:Incompatible equality constraint: String and T1
但是不影响运行,查资料说是spark-2.2.0的问题,切换到2.4.0即可。
尝试无效:待解决
==================== 更新分割线====================
上面的demo是直接引入了下载好的jars,更新的demo是通过pom依赖的方式
1、环境准备
spark3.0 :
2、idea创建项目
1) 创建maven项目
2) 安装scala插件
3) 引入pom
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
4) 添加Scala SDk :版本2.12.12
5)右击工程,添加模块支持, 选中Scala
6) 运行代码
package com.cg.sparkimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local").setAppName("wordCountDemo")new SparkContext(sparkConf).textFile("demo.txt").flatMap( _.split(" ")).map((_, 1)).reduceByKey( _ + _ ).foreach(println)}}
以上是关于spark初识+案例的主要内容,如果未能解决你的问题,请参考以下文章