spark:集群环境搭建提交方式
Posted 六便士买个月亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark:集群环境搭建提交方式相关的知识,希望对你有一定的参考价值。
一、spark集群环境搭建
三台机器:Master、2个slaves
1、配置免密登陆
1)master节点执行命令如下命令,会在本地当前用户目录(~/)下生成存放公钥私钥的.ssh文件夹
ssh-keygen -t rsa2)执行如下命令:ip为各个slave节点ip
ssh-copy-id -i ~/.ssh/id_rsa.pub ipAdd2、MAC环境下,连接服务器自动中断问题
~/.ssh目录下创建配置文件 config,添加以下配置
Host *ServerAliveInterval 60
3、上传spark包,解压至指定目录
4、将conf目录下的配置文件 slaves.template、 spark-env.sh.template分别复制一份,并改名slaves、spark-env.sh
5、编辑文件slaves,将从节点机器ip写入
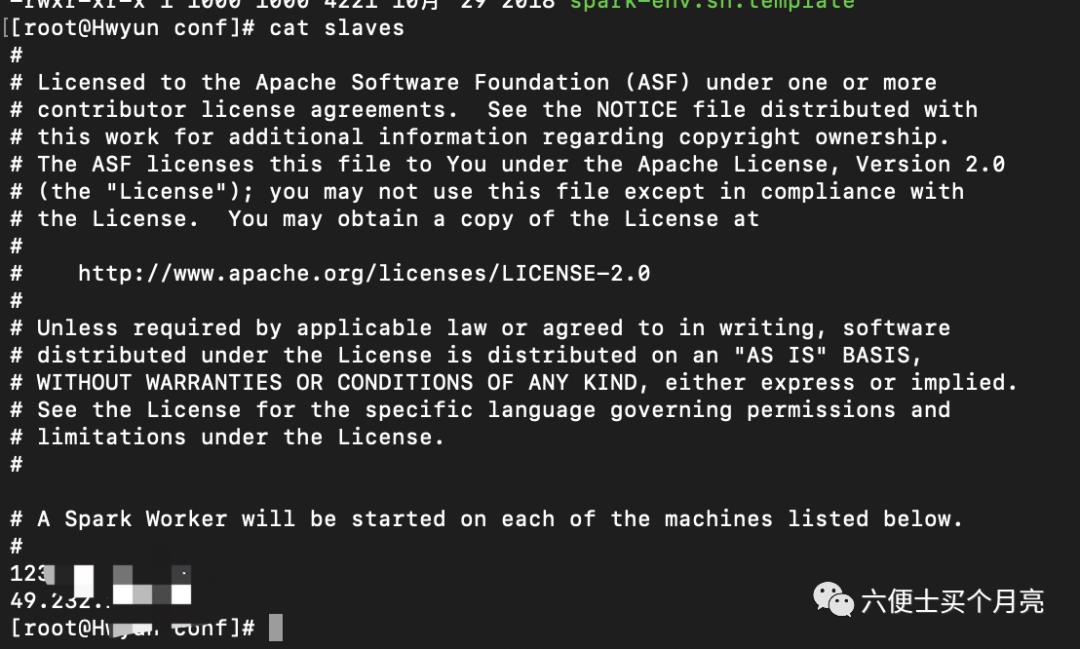
6、编辑文件spark-env.sh,添加以下配置
export SPARK_MASTER_HOST=124.xx.xx.xx // 主节点ipexport SPARK_MASTER_PORT=9080 // 主节点提交任务端口export SPARK_MASTER_WEBUI_PORT=80 // 主节点web-ui端口export SPARK_WORKER_CORES=1 // worker节点所需核数export SPARK_WORKER_MEMORY=1g // worker节点所需内存
7、编辑sbin目录下的spark-config.sh,添加java环境
export JAVA_HOME=/home/tools/jdk1.8.0_458、将包发送至其他节点
scp -r sparkDir username@ip:/xx/xx9、进入主节点的sbin目录下,执行命令启动
./start-all.sh二、相关概念描述
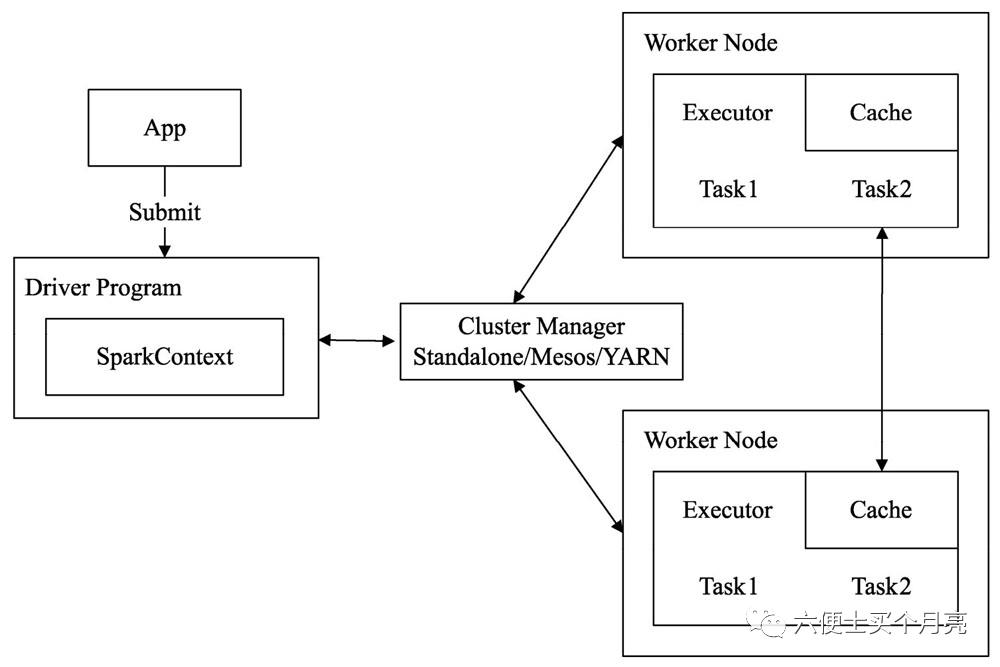
Application:提交到Spark集群上的应用程序,简称App
Driver:执行应用程序中创建SparkContext的main函数进程,一般在集群的任意节点向集群提交应用,就可将该节点称作Driver节点
Cluster manager :集群管理器,统筹管理Spark集群的各种资源,包括CPU和内存等,并分配不同服务所需的资源。(如 standalone manager 即Master、Mesos、Yarn)
Master节点:部署Cluster Manager的节点,是一个物理层的概念
Worker:任何在集群中运行应用程序的节点,其接收集群管理器的调度安排,为应用程序分配必须的资源,生成Executor,起到桥梁作用
Slave节点:部署Worker的节点,每个slave节点可以有多个worker进程,同master,是一个物理层的概念
Executor:在worker节点中实际计算的进程,进程会接收切分好的task任务,并将结果缓存在节点内存和磁盘上
Task:被分配到各个Executor的单位工作内容,是Spark中的最小执行单位,一般来说有多少partition,就有多少task。每个task只会处理单一partition上的数据
Job:多个task的并行计算部分,一般来说,对应Spark中的action操作,一个action操作,生成一个job
Stage:Job的组成单位,一个job由多个stage组成,stage之间彼此相互依赖顺序执行。而每个Stage是由多个task组成
三、基于standalone的两种提交方式
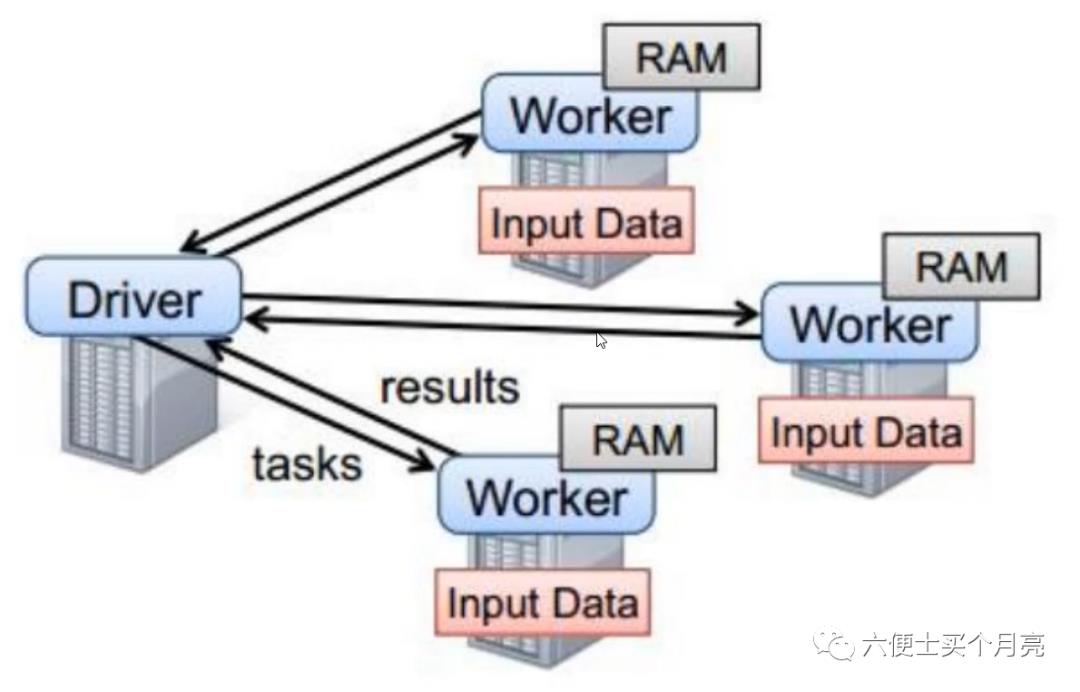
1、client
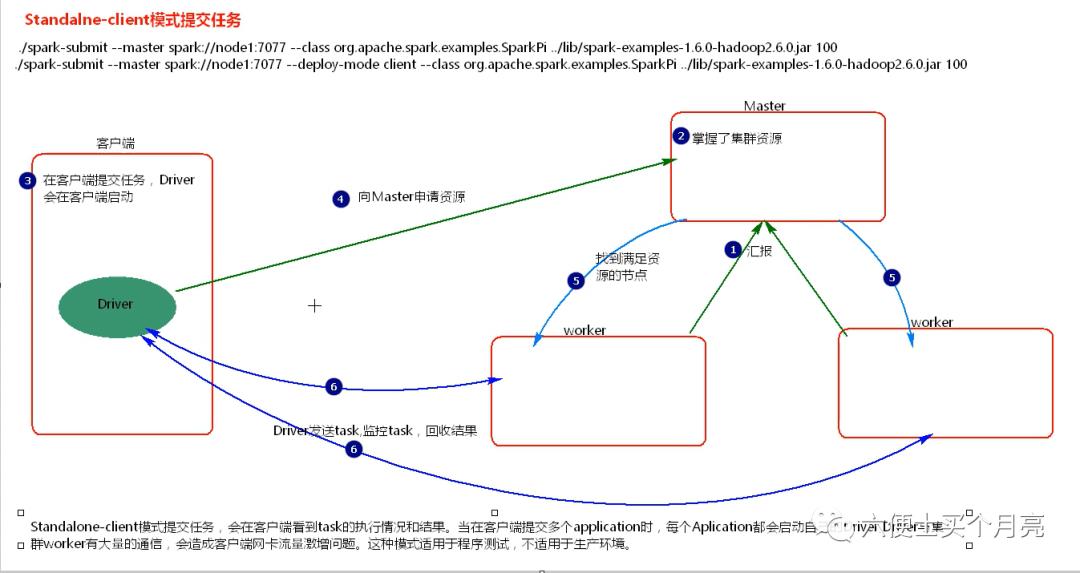
1)启动集群,worker节点向Master汇报
2)Master掌握集群资源
3)spark-client 客户端提交任务,Driver会在客户端启动
4)Driver向Master申请资源(内存、核数等)
5)Master找到合适的worker节点,并反馈给Driver
6)Driver发送task至worker,监控task,回收结果
问题:
通过spark-client提交多个application时,会在客户端启动多个Driver,且Driver与Worker之间存在大量的通信,这会造成客户端网卡流量激增问题。这种模式适用于测试。
2、cluster
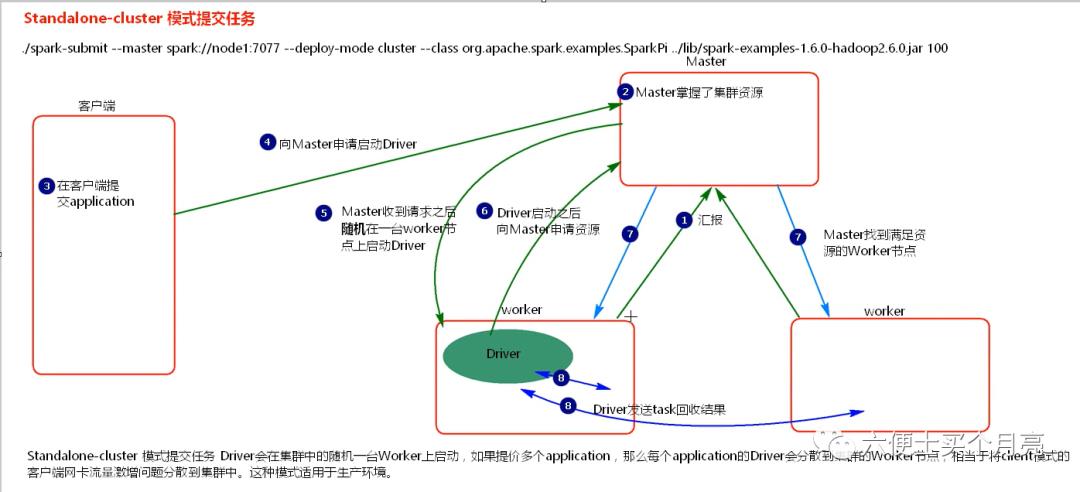
1)启动集群,worker节点向Master汇报
2)Master掌握集群资源
3)spark-client 客户端提交任务
4)向Master申请启动Driver
5)Master收到请求后,随机在一台worker节点上启动Driver
6)Driver向Master申请资源
7)Master找到合适的worker节点,并反馈给Driver
8)Driver发送task至worker,监控task,回收结果
说明:
通过Standalone-cluster提交多个application时,Driver会在随机的一台worker上启动,分摊了client模式下的流量,解决了流量激增问题。适用于生产环境
四、基于yarn的两种提交方式 :需启动Hadoop集群
1、client
1)NodeManager(NM)节点向ResourceManager(RS)节点汇报
2)ResourceManager节点掌握、汇总资源
3)客户端提交Application(App)
4)客户端向RS节点申请启动ApplicationMaster(AM)
5)RS收到请求后,随机找一台NM启动AM
6)AM启动之后,向RS申请资源,用于启动Executor
7)RS返回一批NM节点给AM
8)AM连接NM启动Executor
9)Executor启动后,向Driver注册自己
10)Driver发送task给Executor执行,并监控、回收结果
问题:
同spark-client模式一样,会在客户端启动多个Driver,这会造成客户端网卡流量激增问题。这种模式适用于测试。
2、cluster
1)NodeManager(NM)节点向ResourceManager(RS)节点汇报
2)ResourceManager节点掌握、汇总资源
3)客户端提交Application(App)
4)客户端向RS节点申请启动ApplicationMaster(AM)
5)RS收到请求后,随机找一台NM启动AM,此时AM就是Driver
6)AM启动之后,向RS申请资源,用于启动Executor
7)RS返回一批NM节点给AM
8)AM连接NM启动Executor
9)Executor启动后,向Driver注册自己
10)Driver发送task给Executor执行,并监控、回收结果
说明:
解决流量激增问题
以上是关于spark:集群环境搭建提交方式的主要内容,如果未能解决你的问题,请参考以下文章
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running