让spark榨干你的资源,数据分析从单机到集群
Posted 数融咖啡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让spark榨干你的资源,数据分析从单机到集群相关的知识,希望对你有一定的参考价值。
什么是 spark
spark是2009年才出现的大数据分布式并行计算框架,是也是和Hadoop类似的大数据处理、分析、机器学习等一整套的处理工具集。spark最早诞生于UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室) ,2010年开源,但真正出名是在2013年发布的测试实验数据显示,它在内存程序计算比Hadoop快100倍,在磁盘上计算快10多倍。
spark的核心就是它的弹性分布式数据集RDD (Resilient Distributed DataSet),还有支持在内存进行循环数据流处理的有向图处理引擎。同时它非常方便使用,支持python 、Scala、Java、R等开发语言,并提供了超过80种高级操作,易于构建并行程序。也可以在shell上进行python和Scala的交互式编程。
spark由几个大数据处理工具集组成,包括SQL、流式计算sparkStreaming,机器学习的MLlib/ML,还有图计算GraphX等,可谓功能强大,基本可以胜任几大大数据处理场景。
另外,spark计算框架可以运行在Hadoop yarn,Apache mesos,standalone、或云环境下,所以kubernets类似的资源调度框架其实也是可以很适合spark计算单元的,相比于Hadoop运行于HDFS存储系统,spark可以在HDFS、Cassandra、HBASE、S3等多种数据源上处理。
spark 原理和架构
那为什么spark这么快,可以从并行计算开始,其实生活中有很多例子,举个不恰当的吧比如口罩的生产,如果我们的从整个口罩的上下游来看,要先有化工原料生产无纺布,然后有了三种无纺布流水线,普通无纺布、防水无纺布和融喷无纺布,然后我们还要对口罩组装,加电荷、解析消毒,然后还有包装、分发给各个医疗机构。那么如果所有的无纺布是一个一个生产那肯定效率不高。如果我们逆向看,从开始下令生产口罩,开始那么就从后面到前去发布任务,要口罩,就要三种无纺布,然后三种无纺布的流水线可能有些类似,只要做些转换,然后可以同时生产,一种多了了可以调整转为另一种,或是释放资源。那这么看, 甚至可以看做一个个性智能工程,基于现有资源(RDD)构建不同的流水线,然后下令生产才是开始(action),而组织构建各个流水线环节可以看成transform,那么过程类似这样
普通无纺布= sc输入普通无纺布
防水无纺布=sc 输入防水无纺布
融喷无纺布=sc输入融喷无纺布
生产口罩= 普通无纺布.union(防水无纺布).union(融喷无纺布).map(加上电荷).map(加上电荷).reduce(包装).filter(分发检测)
开启生产就是个action命令开启了整个过程。
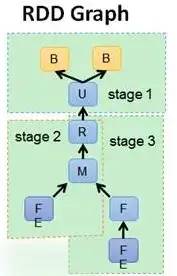
这里就相应有了spark的有向无环图(Directed Acyclic Graph,DAG)这一概念。
有向无环图(DAG)
一个Spark应用由若干个作业构成,首先Spark将每个作业抽象成一个图就是所有相关流程的关系,图中的节点是要计算的数据集,图中的边是数据集之间的转换关系;然后Spark基于相应的策略将DAG划分出若干个子图,每个子图称为一个阶段,而每个阶段对应一组任务;最后每个任务交由集群中的执行器进行计算。借助于DAG,Spark可以对应用程序的执行进行优化,能够很好地实现循环数据流和内存计算。
spark4.png
当然spark的核心关键是分布式,所以它的存储结构最为关键,也是它为何这么快的原因。我们的spark最核心就是这个RDD和DAG。它的关键也就是让这些步骤很好的在各个节点上并行协调,并能很好的利用资源。而相较之下,Hadoop的MapReduce都要存储于磁盘上,计算都要经过网络和IO,所以效率就低了很多。不过最近据说Hadoop也结合内存优化,提出Hadoop3.0,称是比spark还快,这就看大家使用和选择了。
RDD及其特性
RDD(Resilient Distributed DataSets)弹性分布式数据集,是分布式内存的一个抽象概念。当无纺布的流水线在不同地方,那这就是类似RDD了,这里可以抽象地代表对应一个HDFS上的文件,但是它实际上是被分区的,分为多个分区并洒落在Spark集群中的不同节点上。
1.A list of partitions
RDD是一个由多个partition(某个节点里的某一片连续的数据)组成的的list;将数据加载为RDD时,一般会遵循数据的本地性(一般一个hdfs里的block会加载为一个partition)。
2.A function for computing each split
RDD的每个partition上面都会有function,也就是函数应用,也就是说是独立的计算单元,其作用是实现RDD之间partition的转换。
3.A list of dependencies on other RDDs
RDD会记录每个过程的依赖关系 ,为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失的时候还是知道整个过程从而可以从头开始计算。
4.Optionally,a Partitioner for Key-value RDDs
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,例如这里自定义的Partitioner是基于key进行分区,那则会将不同RDD里面的相同key的数据放到同一个partition里面。
5.Optionally, a list of preferred locations to compute each split on
通过优化或者最近原则,选择可以使用的资源地方来进行每次的分布计算。
spark四大特性
spark的原理使得它有了些很好的特性:
1.正如开头说的,因为是在内存,而且有了这种DAG结构的方式,对于很多大数据量的计算,特别是可以分布式的进行迭代的机器学习等运算十分适应,大大加快了大数据处理的速度
2.使用简便,就像上面口罩生产流程,看到在spark里很多运算可以是各种操作的组合,而且一行代码就可以解决,清晰易懂,不像Java可能是要有好几行甚至几十行才能实现一个运算过程。而且就像python一样支持交互式编程,支持R、Java、Scala、python等高级语言接口。如下这是Wordcount实例代码:
sc.textFile("hdfs://master:8020/user/dong/Spark/wc.input").flatMap(.split("")).map((,1)).reduceByKey(_ + _).collect
3.spark和Hadoop一样不只是一个语言API更是一个生态系统,所以有很好的通用性。底层基于RDD和DAG实现的sparkCore ,实现了基本的分布式调度,容错,内存管理,输入输出,作业调度等功能,另外在Spark Core的基础上,Spark提供了一系列面向不同应用需求的组件,主要有Spark SQL、Spark Streaming、早期的MLlib、GraphX,现在还有了DataFrame,还有基于DataFrame的ML,很多推荐使用ML替代了。
4.丰富多样的运行模式
spark可以有多种运行选择模式,也是我喜欢的地方,开发可以本地单机安装,也可以伪分布式部署,或者分布式部署,而分布式又可以基于Hadoop yarn,也就是Spark作为一个提交程序的客户端将Spark任务提交到Yarn上,然后通过Yarn来调度和管理Spark任务执行过程中所需的资源。
Spark on Mesoes模式:Spark和资源管理框架Mesos相结合的运行模式。Apache Mesos与Yarn类似,能够将CPU、内存、存储等资源从计算机的物理硬件中抽象地隔离出来,搭建了一个高容错、弹性配置的分布式系统。Mesos同样也采用Master/Slave架构,并支持粗粒度模式和细粒度模式两种调度模式。
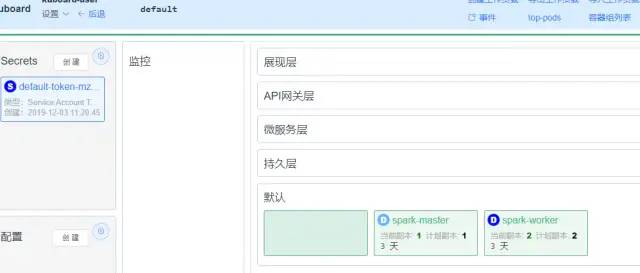
还有我们这里要用的kubernets,从kubernets的master、node结构就非常类似spark的master ,worker架构,所以已经有很多基于kubernets的架构搭建spark集群,因为同样是直接利用kubernets的资源调度、负载均衡选择等功能,只是kubernets不仅用于计算,还可以部署其它服务罢了。接下来就看看spark的组成。
spark核心组件
spark的运行架构涉及几个概念
RDD、DAG、Executor、Application、Task、Job、Stage
spark5.png
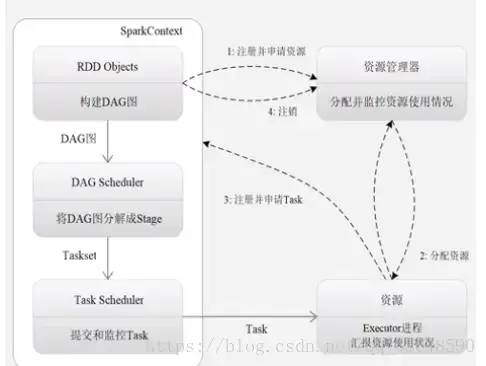
1、构建基本的运行环境,由dirver创建一个内存中的SparkContext,driver就是运行Application 的main()函数
,给应用分配并监控资源使用情况
2、资源管理器为其分配资源,启动Excutor进程,就是某个Application运行在worker node上的一个进程
3、SparkContext根据RDD 的依赖关系构建DAG图,GAG图提交给DAGScheduler解析成stage,运行的每个步骤,然后提交给底层的taskscheduler处理。
executor向SparkContext申请task,也就是运行的线程,taskscheduler 将task发放给Executor运行并提供应用程序代码
4、Task在Executor运行把结果反馈给TaskScheduler,一层层反馈上去。最后释放资源。
task就是application运行的基本单元,多个task组成一个stage。
Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方。
运行架构特点:多线程运行、运行过程与资源管理器无关、Task采用了数据本地性和推测执行来优化。
这里先大致了解下了spark的原理和架构,接下来要用docker部署spark集群。
kubernets部署spark
这里使用的是比较成熟的开源项目来学习部署
https://github.com/big-data-europe/docker-spark
big-data-Europe里面还包含多个大数据组件的部署脚本,比如Hadoop 、hive等。
而且用docker集群可以更为方便开发,只要几秒钟就可以扩容到1000个节点。
这里先要了解kubernets的一个概念daemonSet也可以同时学习一些部署方式
spark部署:
[root@master docker-spark]# cat k8s-spark-cluster.yaml
apiVersion: v1 #版本号,根据kubernets版本和资源类型选择
kind: Service #指定创建资源的角色/类型 这里是service
metadata: #资源的元数据/属性
name: spark-master #资源的名字,在同一个namespace中必须唯一
spec: #资源定义的内容
selector: #将具有指定label标签的pod作为管理范围,与deployment对应
app: spark-master #应用spark-master适用
ports: #需要暴露的端口库号列表
- name: web-ui #端口号名称
protocol: TCP #协议类型
port: 8080 #web服务端口号,service暴露在cluster ip上的端口,通过<cluster ip>:port可以访问此服务,主要面向k8s内
targetPort: 8080 #Pod的外部访问端口,port和nodePort的数据通过这个端口进入到Pod内部,Pod里面的containers的端口映射到这个端口,提供服务
#nodePort: 8081 #Node节点的端口(范围:20000-40000),<nodeIP>:nodePort 是提供给集群外部客户访问service的入口,面向外部,我们从网页访问也是用这端口
- name: master #master主通信端口
protocol: TCP
port: 7077 #和worker互相通信的端口
targetPort: 7077
- name: master-rest #master的restful风格的http请求接口
protocol: TCP
port: 6066 #和worker通信端口
targetPort: 6066
#cluterIP: None
type: NodePort
---
apiVersion: v1
kind: Service
metadata:
name: spark-client #客户端服务
spec:
selector:
app: spark-client
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment #资源类型为deployment,集群管理的控制,面向无状态应用
metadata:
name: spark-master #资源元数据
labels:
app: spark-master #标签
spec:
selector:
matchLabels:
app: spark-master #和service的selector对应
template: #就是对pod对象的定义
metadata:
labels:
app: spark-master
spec:
containers: #Pod里的容器
- name: spark-master #容器名
image: bde2020/spark-master:2.4.5-hadoop2.7 #镜像
imagePullPolicy: Always #总是拉取镜像
ports: #容器开放的端口
- containerPort: 8080
- containerPort: 7077
- containerPort: 6066
---
apiVersion: apps/v1
kind: DaemonSet #DaemonSet控制器,确保全部(或者一些)Node 上运行一个 Pod 的副本,集群运行可以使用,比如让每个节点运行ceph、nfs等。
metadata:
name: spark-worker #每个node都要有worker运行
labels:
app: spark-worker #应用名
spec:
selector: #有spark-worker标签的pod作为管理范围
matchLabels:
name: spark-worker
template: #定义Pod对象
metadata:
labels:
name: spark-worker
spec:
containers: #Pod里的容器
- name: spark-worker #容器名
image: bde2020/spark-worker:2.4.5-hadoop2.7 #使用镜像
imagePullPolicy: Always #总是拉取镜像
ports:
- containerPort: 8080 #容器开放的端口
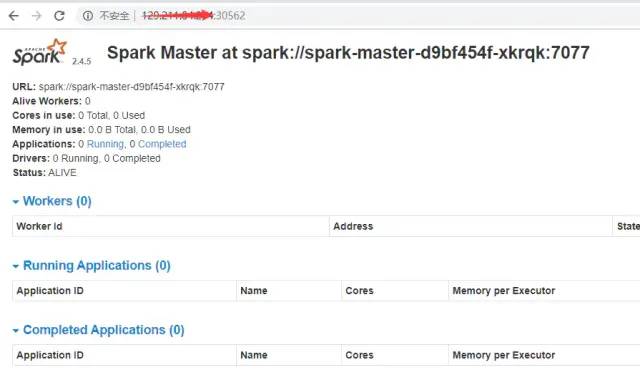
后续可以在自己更改镜像,以便适应其他版本和架构需求
开始学习可以借鉴pyspark ,scala会比较快的熟悉语法,单机上可以调试
因为spark是基于scala开发的,scala从英文名可以看出,scale有大和可伸缩的意思,所以scala就是最适合大规模可伸缩的处理语言,当然scala也是基于Java virtual machine开发的,所以很依赖jvm,当然很多时候实际大规模处理用scala,而建模分析常用python或是R,spark也提供了很多Java 、python 、R的接口。
https://github.com/deanwampler/spark-scala-tutorial
做数据科学最麻烦的是一堆数据处理和环境技术的学习,这里将学习内容和代码放到jupyter里,并使用docker容器打包,可以很快地下载源码,运行docker容器,也就是一键部署实验环境。当然这也是一个项目的基础,这里顺便说下作者和他的公司。
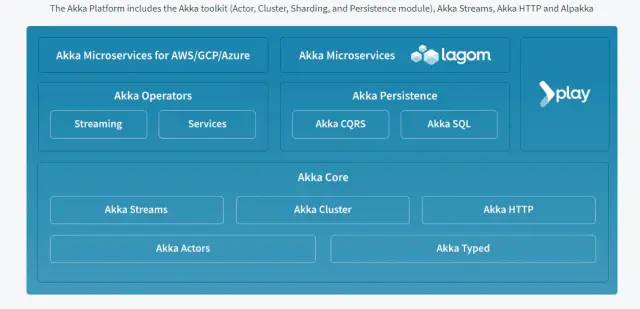
lightbend公司和Akka platform
lightbend公司的前身就是Typesafe,就是scala语言的发明者,作者也有参与贡献,同时他也主导构建了FDP(快速数据平台)的工作,现在就是所谓的akka platform。
现在越来越多的数据平台也从传统经典大数据平台转为快速数据开发平台,并在边缘拥抱“移动中”数据的价值,无论是来自用户数据,传感器还是人类。IBM也开始和lightbend的合作,将很多其中的应用框架。
https://www.lightbend.com/akka-platform
从项目 主页可以看到,它的宣传就是无论多复杂都不让技术阻碍数据战略的实施。
ng
平台集成了流式处理,sql ,cluster 等框架,同时结合了容器微服务和响应式程序的特点,可以更轻松地部署,监视和扩展生产中的应用程序,从而提高开发效率,并使生产操作更可靠。
学习spark最少需要的scala
作者github项目首页也提供了 spark最少需要的scala语言,正如我们学习python或Java的开源项目一样,我们不必将所有的Java特性都学过去,这里提供了很好的学习材料,作者也曾演讲过《用Spark所需的Scala知识》
https://github.com/deanwampler/JustEnoughScalaForSpark
为何是scala
这里先看下scala是一门通用用途、面向对象、函数式的JVM语言,最终也是和Java一样在jvm上运行,同时它有面向对象的特性和函数式编程的特性,计算和各种面向对象的结合非常方便,所以类似Java+python的融合,或是多范式语言,更接近生产使用。
这里首先是spark是基于scala开发的,spark可以使用Java,python,R和scala,SQL语言开发,一般数据工程师更倾向scala和Java,适用于大数据下的弹性可伸缩架构;当然,数据科学家或是分析师更倾向python和R,SQL等,进行数据提取,分析,建模等。但是这也不是有明显的边界的,许多数据工程师也会使用python,R等,而数据科学家也会在spark上跑scala程序。
使用scala开发spark有些优势
1、spark是scala写的,所以有更好的兼容性,很多API调用方便
2、有助于调试,spark报错也很多类似Java的,若是python开发也要看很多类似的报错
3、比Java等更加简洁
4、我们知道python是弱类型,Java强类型,所以python学得快,但是scala这类强类型更有利于安全性。保持编译和运行的一致,不容出错。
为何不是scala
这里主要是和python比较,因为python相对有更多的社区,有非常广泛应用的各类库,特别是生态和数据分析类的库。
预备
学习教程的基础这里是假设有一些编程基础,假设是Java的,就需要补充一些函数式和其他缺乏的知识,如果是python的,应该在环境上比较熟悉,也是类似notebook的方式,但是需要补充一些jvm和面向对象的知识,如果从零开始也是可以,只要按需搜索相关的知识即可。
有了这些基础之后就可以开始spark学习
https://github.com/deanwampler/spark-scala-tutorial
这里就是教我们如何使用scala编写spark应用程序的教程。
也有三种学习环境的选择
基于jupyter notebook环境的学习,这里可以使用docker快速搭建环境;
基于idea,比如IntelliJ 的集成开发环境;
基于终端的开发方式,这里是sbt;
以docker运行为例:
`[root@master JustEnoughScalaForSpark]# docker run -it --rm \
> -p 8888:8888 -p 4040:4040 \
> --cpus=2.0 --memory=2000M \
> -v "$PWD":/home/jovyan/work \
> "$@" \
> jupyter/all-spark-notebook
然后登陆就可以开始快乐的学习啦,体验资源被榨干,感受自己的贫穷
以上是关于让spark榨干你的资源,数据分析从单机到集群的主要内容,如果未能解决你的问题,请参考以下文章