数据分析工具篇——pyspark应用详解
Posted 数据python与算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析工具篇——pyspark应用详解相关的知识,希望对你有一定的参考价值。
前面几篇文章我们讲解了大数据计算的主要架构:hadoop和spark,从离线和实时解决了大数据分析过程中遇到的大部分问题,但是这是否是就代表了大数据计算引擎?
不是的~
现阶段流批一体盛行,Flink也逐渐进入大家的视野,大有发展壮大的趋势,我们后面会单独讲解这一工具,这篇文章我们重点讲解一下基于spark运算的pyspark工具。
pyspark不是所有的代码都在spark环境应用,可以将一些主要的运算单元切到spark环境运算完成,然后输出运算结果到本地,最后在本地运行一些简单的数据处理逻辑。
pyspark主要的功能为:
1)可以直接进行机器学习的训练,其中内嵌了机器学习的算法,也就是遇到算法类的运算可以直接调用对应的函数,将运算铺在spark上训练。
2)有一些内嵌的常规函数,这些函数可以在spark环境下处理完成对应的运算,然后将运算结果呈现在本地。
个人理解pyspark是本地环境和spark环境的结合用法,spark中的函数是打开本地环境到spark环境的大门,本地的数据和逻辑按照spark运算规则整理好之后,通过spark函数推到spark环境中完成运算。
所以关键在于有多少计算方式是可以放在spark环境计算的,有多少常用的pyspark函数;
pyspark原理介绍

原理图如下:
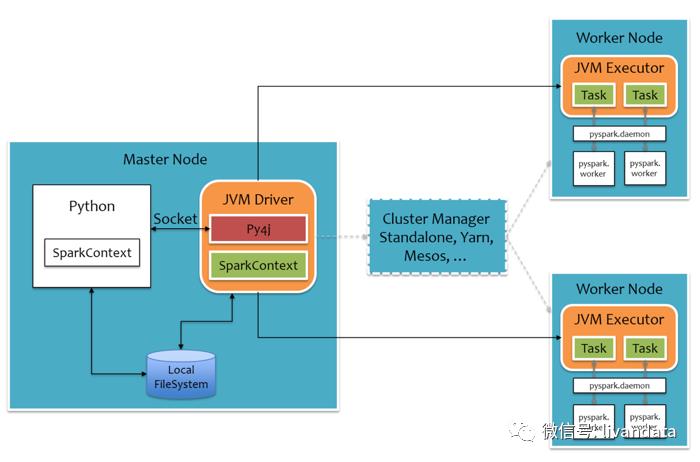
上图中,python中调用sparkcontext。
sparkcontext会通过py4j启动jvm中的javasparkcontext,javasparkcontext再将数据逻辑推到集群中完成运算。

结合上图,pyspark的运算逻辑为:
运算job时pyspark会通过py4j将写好的代码映射到jvm中,jvm调用自身的sparkcontext.runjob()函数,实现job的分发,分发的方式是spark的,每个job分发到集群各个executor上之后,各个executor中jvm会调用自身服务器的python进程,完成自身部分的运算,运算完成后再将结果集返回给jvm,原路返回,最终呈现在python的界面上。
有没有感觉jvm只是一个通道?
是的~
简单讲他的功能就是将python分发到各个节点上,然后再将运算结果收回来。
pyspark的常用函数

1)parallelize():将list数据序列化成RDD格式,方便spark进行运算;
2)collect():将RDD格式数据转化成list数据,方便数据输出;
3)glom():显示出RDD被分配到哪个分区节点(exector)中进行计算;
4)map():针对RDD对应的列表的每一个元素,进行map()函数里面的函数;
mydata =mydata1.map(lambda x : (x[0], x[1]**2)).collect()
5)reduce(fun(a, b)):合并相同key值的数据。
是针对RDD对应的列表中的元素,递归地选择第一个和第二个元素进行操作,操作的结果作为一个元素用来替换这两个元素,其中函数需要有两个参数。
reduce() :rdd.reduce(func)对同类型的数据的RDD进行聚合操作,返回值是一个同类型的数值结果:
num=sc.parallelize([1,2,3,4])sum=num.reduce(lambda x,y: x+y)
理解x,y: x指的是返回值,而y是对rdd各元素的遍历。所以,x+y表示对num中数据进行累加:
print(sum) #10另外函数为:
reduceByKey(fun(a, b))类似于hive中的groupby函数,按照key值a进行分组,对b进行聚合计算,返回的是list;
reduceByKeyLocally(fun(a, b))类似于hive中的groupby函数,按照key值a进行分组,对b进行聚合计算,返回的是字典;
6)在spark环境下构建dataframe数据块;
data = spark.createDataFrame(data, ["A", "B"])
常用算子
1)data.show():显示dataframe中的数据;
2)mydata.rdd.map():将dataframe转化成rdd,然后进行map运算;
map运算是每行进行单独计算,返回每行的计算结果值,形成一个新的rdd;
一般map会与lambda结合使用,通过lambda函数对map中的每行数据进行计算,例如:
from pyspark.sql import SparkSessionspark = SparkSession\.builder\.appName("PythonWordCount")\.master("local") \.getOrCreate()spark.conf.set("spark.executor.memory", "500M")sc = spark.sparkContextprint('see the difference of flatmap and map:')L = [1,2,3,4]rdd_1 = sc.parallelize(L, 2)rdd_2 = rdd_1.map(lambda x: (x, x**2))rdd_3 = rdd_1.flatMap(lambda x: (x, x**2))print('map:', rdd_2.glom().collect())print('flatmap:', rdd_3.glom().collect())
3)flatmap():将map中的数据元组展平到一个list中;
上图中的数据是一个parallelize,即为一个rdd结构的list值,其运算基本符合numpy的运算结构,map的每次运算都会取出一个元素进行计算;另外除了parallelize之外pyspark还提供了dataframe结构,这一结构在进行map运算时需要先转化成rdd,然后按照每次一行的结构将数据传入到map中进行运算,map中用lambda函数对每行进行深度计算,每行是一个dataframe格式,切记取其中某个值时需要使用x['a']结构。
map的运算结果为:[[(1,2),(3,4)],[(5,6),(7,8)]]
flatmap的运算结果为:[[1,2,3,4], [5,6,7,8]]
4)filter():用于删除/过滤,即删除不满足条件的元素,这个条件以lambda函数的形式作为参数传入filter()函数中;
rdd1.filter(lambda x : x>=2).collect()5)distinct():用于去重,没有参数;
6)join():将两两具有相同key的元素的值,组成一个tuple作为这个key的value;
左连接:
print (kvRDD1.leftOuterJoin(kvRDD2).collect())
右链接:
print (kvRDD1.rightOuterJoin(kvRDD2).collect())
7)RDD1.union(RDD2):求两个RDD对象的所有元素的并,不去掉重复元素;
求交集:
intRDD1.intersection(intRDD2).collect()求差集:
intRDD1.subtract(intRDD2).collect()求笛卡尔积:
intRDD1.cartesian(intRDD2).collect()
8)randomsplit():将RDD按照一定的比例拆分成多个;
intRDD.randomSplit([0.4,0.6])9)sortByKey():按照key进行排序;
kvRDD1.sortByKey().collect()10)keys()/values():对键值对的数据获取;
print(kvRDD1.keys().collect()) print (kvRDD1.values().collect()11)读取前2条数据;
kvRDD1.take(2)12)按照key计数;
print (kvRDD1.countByKey().collect())13)根据输入的key值来查找对应的Value值:
print (kvRDD1.lookup(3))pyspark环境下的类SQL操作
pyspark环境下的类SQL操作主要是对spark—dataframe的操作:
1)查询一列或多列数据:
df.select(“name”)df.select(df[‘name’], df[‘age’]+1)df.select(df.a, df.b, df.c)
2)按照条件显示某一组数据:
df.where("income = 50" ).show()3)新增一列数据:
df.withColumn('income1', df.income+10).show(5)4)修改列名:
df.withColumnRenamed( "income" , "income2" ).show(3)5)union实现的横向合并:
df.union(df).show()6)两个表做连接:
df_join = df_left.join(df_right, df_left.key == df_right.key, "inner")7)调用多个函数:
df.groupBy(“A”).agg(functions.avg(“B”), functions.min(“B”), functions.max(“B”)).show()8)列表转化成dataframe的方法:
df = sc.parallelize([('india','japan'),('usa','uruguay')]).toDF(['col1','col2'])9)单列求和(可以和分组求和比较):
from pyspark.sql.functions import sum as spark_sumresult = spark_sum(filter_df['_2'] * filter_df['_3'])df.select(result).show()
pyspark常用方法集合
1)构建字典结构,pyspark中没有对应的字典结构,如果需要可以用to_json()的方式实现:
from pyspark.sql.functions import udffrom pyspark.sql import types as Tdef create_struct(zip_code, dma):return {zip_code: dma}data.withColumn('struct', create_struct(data.zip_code, data.dma)).toJSON().collect()
2)将一行中list的部分转化成列:笛卡尔积操作
import pyspark.sql.functions as Fexploded_df = df.select("*", F.explode("res").alias("exploded_data"))exploded_df.show(truncate=False)
修改对应列名:
exploded_df = exploded_df.withColumn("Budget",F.col("exploded_data").getItem("Budget"))
取出对应的列:
exploded_df.select("Person", "Amount", "Budget", "Month", "Cluster").show(10, False)3)RDD中需要以map、lambda和自定义函数来进行循环操作
sample2 = sample.rdd.map(lambda x: (x.name, x.age, x.city))4)pyspark的文件读写:
from pyspark.sql import SQLContextfrom pyspark import SparkContextsc = SparkContext() # 只能运行一次sqlContext = SQLContext(sc)
# 读取数据:
raw_data = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('./data/train.csv')# 写入csv文件:
save_data_test.write.csv('./data/small_train.csv')5)pyspark中对循环有不便利,rdd无法直接进行循环,需要进行转化:
使用DataFrame.collect()方法,将Spark-SQL来自所有执行程序的查询结果聚合到驱动程序中。
该collect()方法将返回Python list,其中每个元素都是Spark Row。
然后,你可以在for-loop中迭代此列表。
代码段:
data1 = hive_context.sql("select col_name from schema_def where data_type<>'string'")colum_names_as_python_list_of_rows = data1.collect()
6)如何按照一定的条件选择某一list中的值:
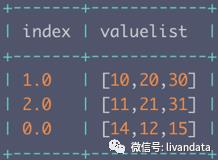
转变成:
这一思路有如下两种方法:
第一种:
df.select("index", f.expr("valuelist[CAST(index AS integer)]").alias("value")).show()第二种:
import pyspark.sql.functions as fdf.select("index", f.posexplode("valuelist").alias("pos", "value"))\.where(f.col("index").cast("int") == f.col("pos"))\.select("index", "value")\.show()
其中:
f.col("index"):col 方法接收一个字符串列名作为参数, 根据指定的列名返回一个Column。作用和df.columnName相同。
df.selectExpr()/f.expr():用来选择某列并对某列进行变换,返回变换后的值;
df.selectExpr('length(key)').show():计算key列中每个元素的长度;
df.withColumn(colName, col):用来对某一列进行操作,如转换数据类型,根据某一列创建新列等:
add1 = udf(lambda x: x+1)df.withColumn('val1', add1('val')).show()df.withColumn('val', df.val.cast('float')).show()
以上是关于数据分析工具篇——pyspark应用详解的主要内容,如果未能解决你的问题,请参考以下文章