spark 3.0.0 单机搭建
Posted 小鹏笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark 3.0.0 单机搭建相关的知识,希望对你有一定的参考价值。
“ 本篇文章为大数据系列的第二篇,简易安装spark3.0.0 的单机模式,以及与hadoop的结合。”
01
—
下载安装包
访问官网 http://spark.apache.org/
https://archive.apache.org/dist/spark/spark-3.0.0/
由于我们要与之前安装的hadoop 3.2.1结合起来,所以我们选择对应版本hadoop版本的spark

02
—
上传并解压spark安装包
首先上传至服务器

解压
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz解压完成后如下图:

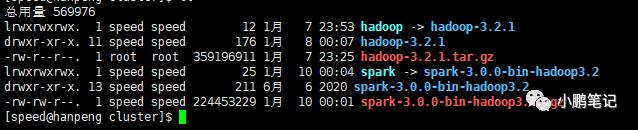
为了方便起见,创建一个超链接
ln -s spark-3.0.0-bin-hadoop3.2 spark创建超链接后如下图:
03
—
配置spark_env.sh
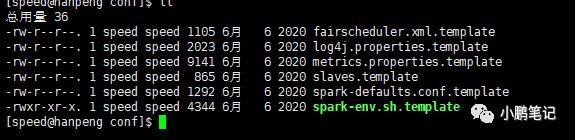
进入 spark 的安装目录下
cd conf
如下图:
将spark-env.sh.template复制出来更名为spark-env.sh
cp spark-env.sh.template spark-env.sh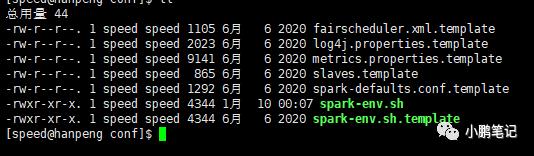
修改 spark-env.sh 文件
vim spark-env.sh添加以下内容:
export JAVA_HOME=/home/speed/soft/jdkexport SPARK_MASTER_HOST=localhostexport HADOOP_HOME=/data/cluster/hadoopexport HADOOP_CONF_DIR=/data/cluster/hadoop/etc/hadoopexport SPARK_EXECUTOR_CORES=1export SPARK_EXECUTOR_MEMORY=1g
添加完成后保存
保存后内容如下:
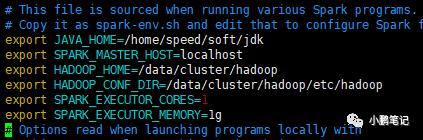
其中 HADOOP_HOME和HADOOP_CONF_DIR两个参数为上一篇文章中的hadoop的路径
接下来可以回到spark的安装目录下启动
cd ..sbin/start-all.sh
启动后,日志如下:

此时已经启动成功,可以在浏览器访问spark的master节点,端口默认为8080
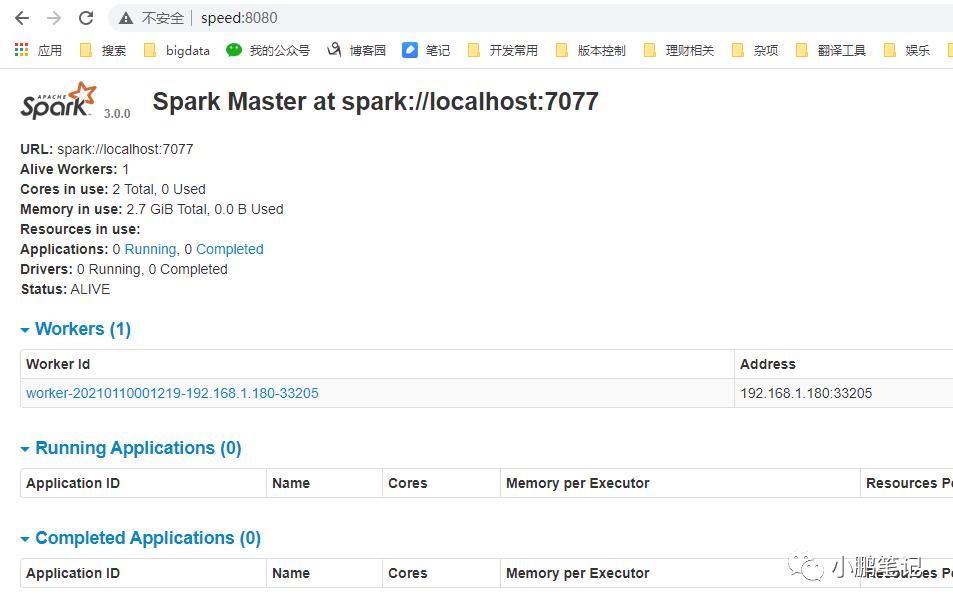
注:我的浏览器中输入的是speed:8080,是因为我已经在windows中配好了hosts,你们输入对应的ip即可。
此时可以看到目前只有一个work节点在线
04
—
测试
测试之前,先参考上一篇文章中的hadoop环境启动起来,进入hadoop的安装目录
sbin/start-dfs.shsbin/start-yarn.sh
已经启动了的不需要重复启动!!!
进入spark的安装目录,执行测试程序,首先使用local模式执行
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] --deploy-mode client --driver-memory 800M --num-executors 1 --executor-memory 800M examples/jars/spark-examples_2.12-3.0.0.jar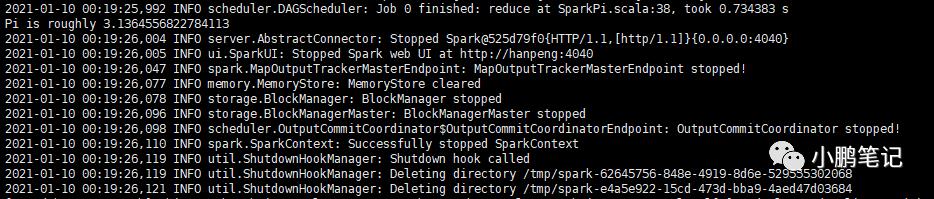
执行完毕
接下来使用 client 模式执行
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://localhost:7077 --deploy-mode client --driver-memory 800M --num-executors 1 --executor-memory 800M examples/jars/spark-examples_2.12-3.0.0.jar执行结果与上方的local模式执行结果一致,此时可以查看spark的master的界面
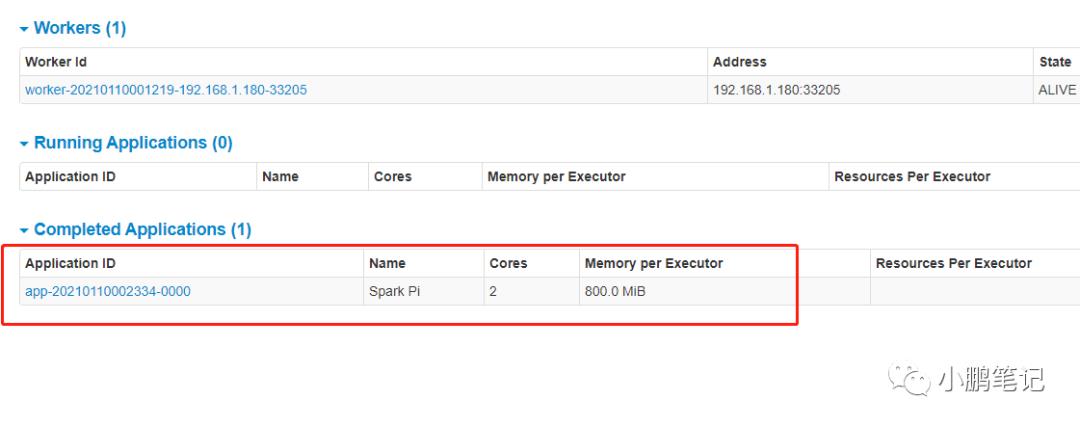
此时任务已经记录在master节点中,client模式也运行成功
接下来运行cluster模式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 800M --num-executors 1 --executor-memory 800M examples/jars/spark-examples_2.12-3.0.0.jar执行后控制台如下图:
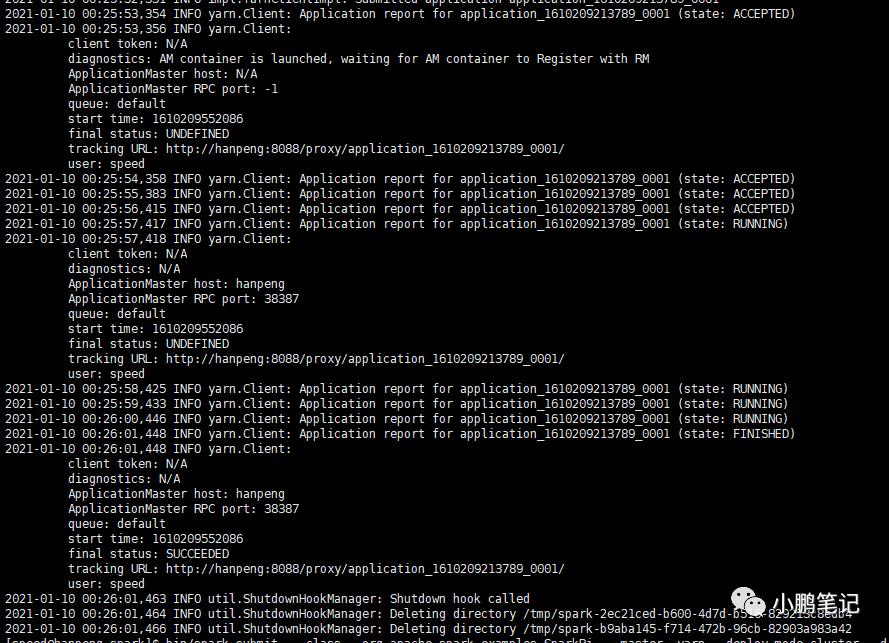
此时代表任务已经执行完毕,可以去yarn界面查看任务内容
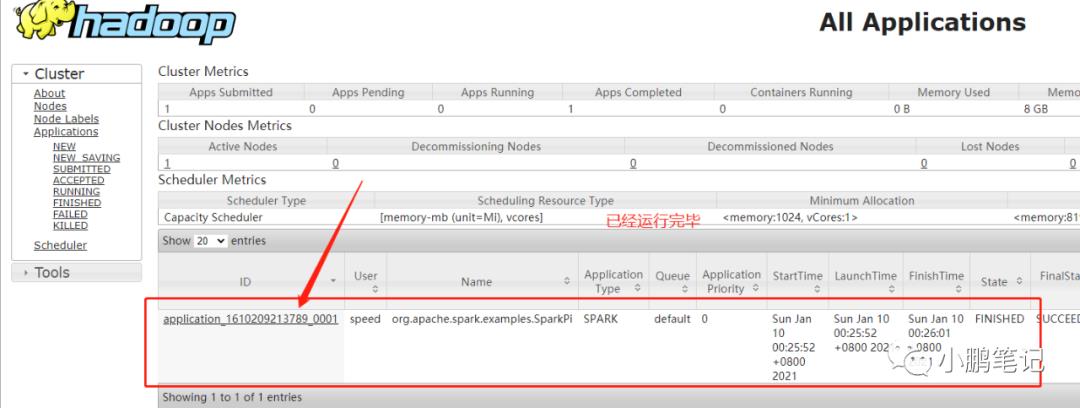
点击左侧的ID栏,可以进去查看yarn的日志
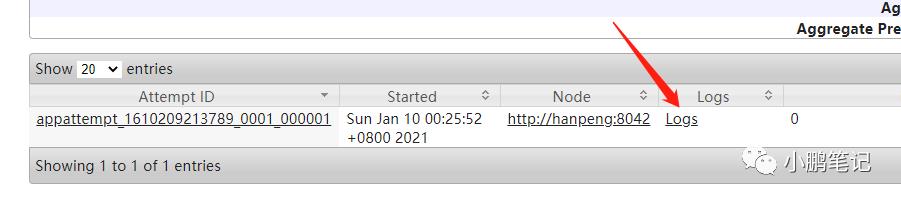
点击 Logs
在此处可以查看到运行的结果了
05
—
小结
本片单机版spark3.0.0的安装以及与yarn的整合已经完全整合好了,接下来可以把hadoop和spark的环境变量配置一下,方便接下来使用命令提交任务。
现阶段安装的spark的任务,在运行后无法查看spark的历史任务的详情,下一篇我们将配置spark的historyserver和yarn的jobhistory,方便查看提交的spark任务详情。
以上是关于spark 3.0.0 单机搭建的主要内容,如果未能解决你的问题,请参考以下文章