Spark 的 Failover 机制全解析 (Master/Worker/Executor)
Posted 数据社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 的 Failover 机制全解析 (Master/Worker/Executor)相关的知识,希望对你有一定的参考价值。
后台回复【加群】,申请加入数据学习交流群
所谓容错是指一个系统的部分出现错误的情况还能够持续地提供服务,不会因为一些细微的错误导致系统性能严重下降或者出现系统瘫痪。在一个集群出现机器故障、网络问题等是常 态,尤其集群达到较大规模后,很可能较频繁出现机器故障不能进行提供服务,因此对于分布式集群需要进行容错设计。Spark在设计之初考虑到这种情况,所以它能够实现高容错,以下将从ExecutorWorker和Master的异常处理来介绍。
checkForWorkerTimeOutTask = forwardMessageThread. scheduleAtFixedRate (new Runnable {
override def run (): Unit = Utils.tryLogNonFatalError (
//非自身发送消息CheckForWorkerTimeOut,调用timeOutDeadWorkers方法进行检测
self.send(CheckForWorkerTimeOut)
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
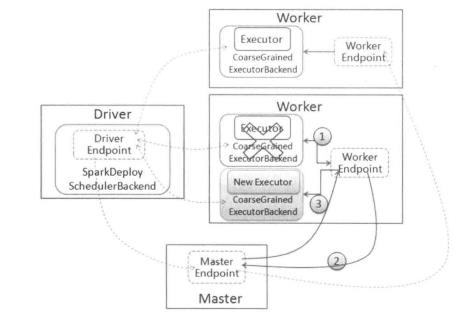
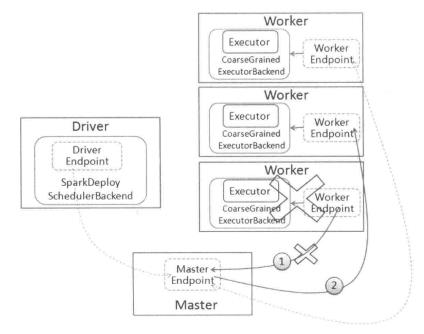
如果是 Executor, Master 先把该 Worker 上运行的 Executor 发送消息 ExecutorUpdated 给对应的 Driver,告知 Executor 已经丢失,同时把这些 Executor 从其应用程序运行列表中删除。另外,相关Executor的异常也需要按照前一小节进行处理。
如果是Driver,则判断是否设置重新启动。如果需要,则调用Master.schedule方法进行调度,分配合适节点重启Driver;如果不需要重启,则删除该应用程序。
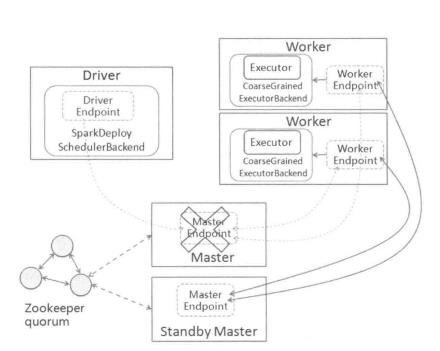
ZOOKEEPER:集群的元数据持久化到ZooKeeper中,当Master出现异常时.ZooKeeper 会通过选举机制选举出新的Master,新的Master接管时需要从ZooKeeper获取持久化 信息并根据这些信息恢复集群状态。具体结构如图4-13所示。
FILESYSTEM:集群的元数据持久化到本地文件系统中,当Master出现异常时,只要 在该机器上重新启动Master,启动后新的Master获取持久化信息并根据这些信息恢复 集群状态。
CUSTOM:自定义恢复方式,对StandaloneRecoveryModeFactory抽象类进行实现并把 该类配置到系统中,当Master出现异常时,会根据用户自定义的方式进行恢复集群状 态。
NONE:不持久化集群的元数据,当Master出现异常时,新启动的Master不进行恢复 集群状态,而是直接接管集群。
参考资料(侵删):
Apache Spark 官方文档 https://spark.apache.org/docs/latest
图解 Spark 核心技术与案例实战
(备注:行业-职位-城市)
01. 后台回复「数据」,即可领取大数据经典资料。
02. 后台回复「转型」,即可传统数据仓库转型大数据必学资料。
03. 后台回复「加群」,或添加一哥微信ID:dataclub_bigdata 拉您入群(大数据|数仓|分析)或领取资料。
!关注不迷路~ 各种福利、资源定期分享!
以上是关于Spark 的 Failover 机制全解析 (Master/Worker/Executor)的主要内容,如果未能解决你的问题,请参考以下文章
Apche Kafka 的生与死 – failover 机制详解
[Spark內核] 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密Broadcast源码解析Broadcast最佳实践