Spark变量/文件共享方式
Posted BAT笔试面试
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark变量/文件共享方式相关的知识,希望对你有一定的参考价值。
分布式计算场景下不可避免的会遇到变量/文件在多个计算节点之间的共享。
共享的作用:
(1)减少网络传输:通过共享,同一个节点只需拷贝传输一份数据
(2)减少内存消耗:通过共享,同一个节点上的多个task使用同一份数据,无需拷贝多个副本
spark中包括以下几种共享方式:
1、普通变量共享
以下代码中,“share_variable” 变量会拷贝到每个计算节点上的每个task中,即:当一个Executor中同时运行了多个task时,这个变量会存在多个副本,task之间不进行共享,当数据量较大时,内存消耗较大。
# encoding utf-8from pyspark import SparkConf, SparkContext, SparkFilesconf = SparkConf().setAppName('share-test').setMaster('local[4]')sc = SparkContext()# driver中执行的代码share_variable = 0.5# executor中执行的代码def handle(x):# 通过普通共享方式,获取driver中的变量return x * share_variablesc.parallelize(range(10), 2).map(lambda x: handle(x)).foreach(lambda x: print(x))sc.stop()
# encoding utf-8from pyspark import SparkConf, SparkContext, SparkFilesconf = SparkConf().setAppName('broadcast-test').setMaster('local[4]')sc = SparkContext()# driver中执行的代码:定义广播变量bc_variable = sc.broadcast({'item': 'food', 'price': 5})# executor中执行的代码def handle(x):# 获取广播变量的值share_variable = bc_variable.value# 通过普通共享方式,获取driver中的变量return x * share_variable['price']sc.parallelize(range(10), 2).map(lambda x: handle(x)).foreach(lambda x: print(x))sc.stop()
3、累加器(Accumulator)
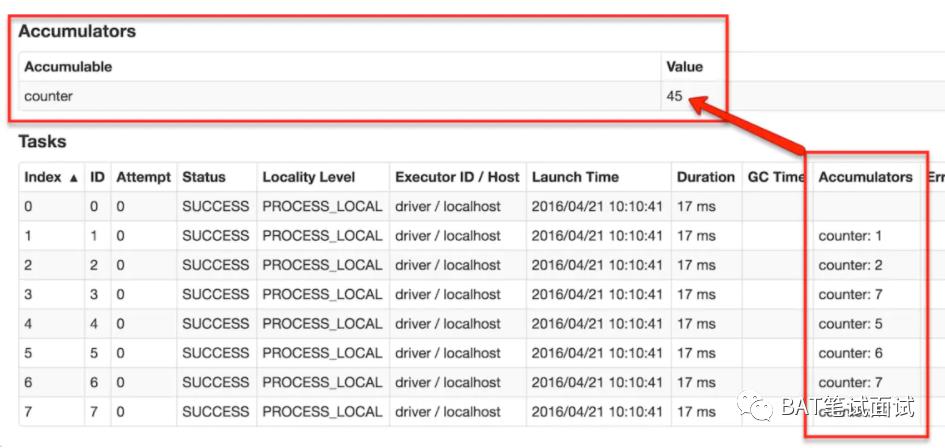
(图片来自https://www.jianshu.com/p/9a32123af0a6)
# encoding utf-8from pyspark import SparkConf, SparkContext, SparkFilesconf = SparkConf().setAppName('broadcast-test').setMaster('local[4]')sc = SparkContext()# driver中执行的代码:定义累加器acc=sc.accumulator(0)# executor中执行的代码def handle(x):# 累加器进行add操作acc.add(1)return xsc.parallelize(range(10), 2).map(lambda x: handle(x)).foreach(lambda x: print(x))sc.stop()
4、文件共享
# encoding utf-8from pyspark import SparkConf, SparkContext, SparkFilesconf = SparkConf().setAppName('broadcast-test').setMaster('local[4]')sc = SparkContext()# driver中执行的代码:共享文件sc.addFile("hdfs://path/to/file.txt" )# executor中执行的代码def handle(x):# 读取文件share_file = SparkFiles.get('file.txt')with open(share_file,'r') as f:print(f.read())return xsc.parallelize(range(10), 2).map(lambda x: handle(x)).foreach(lambda x: print(x))sc.stop()
# encoding utf-8import subprocessfrom pyspark import SparkConf, SparkContext, SparkFilesconf = SparkConf().setAppName('broadcast-test').setMaster('local[4]')sc = SparkContext()# executor中执行的代码def handle(x):# 从hdfs拉取数据subprocess.call("hdfs dfs -get /path/to/file.txt ", shell=True)with open('/path/to/file.txt', 'r') as f:print(f.read())return xsc.parallelize(range(10), 2).map(lambda x: handle(x)).foreach(lambda x: print(x))sc.stop()
推荐阅读
加小编微信(备注:大数据)
拉你入“大数据学习交流群”
以上是关于Spark变量/文件共享方式的主要内容,如果未能解决你的问题,请参考以下文章